本文主要是介绍机器翻译后的美赛论文怎么润色,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
美赛论文的语言表达一直是组委会看重的点,清晰的思路和地道的语言在评审中是重要的加分项。
今天我们就来讲讲美赛论文的语言问题。
我相信有相当一部分队伍在打美赛的时候,出于效率的考量,都会选择先写中文论文,再机翻成英文。
但是这么做是有风险的:
-
翻译质量的不稳定:机器翻译往往不能准确地捕捉原文的意思,特别是对于那些比较复杂的学术概念和专业术语,机器翻译可能会对文本内容本身产生误解或者转化成不正确的表达。
-
语法和句子结构的差异:中文和英文在语法和句子结构上有很大差异。最明显的:中文喜欢把所有定语放在前面,而英文中喜欢把较长的定语作为定语从句放在后面。机器翻译可能无法很好地处理这些差异,导致生成的英文句子杂乱无章。
同时在实践中我们发现,机器翻译喜欢把中文里比较短的几句话合并成一句很复杂的英文语段,不仅容易造成句意传达的谬误,还会使阅读理解论文意思增加难度。 -
与学术写作风格的差距:机器翻译往往只是单纯地逐字逐句翻译中文文本,并无法提供符合学术标准的翻译。
所以,在机翻过文本之后,我们可以通过以下几种方式来提高英文文本的质量:
-
仔细校对和修改:这一步主要是去检查有没有明显的语义翻译错误,例如句子之间的逻辑顺序,专业术语的翻译。
-
人工校对:找一个擅长英文的人再次校对机器翻译的内容,例如切割长语句,更改句中主谓宾的位置使其更符合英语阅读习惯,同时确保语言的准确性和自然性。
-
语言润色:将文本中未达到英语学术写作的语段和用词斟酌修改。
常见的日常用语和学术写作的替换可以参考下面的表格:
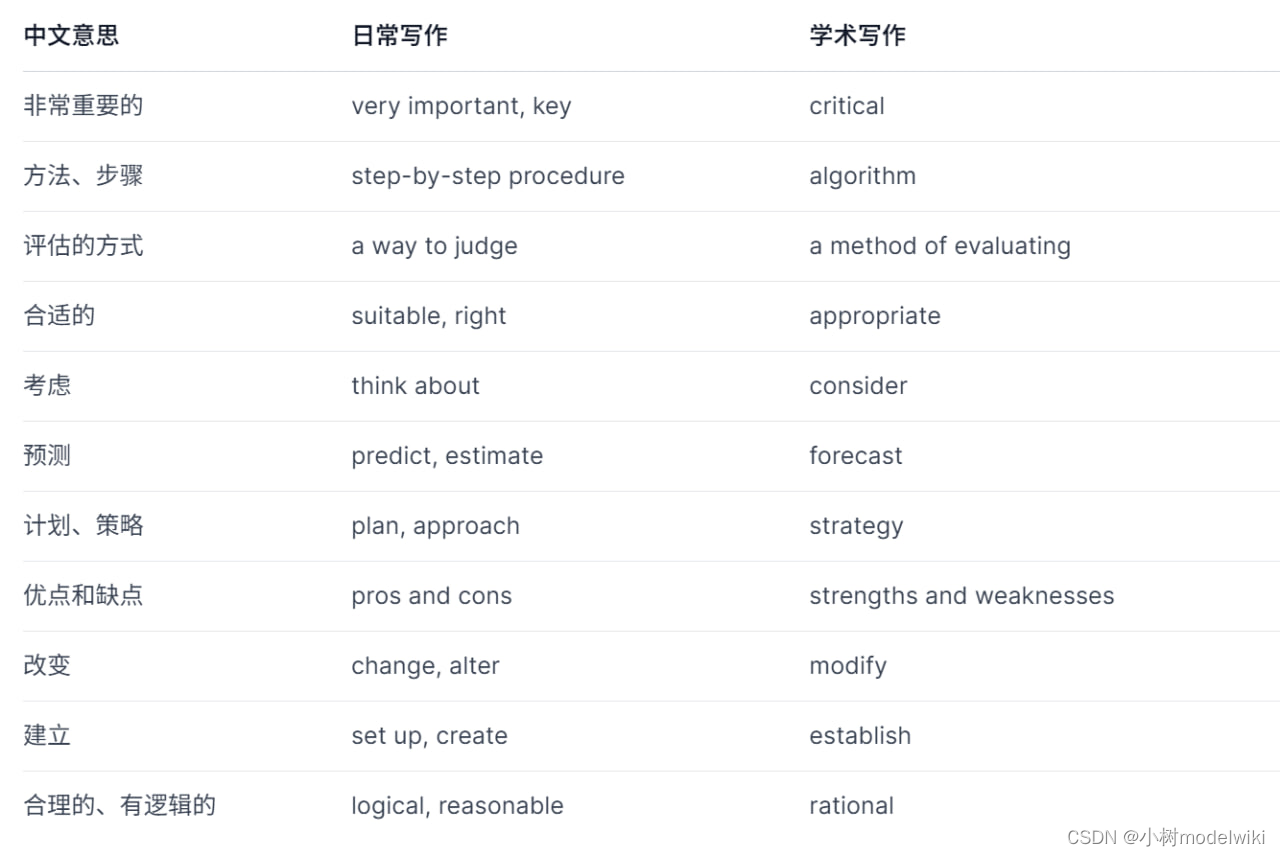

接下来我们用实例来为大家一步步讲解分析润色应该怎么做。
以下文本均来自于某比赛中某一支队伍的摘要。
润色实例1
这是摘要第一段的中文版:
本文对于全球变暖的研究问题,运用ARIMA时间序列预测模型、LSTM预测模型、BP神经网络、Chow Test检验、逐步回归等方法,首先对全球变暖的趋势进行了判断与预测,其次对于影响全球温度的因素进行了探讨,最后结合分析结果对如何抑制全球变暖的趋势给出建议。
这是用某具有权威性的翻译软件的翻译结果:
In this paper, for the research problem of global warming, ARIMA time series prediction model, LSTM prediction model, BP neural network, Chow Test test, stepwise regression, and other methods are used, firstly, the trend of global warming is judged and predicted, and secondly, the factors affecting the global temperature are explored, and finally, the results of the analysis are combined with the advice on how to inhibit the trend of global warming.
让我们逐字逐句看看这里面的问题。
-
句子冗长:这段话通篇只有一个句号,并且包含了很多内容,从研究问题的主题,到运用的方法,再到逐步的实现过程。读中文版的时候,觉得逻辑通畅。但是读到英文版,就有种一口气喘不过来的感觉。
-
连接词的使用:句子中使用了firstly,secondly,finally来组织内容,虽然在学术写作中是可以接受的,但是使用得太过紧密,也会给人一些奇怪的感觉。
