本文主要是介绍MUTAN readme文件(翻译),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
/!\ VQA的新版本PyTorch代码现已提供,链接在这里: 代码链接
这个仓库是由Remi Cadene(LIP6)和Hedi Ben-Younes(LIP6-Heuritech)创建的,他们是在UPMC-LIP6从事VQA研究的两名博士生,以及他们的导师Matthieu Cord(LIP6)和Nicolas Thome(LIP6-CNAM)。我们在一篇名为“MUTAN: Multimodal Tucker Fusion for VQA”的研究论文中开发了这个代码,据我们所知,它是VQA 1.0数据集上的当前最先进方法。
这个仓库的目标有两个:
1、更容易重现我们的结果。
2、为社区提供一个高效且模块化的代码基础,以便在其他VQA数据集上进行进一步的研究。
如果对我们的代码或模型有任何问题,请随时与我们联系或提交任何问题。欢迎提出Pull请求!
最新消息:
- 2018年1月16日: 添加了预训练的vqa2模型和Web演示。
- 2017年7月18日: 添加了VQA2、VisualGenome、FBResnet152(适用于PyTorch)的新版本提交消息。
- 2017年7月16日: 论文被ICCV2017接受。
- 2017年5月30日: 海报被CVPR2017(VQA Workshop)接受。
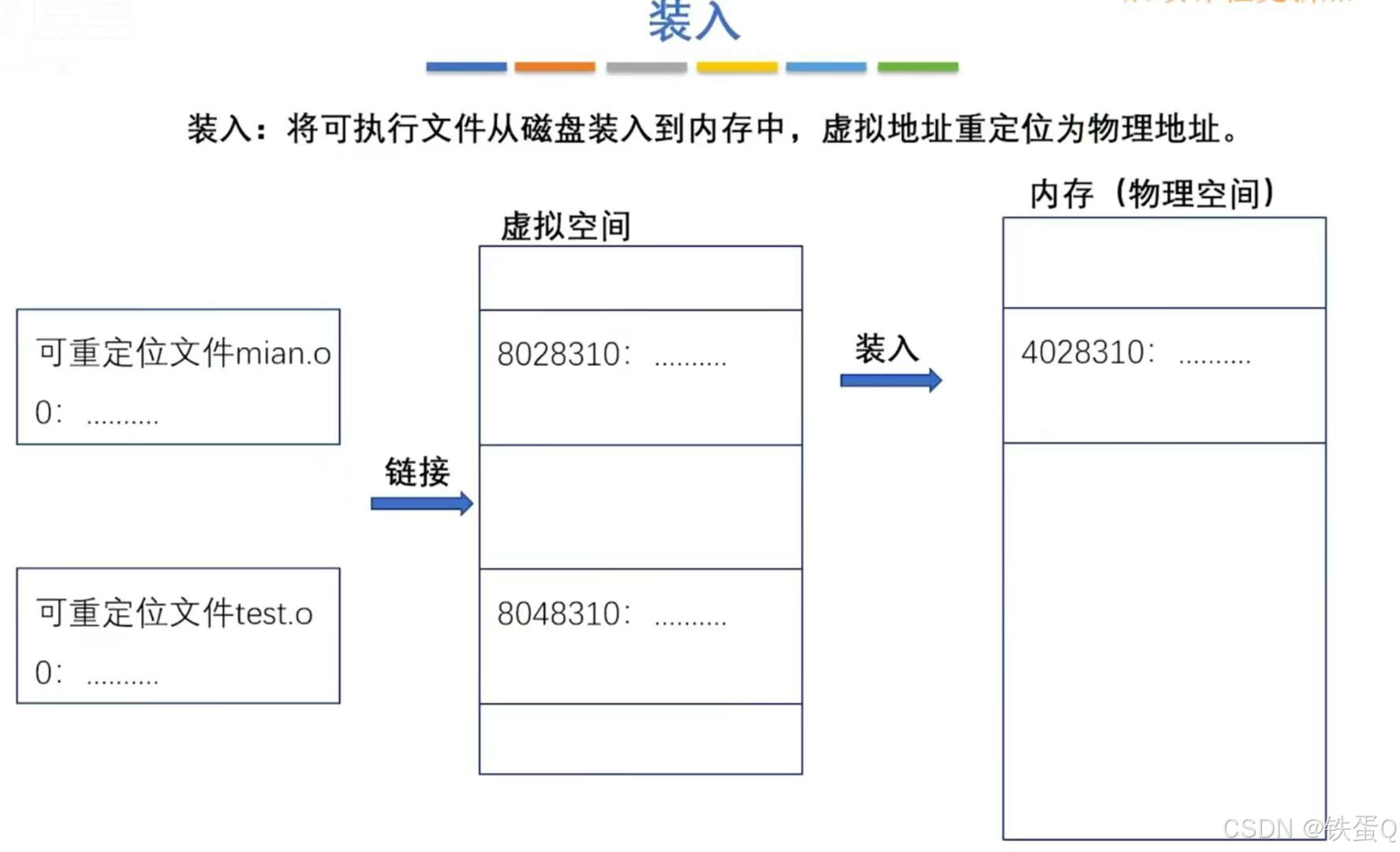
1、介绍
这个任务涉及在一个由三元组组成的多模态数据集上以端到端的方式训练模型:
1、一张图像,除了原始像素信息之外没有其他信息,
2、有关关联图像上视觉内容的问题,
3、对问题的简短回答(一个或几个词)。
正如您在下面的插图中所看到的,VQA数据集的两个不同的三元组(但相同的图像)被表示出来。模型需要学习丰富的多模态表示,以便能够给出正确的答案。

VQA任务仍然是活跃的研究领域。然而,当它被解决时,它可能对改进人机界面(尤其是对于视觉障碍者)非常有用。
关于我们方法的简要洞察
VQA社区发展了一种基于四个可学习组件的方法:
1、问题模型,可以是LSTM、GRU或预训练的Skipthoughts,
2、图像模型,可以是预训练的VGG16或ResNet-152,
3、融合方案,可以是逐元素求和、连接、MCB、MLB或Mutan,
4、可选的注意力方案,可能包含多个“窥视”。
我们的一个主张是,图像和问题表示之间的多模态融合是一个关键组件。因此,我们提出的模型使用相关张量的Tucker分解来建模更丰富的多模态交互,以提供正确的答案。我们的最佳模型基于以下组件:
1、针对问题的预训练Skipthoughts的问题模型,
2、针对图像的预训练Resnet-152(图像大小为3x448x448)的图像模型,
3、我们提出的Mutan(基于Tucker分解)作为融合方案,
4、具有两个“窥视”的注意力方案。
2、安装
2.1 Requirements
首先安装Python 3(我们不提供对Python 2的支持)。我们建议您使用Anaconda安装Python 3和PyTorch:
# 安装带有Anaconda的Python
# 安装带有CUDA的PyTorch
conda create --name vqa python=3
source activate vqa
conda install pytorch torchvision cuda80 -c soumith
然后克隆仓库(使用–recursive标志来克隆子模块),并安装附加要求:
cd $HOME
git clone --recursive https://github.com/Cadene/vqa.pytorch.git
cd vqa.pytorch
pip install -r requirements.txt
上述代码段的目的是在Python 3环境中安装PyTorch和其他必要的依赖项。首先,它创建了一个名为 “vqa” 的conda环境,并在其中安装了PyTorch和其他相关库。然后,它克隆了vqa.pytorch的GitHub仓库,并确保同时克隆了任何子模块(使用–recursive标志)。最后,它使用pip安装了在requirements.txt文件中指定的其他依赖项。
2.2子模块
我们的代码有两个外部依赖项:
1、VQA 用于在valset上使用开放式准确性评估结果文件,
2、skip-thoughts.torch 用于导入预训练的GRUs和嵌入,
