本文主要是介绍论文笔记:YOLOv2,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者认为,目标检测框架变得愈发快速和准确,然而都局限于一个小的目标集。而与分类和标记等其他任务的数据集相比,当前目标检测数据集显得相对有限。因此,想要检测可以与目标分类的级别规模相当,而提出了一种新方法来利用已经拥有的大量分类数据,并使用它来扩大当前检测系统的范围。该方法使用目标分类的层次视图,允许不同的数据集合在一起。同时提出联合训练算法,可以在检测数据和分类数据上训练目标检测器。
通过这种方法训练YOLO9000,一个可以检测超过9000不同的目标类别的实时目标检测器。作者通过改进YOLO产生YOLOv2,然后训练来自ImageNet和COCO的超过9000个类的模型产生YOLO9000。
对于YOLOv2与YOLO 的对比,作者提出了三个特点:better,faster,stronger。论文中也分为这三个特点分别进行阐述。
better方面:
YOLO于Faster RCNN相比存在大量的定位误差。与基于候选区域的方法相比,YOLO存在着较低的recall。因此作者提出在保持classification accuracy的同时提升recall和localization。
Batch Normalization:
首先对网络中每一层添加batch normalization。这样网络就不需要每层学习数据的分布,从而加速收敛,提升了2%的mAP。BN还有助于规范化模型,这样在不会过拟合的情况下可以舍弃dropout。(对于为什么加入了BN就可以舍弃dropout见下图)

High Resolution Classifier:
由于于训练一般都是在ImageNet上完成(输入图片为224*224),而YOLOv1在训练分类网络时采用224*224作为输入,在detection的时候采用448*448。这意味着网络在切换到检测模型的时候还要同时使应新的分辨率。在这里做了改进,在预训练过程中在ImageNet上用10个epoch以448*448的分辨率调整分类网络,最后在检测数据集上fine tune。实验表明可以增加4%的mAP。
这里所谓分类模型和检测模型的转换,分辨率的转换见cfg文件:

Convolutional With Anchor Box:
YOLOv1在卷积特征提取器的顶层直接用全连接层预测bounding box的坐标。Faster RCNN中,没有直接预测坐标,而是使用hand-picked prior预测坐标。通过使用卷积层,Faster RCNN中的RPN为anchor box预测offset和confidence。由于预测层是卷积的,而RPN在网络的每一处预测offset。预测offset而不是坐标简化了问题,并使得网络更容易学习。
YOLOv2则采用了这种思想,引入anchor。首先去除卷积层和最后一层池化层,使得卷积神经网络的输出拥有更高的分辨率。同时缩减网络,用416*416的输入图片取代原来的448*448。这样做是使得特征图有奇数大小的宽和高,如此便可有一个cell作为中心cell。作者发现大的物体更趋向于占据图片的中心,因此用一个的cell而不是4个cell来表示图片的中心更好。YOLOv2以32为因子进行下采样,因此得到的输出是13*13(416/32)。
由于引入了anchor,YOLOv2减弱了空间位置分类预测机制,转而对每一个anchor预测class和objectness。与YOLOv1类似,objectness预测ground truth和proposed box的IOU,class预测已有一个object情况下各分类的条件概率。对于S*S的图像,YOLOv1中每个cell预测B个bounding box,C个类别概率(注意此处C与cell对应),则输出维度S*S*(B*5+C)。而YOLOv2中,C与anchor box对应,所以输出维度S*S*B*(C+5)。
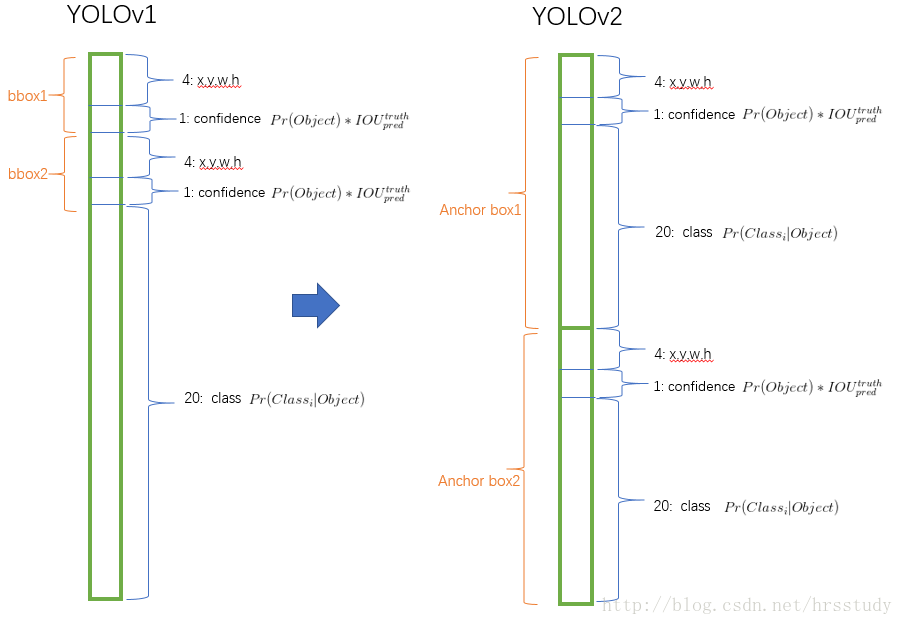
通过引入anchor,每张图预测上千box,而YOLOv1每张图只预测98个box。相比之前准确率有小幅度下降(mAP:69.5%-69.2%)recall却有大幅度上升(81%-88%)。作者认为recall的上升说明该模型有更多提升的空间。
Dimension Clusters:
作者在使用anchor时遇到了两个问题。首先,box的维度是人工制定的,也就是说如果定的好,网络将更容易学习。因此在训练集的bounding box上使用kmeans算法来自动寻找好的prior。因为使用欧几里得距离的话,大的box比小box会产
这篇关于论文笔记:YOLOv2的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