-
内容本身:这是摘要的第一段,我们需要确保ARIMA和LSTM这些模型需要在第一次出现时给出全称,而不是缩写。
因为美赛中允许使用人工智能辅助,所以接下来我们用ChatGPT来试着润色一下这段文本:
This paper addresses the research problem of global warming by employing various methods, including ARIMA time series prediction model, LSTM prediction model, BP neural network, Chow test, and stepwise regression. Firstly, the paper aims to assess and forecast the trend of global warming. Secondly, it seeks to investigate the factors influencing global temperature. Finally, the analysis results are combined with recommendations on mitigating the trend of global warming. The choice of these methods is based on their suitability and relevance to the research problem. The research design is supported by established literature in the field (cite relevant sources).
让我们再来逐字逐句看一下这里的问题:
-
the research problem of … 这个短语并不常用,GPT没有发现。
-
ARIMA、LSTM这些缩写GPT并没有管,因为它只能在这个语段中找出问题,并不能把它放在一个论文的语境里,也并不知道这是论文摘要的第一段。
-
同样的问题,连接词的使用,Firstly,Secondly过于紧密。这其实也是GPT在生成文本时的通病,很喜欢给文本加上并不必要的逻辑连接词,这里因为本来文本里就有,所以润色时也没有太大的改动。
-
最后“自作主张”加了两句并不需要的解释,反而会显得论文在说大空话。
这是由我们团队GRE写作5.0(排名在全球GRE考生中占前10%)的学姐润色修改的结果:
In this paper, we address the issue of global warming by employing several analytical methods, including the ARIMA time series prediction model, the Long Short-Term Memory (LSTM) prediction model, the Back Propagation (BP) neural network, the Chow Test for structural analysis, and stepwise regression. Our objectives are threefold: to assess and forecast the trend of global warming, to investigate the factors influencing global temperatures, and to provide recommendations based on our findings for mitigating the warming trend.
