本文主要是介绍高效的跳表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
高效的跳表
- 一、 概念
- 二、 实现原理
- 三、存在的问题
- 四、解决方法
- 五、如何保证效率
- 六、代码实现
- 七、总结
- 对比平衡搜索树
- 对比哈希表
一、 概念
跳表,是一种用来查询数据的数据结构,它是由William Pugh发明的,借助有序链表,来实现高效地查询
二、 实现原理
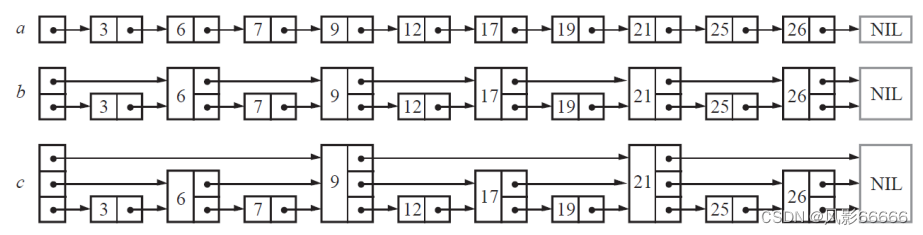
William Pugh的优化思路是,每相邻两个节点升高一层,增加一个指针,让指针指向下下个节点,依次类推,形成下图的c,每一层都能排除一半,类似于二分查找,时间复杂度为O(log n)
三、存在的问题
插入删除数据时,就会打乱上下相邻两层链表上节点个数严格的2:1的对应关系,而要维持这种对应关系,就必须把新插入的节点及其后面的所有节点重新进行调整,但这会让时间复制度退化为O(n)
四、解决方法
William Pugh为了解决这个问题,做了一个大胆的处理,不再严格要求这种对应比例关系,而是插入一个节点的时候,随机出一个层数,这样每次插入和删除都不再需要考虑其它节点的层数,实现起来也就简单多了
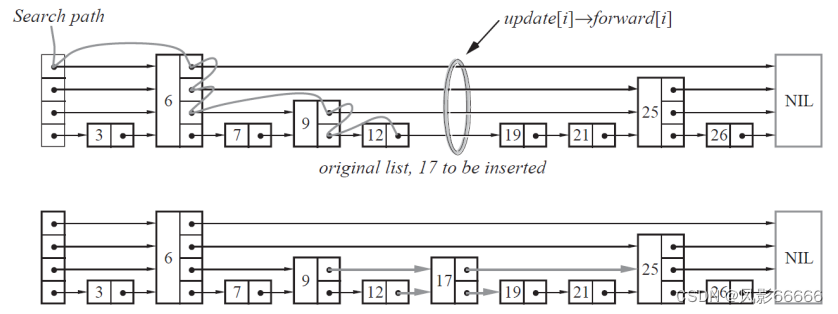
五、如何保证效率
一般跳表会设计一个最大层数maxLevel的限制,其次,会设置一个多增加一层的概率p,伪代码如下图
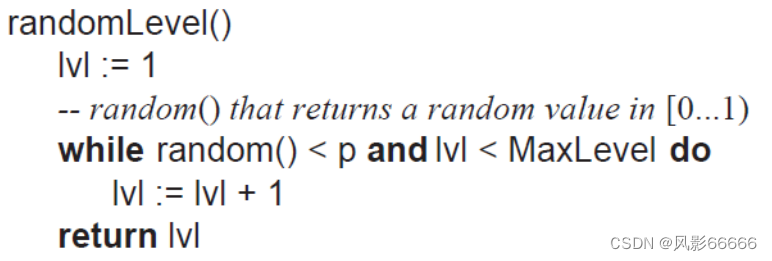
在Redis的skiplist实现中,p取1/4,maxLevel取32,根据前面的伪代码,定量分析如下图

一个节点的平均层数,计算如下图
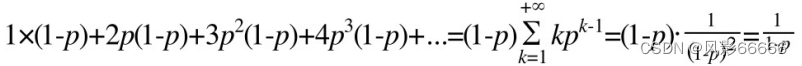
六、代码实现
首先,得定义一个节点结构体,一个节点由值和它的层数(下一个结点指针的集合)组成