3、pretrained-models.pytorch 用于加载预训练的卷积网络。
2.3 数据
数据将在需要时自动下载和预处理。数据的链接存储在vqa/datasets/vqa.py、vqa/datasets/coco.py和vqa/datasets/vgenome.py中。
3、在VQA 1.0上重现结果
3.1特征
由于我们最初使用Lua/Torch7开发,我们使用了在Torch7中预训练的ResNet-152的特征。我们在v2.0版本中将使用Torch7训练的预训练resnet152移植到了PyTorch中。我们将很快提供所有提取的特征。在此期间,您可以按照以下方式下载coco特征:
mkdir -p data/coco/extract/arch,fbresnet152torch
cd data/coco/extract/arch,fbresnet152torch
wget https://data.lip6.fr/coco/trainset.hdf5
wget https://data.lip6.fr/coco/trainset.txt
wget https://data.lip6.fr/coco/valset.hdf5
wget https://data.lip6.fr/coco/valset.txt
wget https://data.lip6.fr/coco/testset.hdf5
wget https://data.lip6.fr/coco/testset.txt
/!\ 目前有3个版本的ResNet152:
- fbresnet152torch 是torch7模型,
- fbresnet152 是torch7移植到pytorch中的模型,
- resnet152 是torchvision中预训练的模型(我们使用它的结果较差)。
3.2 预训练VQA模型
我们目前提供了三个使用我们旧的Torch7代码训练并转换到PyTorch的模型:
1、在VQA 1.0 trainset 上训练的 MutanNoAtt 模型,
2、在VQA 1.0 trainvalset 和 VisualGenome 上训练的 MLBAtt 模型,
3、在VQA 1.0 trainvalset 和 VisualGenome 上训练的 MutanAtt 模型。
mkdir -p logs/vqa
cd logs/vqa
wget http://webia.lip6.fr/~cadene/Downloads/vqa.pytorch/logs/vqa/mutan_noatt_train.zip
wget http://webia.lip6.fr/~cadene/Downloads/vqa.pytorch/logs/vqa/mlb_att_trainval.zip
wget http://webia.lip6.fr/~cadene/Downloads/vqa.pytorch/logs/vqa/mutan_att_trainval.zip
即使我们提供了与我们预训练模型相关的结果文件,您仍然可以使用单个命令在valset、testset和testdevset上重新评估它们:
python train.py -e --path_opt options/vqa/mutan_noatt_train.yaml --resume ckpt
python train.py -e --path_opt options/vqa/mlb_noatt_trainval.yaml --resume ckpt
python train.py -e --path_opt options/vqa/mutan_att_trainval.yaml --resume ckpt
要在VQA 1.0上获取test和testdev结果,您需要将结果的json文件压缩(命名为results.zip),然后提交到评估服务器。
4、重现在VQA 2.0上的结果
4.1 特征 2.0
你必须下载coco数据集(如果需要还有Visual Genome),然后使用卷积神经网络提取特征。
4.2 预训练VQA模型 2.0
我们目前提供了三个在VQA 2.0上使用我们当前pytorch代码训练的模型:
1、在trainset上使用fbresnet152特征训练的MutanAtt模型,
2、在trainvalset上使用fbresnet152特征训练的MutanAtt模型。
cd $VQAPYTORCH
mkdir -p logs/vqa2
cd logs/vqa2
wget http://data.lip6.fr/cadene/vqa.pytorch/vqa2/mutan_att_train.zip
