本文主要是介绍阶段三-01 加入redis的获取和校验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于redis
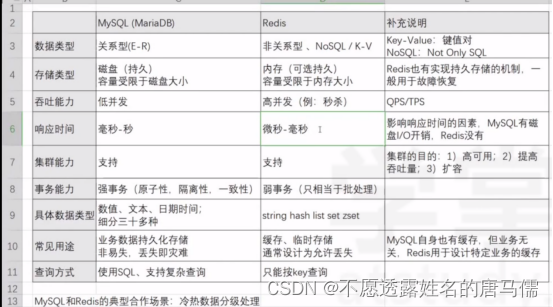
在 pypi 里搜索 redis,之后访问包的官方页面,https://github.com/redis/redis-py>>> import redis>>> r = redis.Redis(host='localhost', port=6379, db=0)>>> r.set('foo', 'bar')True>>> r.get('foo')b'bar'现目前最大的需求是获取验证码之后自动放在接口传参。
redis的设计:

我们衡量以后选第一种,只用在 apidef molde 中加上几个字段。(第二种比较麻烦,需建多mold、表单、模版)
所以我们把他放在接口定义里面来设计
在系统里先添加环境:

接下来按照业务要求
到2我们卡住了,业务model没有定义相关字段。
在apidef 中加入字段
先给一个模式选择,让用户可以选http亦或是redis 或mysql
加一个字段展示
class ApiDef(models.Model):API_PROTOCOL = [('http', 'HTTP'),('redis', 'Redis'),('mysql', 'MySQL'),]# 协议类型 fixme 根据协议判断必填项protocol = models.CharField(max_length=8, verbose_name='协议', choices=API_PROTOCOL)然后之前apidef 的字段都是必填,我们改为非必填
之后改下admin页面,ApiDefAdmin里加上 protocol的展示