跳表,则有三个成员,_head是一个哨兵节点,概率p和最大层数maxLevel给缺省值即可,同时,构造函数内,还需给一个随机数种子,后面用来获取节点层数


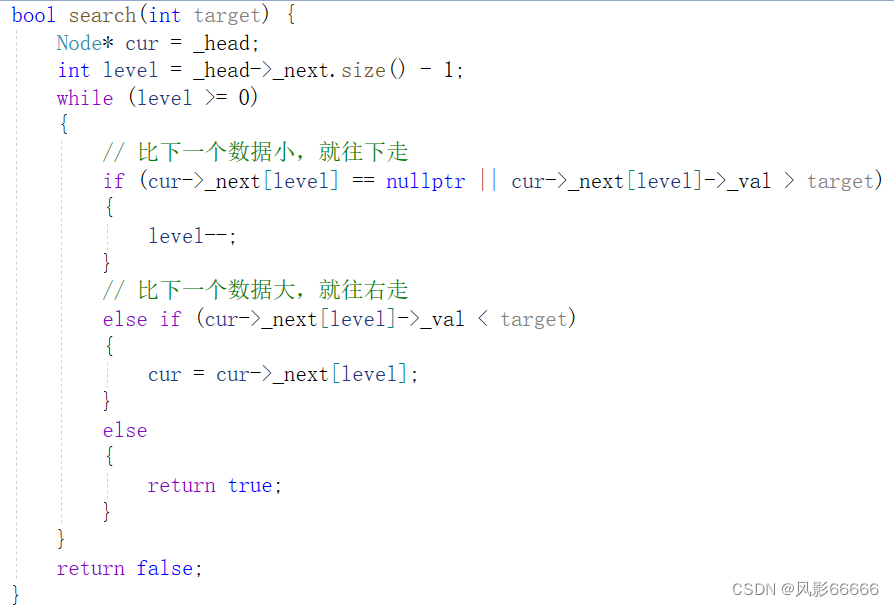
查找某个值,从上往下开始找,让当前节点指针指向哨兵节点,判断它的下一个节点值和目标值的大小关系,下一个节点值为空或比目标值大,就往下走,即层数下标-1;如果比目标值小,就往右走;否则,则表明找到了,直接返回true即可,如果层数下标都小于0了,就返回false,表明没有找到
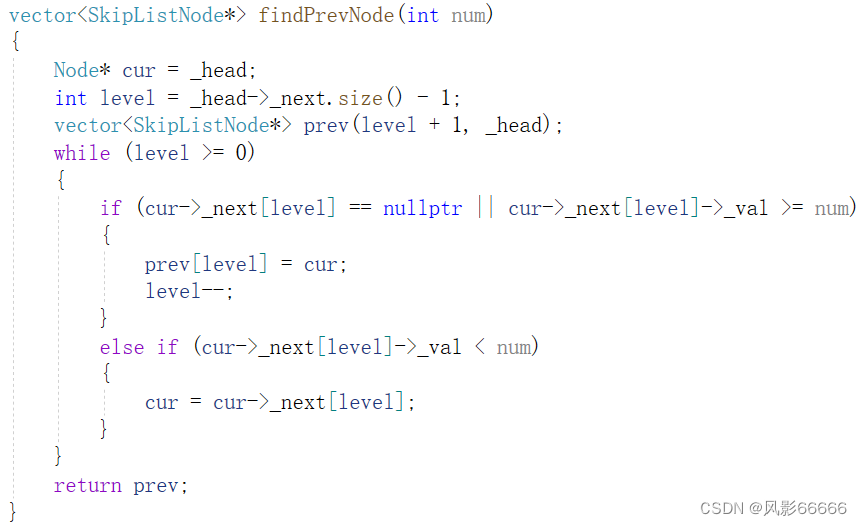
类似于单链表,跳表要插入一个节点或删除一个节点,就必须找到目标节点的前一个节点的集合,这样才能插入或者删除节点,例如,插入20,它的前一个节点集合,自上而下为_head,17,19,如下图

代码类似于查找目标值,不再赘述
获取节点层数

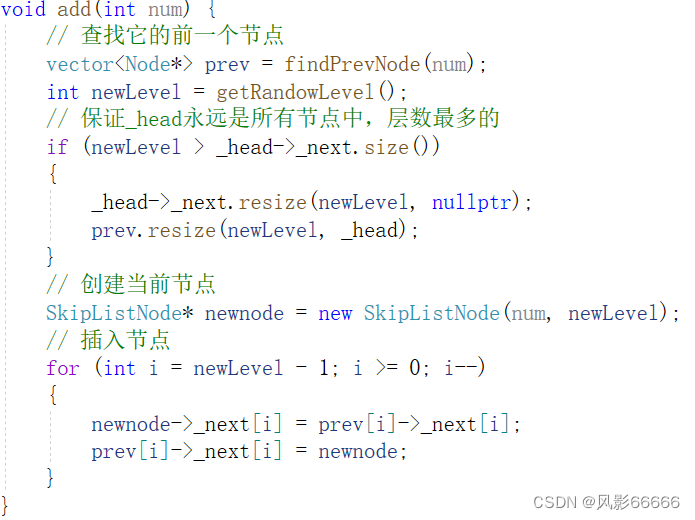
插入节点,首先,获取它的前一个节点的集合,其次,获取节点的层数,同时,需要保证_head节点的层数始终是所有节点中最多的,然后就是链表的插入操作了
删除节点,首先,得判断节点在不在,不在,就不需要删除了,直接返回即可,删除操作也就是链表的删除操作,最后,做一个层数更新,因为删除节点后,头节点的层数可能会有很多是不必要的,影响查找效率,所以做了一个小的优化

下面的一个leetcode题目,可以用来验证写的对不对
跳表
七、总结
对比平衡搜索树
对比AVL树和红黑树,都可以做到遍历数据有序,时间复杂度也差不多,而跳表的优势在于:
实现简单,容易控制,而平衡树增删改查都更复杂
跳表的额外空间消耗更低,平衡树节点需要存储三个节点指针,父亲和左右孩子,还有平衡因子或颜色等消耗
对比哈希表
相对于哈希表,优势小了很多,首先,哈希表查找数据的时间复杂度为O(1),比跳表快,跳表的优势在于:
遍历数据有序
跳表的空间消耗略小一些,哈希表存在链接指针和表空间消耗
哈希表扩容有性能损耗
哈希表在极端场景下,哈希冲突高,效率下降厉害,需要红黑树来弥补
这篇关于高效的跳表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