wget http://data.lip6.fr/cadene/vqa.pytorch/vqa2/mutan_att_trainval.zip
5、文档
5.1架构
.
├── options # 默认选项目录,包含yaml文件
├── logs # 实验目录,包含实验日志目录(每个实验一个目录)
├── data # 数据集目录
| ├── coco # 图像和特征
| ├── vqa # 原始、临时和处理后的数据
| ├── vgenome # 原始、临时和处理后的数据 + 图像和特征
| └── ...
├── vqa # vqa包目录
| ├── datasets # 数据集类和函数目录(vqa、coco、vgenome、images、features等)
| ├── external # 子模块目录(VQA,skip-thoughts.torch,pretrained-models.pytorch)
| ├── lib # 杂类类和函数目录(engine、logger、dataloader等)
| └── models # 模型类和函数目录(att、fusion、notatt、seq2vec、convnets)
|
├── train.py # 训练和评估模型
├── eval_res.py # 使用OpenEnded指标评估结果文件
├── extract.py # 使用CNN从coco中提取特征
└── visu.py # 可视化日志和监视训练
5.2选项
有三种类型的选项:
1、存储在options目录中的yaml选项文件中的选项,用作默认选项(目录路径、日志、模型、特征等)。
2、在train.py文件中的ArgumentParser中的选项,设置为None,可以覆盖默认选项(学习率、批大小等)。
3、在train.py文件中的ArgumentParser中的选项,设置为默认值(打印频率、线程数、恢复模型、评估模型等)。
如果需要,您可以在自定义yaml文件中轻松添加新选项。此外,如果要对参数进行网格搜索,可以添加一个ArgumentParser选项并修改train.py:L80中的字典。
5.3 数据集
我们目前提供四个数据集:
1、COCOImages:用于提取特征,包含三个数据集:trainset、valset和testset
2、VisualGenomeImages:用于提取特征,包含一个划分:trainset
3、VQA 1.0:包含四个数据集:trainset、valset、testset(包括test-std和test-dev)和“trainvalset”(trainset和valset的连接)
4、VQA 2.0:相同的数据,但是是VQA 1.0的两倍
我们计划添加:
CLEVR
5.4 模型
我们目前提供四个模型:
1、MLBNoAtt:一个强基线(BayesianGRU + 逐元素乘积)
2、MLBAtt:先前的最先进方法,添加了一种注意策略
3、MutanNoAtt:我们的概念验证(BayesianGRU + Mutan融合)
4、MutanAtt:当前的最先进方法
我们计划在将来添加几种其他策略。
6、快速示例
6.1 从COCO提取特征
将所需的图像自动下载到dir_data,并默认使用resnet152提取特征。
有三种模式选择:
1、att:特征大小为2048x14x14,
2、noatt:特征大小为2048,
3、both:默认选项。
注意,你需要在SSD上有一些空间:
1、图像需要32GB,
2、训练特征需要125GB,
3、测试特征需要123GB,
4、验证特征需要61GB。
python extract.py -h
python extract.py --dir_data data/coco --data_split train
python extract.py --dir_data data/coco --data_split val
python extract.py --dir_data data/coco --data_split test
注意:默认情况下,我们的代码将在所有可用的GPU上共享计算。如果要选择一个或多个GPU,使用以下前缀:
CUDA_VISIBLE_DEVICES=0 python extract.py
CUDA_VISIBLE_DEVICES=1,2 python extract.py
6.2 从VisualGenome提取特征
同样,在这里,只有train可用:
