本文主要是介绍解析Excel文件内容,按每列首行元素名打印出某个字符串的统计占比(超详细),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.示例:
开发需求:读取Excel文件,统计第3列到第5列中每列的"False"字段占比,统计第6列中的"Pass"字段占比,并按每列首行元素名打印出统计占比
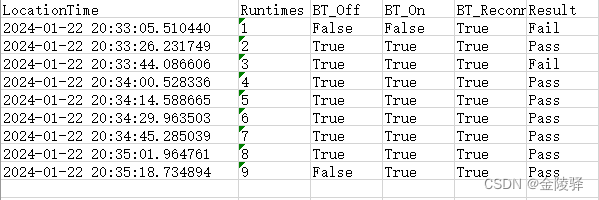
1.1 实现代码1:列数为常量
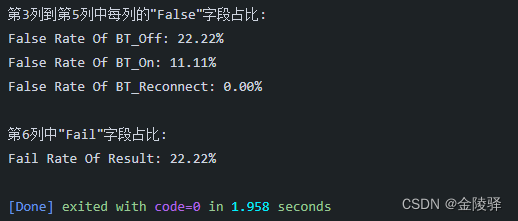
请确保替换`'your_excel_file.xlsx'`为你实际的Excel文件路径。这段代码会按每列首行元素名打印出第3列到第5列中每列的"False"字段占比,以及第6列中"Pass"字段的占比
#!/usr/bin/env python3
# _*_ coding : UTF-8 _*_
# 开发人员 :jly
# 开发时间 :2024/01/31 18:57:54
# 文件名称 :rate.py
# 开发工具 :Visual Studio Codeimport pandas as pd# 读取Excel文件
file_path = 'result.xlsx' # 替换成你的Excel文件路径
df = pd.read_excel(file_path)# 定义一个函数用于计算占比
def calculate_percentage(column, target_value):return column.value_counts(normalize=True).get(target_value, 0) * 100def str_percentages():false_percentages = df.iloc[:, 2:5].apply(lambda col: calculate_percentage(col, False), axis=0) # 统计第3列到第5列中每列的"False"字段占比Fail_percentage = calculate_percentage(df.iloc[:, 5], 'Fail') # 统计第6列中"Fail"字段占比return false_percentages, Fail_percentage# 打印结果
def print_rate():print("第3列到第5列中每列的\"False\"字段占比:")for column_name, percentage in zip(df.columns[2:5], str_percentages()[0]):print(f"False Rate Of {column_name}: {percentage:.2f}%")print("\n第6列中\"Fail\"字段占比:")print(f"Fail Rate Of Result: {str_percentages()[1]:.2f}%")if __name__ == '__main__':print_rate()运行结果:
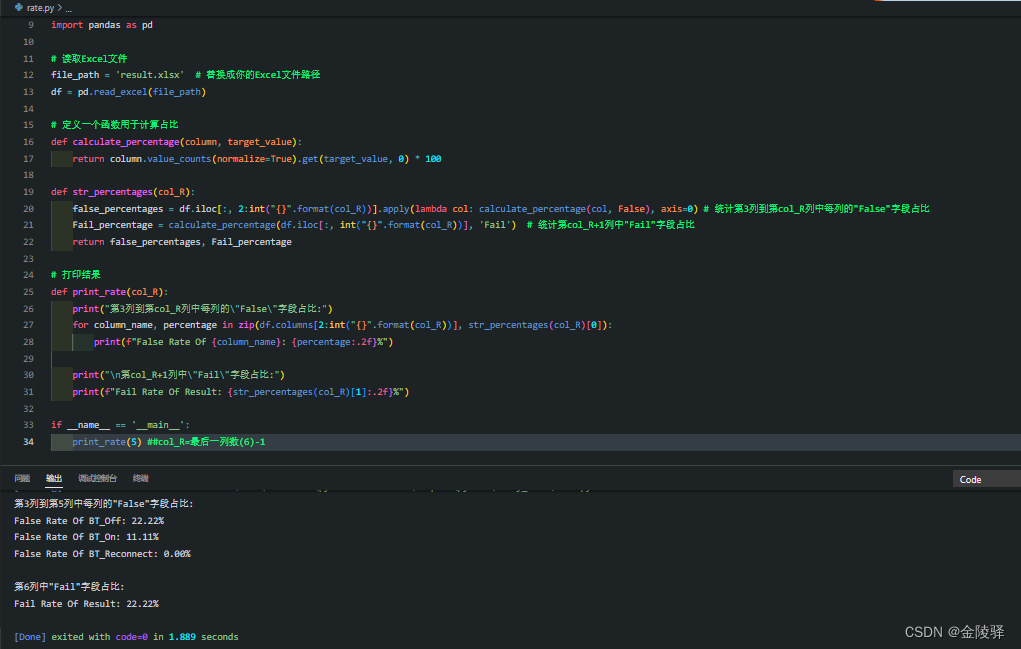
1.2 实现代码2:列数为变量
#!/usr/bin/env python3
# _*_ coding : UTF-8 _*_
# 开发人员 :jly
# 开发时间 :2024/01/31 18:57:54
# 文件名称 :rate.py
# 开发工具 :Visual Studio Codeimport pandas as pd# 读取Excel文件
file_path = 'result.xlsx' # 替换成你的Excel文件路径
df = pd.read_excel(file_path)# 定义一个函数用于计算占比
def calculate_percentage(column, target_value):return column.value_counts(normalize=True).get(target_value, 0) * 100def str_percentages(col_R):false_percentages = df.iloc[:, 2:int("{}".format(col_R))].apply(lambda col: calculate_percentage(col, False), axis=0) # 统计第3列到第5列中每列的"False"字段占比Fail_percentage = calculate_percentage(df.iloc[:, int("{}".format(col_R))], 'Fail') # 统计第6列中"Fail"字段占比return false_percentages, Fail_percentage# 打印结果
def print_rate(col_R):print("第3列到第col_R列中每列的\"False\"字段占比:")for column_name, percentage in zip(df.columns[2:int("{}".format(col_R))], str_percentages(col_R)[0]):print(f"False Rate Of {column_name}: {percentage:.2f}%")print("\n第col_R列中\"Fail\"字段占比:")print(f"Fail Rate Of Result: {str_percentages(col_R)[1]:.2f}%")if __name__ == '__main__':print_rate(5) #col_R=最后一列数(6)-1运行结果:
这篇关于解析Excel文件内容,按每列首行元素名打印出某个字符串的统计占比(超详细)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