现在还没法运行,但是我们已经定义好了,就等方法调用了。
run方法的运行
新建一个redis_py,参照 http的perform_api 略修改
代码如下:
import time
import traceback
from datetime import datetime
import logging
import redis
from test_plt.models import ApiRunlog, ApiDefdef perform_api(api: ApiDef, redis_key, user, case_log=None):logger = logging.getLogger('test_plt')# 记录执行时间start_at = time.time()runlog = ApiRunlog()runlog.api = apirunlog.start_at = datetime.fromtimestamp(start_at)runlog.redis_key = redis_keyrunlog.created_by = userrunlog.case_run_log = case_logtry:conn = redis.Redis(host=api.deploy_env.hostname,port=api.deploy_env.prot,db=api.db_name,password=api.db_password,decode_responses=True)values = conn.get(redis_key)runlog.success = Truerunlog.response_body = valueslogger.info(f'[{runlog.api}] 接口执行成功')except Exception as e:trace_msg = traceback.format_exc()runlog.success = Falserunlog.error_msg = f'{e}\n{trace_msg}'logger.info(f'[{runlog.api}] 执行失败: {runlog.error_msg}')finally:# 记录结束时间finish_at = time.time()runlog.finish_at = datetime.fromtimestamp(finish_at)# 接口执行耗时runlog.duration_at = (finish_at - start_at) * 1000runlog.save()return {'runlog_id': runlog.id,'values': runlog.response_body,'headers': runlog.response_headers,'duration': runlog.duration_at,'success': runlog.success}
之后common的 perform_case方法里加入ridis分支调用:
try:if api.protocol == 'http':resp.check_case_apidef(item, result)elif api.protocol == 'redis':resp.check_case_redis(item, result)logger.info(f'[{api}] 校验成功')在页面上试试,能成功获取了
mold中的 claen
之前根据协议判断页面的字段是否必填,就要在类里重写 claen
从模型创建表单 | Django 文档 | Django
在molde 的ApiDef里加一个方法;
def clean(self):errors = {}if self.protocol != 'http':returnif not self.http_schema:errors['http_schema'] = ValidationError('', code='required')if not self.http_method:errors['http_method'] = ValidationError('', code='required')if not self.uri:errors['uri'] = ValidationError('', code='required')if not self.auth_type:errors['auth_type'] = ValidationError('', code='required')if not self.body_type:errors['body_type'] = ValidationError('', code='required')if len(errors) > 0:raise ValidationError(errors)代码解释:
给一个装错误的空字典,再判断这个mold的protocol是否不等于http,是就直接不处理结束方法(意思就是那些字段可以为空)。
否就进入以下判断,如果 http_schema为空,则向errors字典里加入键值对。最后统一判断有0个以上的问题就让页面抛错误。
ValidationError 允许我们嵌套 子ValidationError 之后统一抛出
表单和字段验证 | Django 文档 | Django
这样在相应的字段上就会有我们定义的错误提示了
form.py表单中 RunApiForm 类里也加一个方法,用来校验 redis_key 有没有填
def clean_redis_key(self):api = self.get_apidef()if api.protocol == 'redis' and not self.cleaned_data.get('redis_key'):raise ValidationError("请输入Redis的Key")return self.cleaned_data.get('redis_key')顺便做一下优化,现在两个 clean_xxx 中都有判断 selectaction的。我们干脆合成一个方法后直接调用即可:
def get_apidef(self) -> ApiDef:api_id = ast.literal_eval(self.cleaned_data.get('_selected_action'))[0]return ApiDef.objects.get(id=api_id)
指示调用可以定义返回值类型;把重复的替换成api = self.get_apidef()
redis的校验
我们现在想在用例里校验结果,我们需要在CaseApiDef mold中加字段 redis_key ,定义了以后在admin里加上,方便展示
接下来做校验的判断,我们要考虑不同模式下不同的校验,比如 http、redis、mysql。他们中通用的校验我们把他抽象出来复用。
这就设计到两种思路:
- 设计一个主类和三个子类,通用的代码可以继承
- 复用的设计成函数,复用的时候调用。
这里选的第二种,业务不会设计到太多模块的加入了就http、redis、mysql,第二种够用了。
现在就来开始改造 resp.py
把响应时间、应答体、正则、python脚本校验都单独拆成方法,需要的时候直接调用
def check_duration(item: CaseApiDef, duration):# 响应时间校验,用的是毫秒duration = duration / 1000if item.response_time and item.response_time <= duration:raise RespCheckException('响应时间', f'预期【{item.response_time}】;实际【{duration}】')def check_json_schema(item: CaseApiDef, text):# 应答体json schema校验 用三方包 json-schemaif item.json_verify:try:validate(instance=json.loads(text), schema=json.loads(item.json_verify))except SchemaError as e:raise RespCheckException('json-schema', f'您输入json-schema包含错误;参考【{e}】')except ValidationError as e:raise RespCheckException('json-schema', f'接口返回的应答体不符合json-schema要求;参考【{e}】')except Exception as e:raise RespCheckException('json-schema', f'发生了非预期错误;参考【{e}】')def check_regex(item: CaseApiDef, text):# 应答体正则校验if item.regex_verify and not re.search(item.regex_verify, text):raise RespCheckException('应答正则表达式', f'预期【{item.regex_verify}】;实际【{text}】')def check_expression(item: CaseApiDef, result):# 应答体python脚本校验 利用python eval()函数 注意规避安全漏洞if item.python_verify:# 约定输入格式 #{}m = re.match(r"#\{.+\}", item.python_verify)if not m:raise RespCheckException('应答体python脚本校验', f'内容格式不支持,请使用#{{}}包含[{item.python_verify}]')exp = m.group()if re.search(r"__.+__", item.python_verify): # __import__.os 等被过滤掉raise RespCheckException('应答体python脚本校验', f'python表达式包含非法字符或操作')# 约定可提供的数据 resultlocal_params = {'result': result,'re': re,'parse': common.parse_json_like}try:# 执行evaleval_ = eval(exp[2:-1], {}, local_params) # eval执行后会返回一个布尔值,[2:-1]做个切片去掉用户输入的#{}if not eval_:raise RespCheckException('应答体python脚本校验', f'表达式执行结果为【{eval_}】')except Exception as e:raise RespCheckException('应答体python脚本校验', f'表达式执行失败,请先修正后再执行用例。参考【{e}】')拆解后 check_case_apidef 只需要传参调用即可
def check_case_apidef(item: CaseApiDef, result: dict):# 是否校验 总开关if not item.verify:return True# 状态码校验if item.status_code and item.status_code != result.get('status_code'):raise RespCheckException('状态码', f'预期【{item.status_code}】;实际【{result.get("status_code")}】')# 响应时间校验check_duration(item, result.get('duration'))# HTTP响应头校验 可以将响应头转化为json字符串,再使用正则校验if item.header_verify and not re.search(item.header_verify, json.dumps(result.get('headers'))):raise RespCheckException('HTTP响应头', f'预期【{item.header_verify}】;实际【{result.get("headers")}】')# 应答体json schema校验check_json_schema(item, result.get('text'))# 应答体正则校验check_regex(item, result.get('text'))# 应答体python脚本校验check_expression(item, result)return True最后再写redis的校验就很方便了
def check_case_redis(item: CaseApiDef, result: dict):# 是否校验 总开关if not item.verify:return True# 响应时间校验check_duration(item, result.get('duration'))# 应答体json schema校验check_json_schema(item, result.get('values'))# 应答体正则校验check_regex(item, result.get('values'))# 应答体python脚本校验check_expression(item, result)return True这篇关于阶段三-01 加入redis的获取和校验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