python extract.py --dataset vgenome --dir_data data/vgenome --data_split train
6.3 在VQA 1.0上训练模型
显示帮助消息,选定的选项,并运行默认设置。将自动下载和处理所需的数据,使用options/vqa/default.yaml中的选项。
python train.py -h
python train.py --help_opt
python train.py
使用默认选项运行MutanNoAtt模型。
python train.py --path_opt options/vqa/mutan_noatt_train.yaml --dir_logs logs/vqa/mutan_noatt_train
在trainset上运行MutanAtt模型,并在每个epoch后在valset上评估。
python train.py --vqa_trainsplit train --path_opt options/vqa/mutan_att_trainval.yaml
在trainset和valset上(默认设置)运行MutanAtt模型,并在每个epoch后运行testset(生成一个结果文件,您可以提交到评估服务器)。
python train.py --vqa_trainsplit trainval --path_opt options/vqa/mutan_att_trainval.yaml
6.4 在VQA 2.0上训练模型
查看vqa2/mutan_att_trainval的选项:
python train.py --path_opt options/vqa2/mutan_att_trainval.yaml
6.5 在VQA(1.0或2.0)+ VisualGenome上训练模型
查看vqa2/mutan_att_trainval_vg的选项:
python train.py --path_opt options/vqa2/mutan_att_trainval_vg.yaml
6.6 监控训练
使用plotly创建一个实验的可视化,以监视训练,就像下面的图片一样(点击图像访问html/js文件):
请注意,必须等到第一个开放式准确性处理完成,然后将创建html文件并在默认浏览器中弹出。HTML文件将每60秒刷新一次。但是,您目前需要在浏览器上按F5键才能看到更改。
python visu.py --dir_logs logs/vqa/mutan_noatt
创建多个实验的可视化,以比较它们或监视它们,如下图所示(点击图像访问html/js文件):
python visu.py --dir_logs logs/vqa/mutan_noatt,logs/vqa/mutan_att
6.7 重新开始训练
从最后一个检查点重新启动模型。
python train.py --path_opt options/vqa/mutan_noatt.yaml --dir_logs logs/vqa/mutan_noatt --resume ckpt
从最佳检查点重新启动模型。
python train.py --path_opt options/vqa/mutan_noatt.yaml --dir_logs logs/vqa/mutan_noatt --resume best
6.8 在VQA上评估模型
评估从最佳检查点加载的模型。如果模型仅在训练集上训练(vqa_trainsplit=train),则将在valset上评估该模型,并在testset上运行。如果它在trainset + valset上训练(vqa_trainsplit=trainval),则不会在valset上评估。
python train.py --vqa_trainsplit train --path_opt options/vqa/mutan_att.yaml --dir_logs logs/vqa/mutan_att --resume best -e
6.9 Web演示
在demo_server.py的第169行设置本地IP地址和端口,并在demo_web/js/custom.js的第51行设置全局IP地址和端口。与全局IP地址关联的端口必须重定向到本地IP地址。
启动API:
CUDA_VISIBLE_DEVICES=0 python demo_server.py
在浏览器上打开demo_web/index.html,以使用人机界面访问API。
这篇关于MUTAN readme文件(翻译)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!