没有用到复杂的单词和词组,只是把文本的内容和逻辑用一种更地道、简练、清晰的方式表达出来,这也是英语学术写作最重要的地方。
润色实例二
中文:
为预测未来全球温度水平,本文使用Python软件建立能提取线性特征的ARIMA时间序列预测模型与能提取非线性特征的LSTM模型,通过对各年份的全球温度对未来进行预测,得出全球温度水平保持波动上升趋势的结论,并预测出全球气温分别在2146年和2169年达到20(摄氏度)。
机器翻译:
In order to predict the global temperature level in the future, this paper uses Python software to establish ARIMA time series prediction model that can extract linear features and LSTM model that can extract nonlinear features, and forecasts the future through the global temperature of each year, and concludes that the global temperature level maintains a fluctuating upward trend, and predicts that the global temperature will reach 20 (degrees Celsius) in the years 2146 and 2169, respectively.
当我把文本粘贴到编辑器里时,Grammarly已经开始给这段文字疯狂划红线了,即使是机器翻译,我们也要认真查看是否存在语法问题。
这段语句的问题如下:
-
In order to这个短语其实替换成to就可以,没必要在这种地方体现语言的复杂度。
-
the global temperature level只是单纯地逐字逐句翻译中文,但是在英文语境下看得很奇怪意思也比较模糊,改为global temperature trend更明确一些。
-
在英语中,目的这种补充性的内容最好放在一句话的末尾。
-
Python software这个短语显得不太专业,改成the Python programming language比较好。
-
establish这个词,会给人一种这个模型是自己创造搭建的感觉,这和论文实际做的工作不符,换成employ或者develop比较合适。
-
extract换成capture更恰当一点,意为模型捕获了这样的特征。
基于以上问题,该文本的润色结果如下:
This paper employs the Python programming language to develop an ARIMA model, which captures linear features, and an LSTM model for non-linear patterns, to forecast global temperature trends. The analysis of annual temperature data indicates a fluctuating upward trend in global temperatures. The models predict that the global average temperature will reach 20 degrees Celsius in the years 2146 and 2169, respectively.
润色实例三
中文:
为解决经度与全球温度线性相关性低的问题,本文使用Python软件建立BP神经网络来提取非线性特征,得出经度会改变地理位置(高原、沿海等)从而影响全球温度的结论。
机器翻译:
To solve the problem of low linear correlation between longitude and global temperature, this paper uses Python software to build a BP neural network to extract nonlinear features, and concludes that longitude changes geographic location (plateau, coast, etc.) and thus affects global temperature.
这个语段的问题如下:
-
在中文中,相关性低和相关性弱是一个意思,但是在英文中描述相关性一般不用low而用weak。
-
这里用concludes that可能不够准确,用分析或者发现会更合适。
-
longitude changes geographic location这个表述会让人误解(其实中文就已经让人误解了),我们可以说地理状况会随着经度变化,但是不能说经度会改变地理状况。
-
geographic location (plateau, coast, etc.) 中括号及其内容很不严谨,不符合学术规范。
基于以上问题,该文本的润色结果如下:
We address the issue of the weak linear correlation between longitude and global temperature by employing a BP neural network in the Python programming environment, to identify nonlinear relationships. The analysis suggests that longitude is associated with varying geographic features, such as plateaus and coastlines, which may influence global temperature patterns.
最后我想说,学术英语写作的根本要义是,把你的研究内容和结果以一种清晰的、明确的、简洁的、严谨的、不带任何歧义的方式表达出来。
不需要用华丽的词语也不需要用复杂的句式。
以上就是针对如何润色机器翻译的论文文本的实例讲解,希望对各位论文手有所启发。
如果你在论文写作中遇到了问题,也欢迎和我交流。
这篇关于机器翻译后的美赛论文怎么润色的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









