本文主要是介绍面试官:说一说Binlog是怎么实现的,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
复制概述
简单来说,“复制”就是将来自一个MySQL Server(这里指master角色,即主库)的数据变更,通过其逻辑的二进制日志(binlog)传输到其他的一个或多个MySQLServer(这里指slave角色,即从库)中,其他MySQL Server通过应用(回放)这些逻辑的二进制日志来完成数据的同步。这些MySQL Server之间的逻辑关系,我们称为“复制拓扑”(也可以称为“复制架构”)。
MySQL的复制功能是构建MySQL大规模、高性能应用的基础。我们可以通过配置一个或者多个备库的方式来进行数据同步。复制功能不仅有利于构建高性能的应用,同时也是高可用性、可扩展性、灾难恢复、备份以及数据仓库等工作的基础。
复制常见用途
-
• 数据分布: 在不同的地理位置分布数据备份,创建数据的本地副本。
-
• 负载均衡: 通过MySQL复制将读操作分布到多个服务器上,实现对读密集型应用的优化,并且实现很方便,通过简单的代码修改就能实现基本的负载均衡
-
• 备份: 复制的一项很有意义的补充,但复制既不是备份也不能取代备份
-
• 高可用和故障切换:复制能够帮助应用程序避免MySQL单点故障,一个包含复制的设计良好的故障切换系统能够现住地缩短宕机时间。
-
• MySQL升级测试:使用更高版本的MySQL作为备库,保证在升级全部实例前查询能够在备库按照预期执行。
复制原理
复制的过程
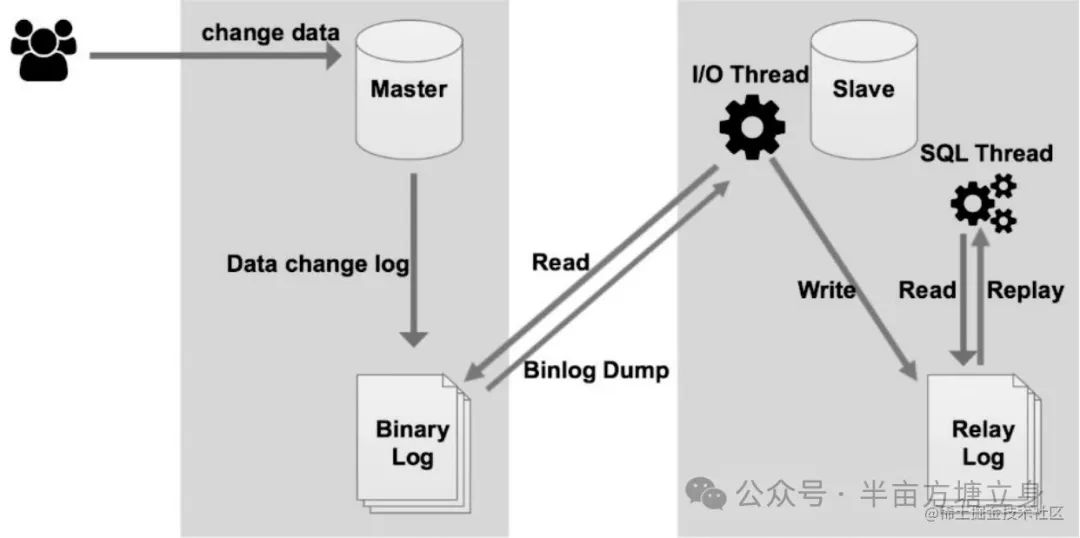
单线程复制
-
在主库上把数据更改记录到二进制日子(Binary Log)中
-
备库将主库上的日志复制到自己的中继日志(Relay Log)中。
-
备库读取中继日志中的事件,将其重放到备库数据之上。
复制使用三个线程来实现:
从节点:
I/O Thread: 从 Master 节点请求二进制日志事件,并保存于中继日志中。
Sql Thread: 从Relay log 中读取日志事件并在本地完成重放。
主节点:
Dump Thread:为每个 Slave 的 I/O Thread 启动一个 dump 线程,用于向从节点发送二进制事件。
DATABASE多线程复制(5.6)
库级别的多线程复制。主要的改进在于从库复制的SQL线程——增加了一个SQL协调器线程(Coordinator线程),真正干活的SQL线程被称为工作线程(Worker线程),当Worker线程为N个(N > 1)以及主库的DATABASE(Schema)为N个时,从库就可以根据多个DATABASE之间相互独立(彼此之间无锁冲突)的语句来实现多线程复制;
LOGICAL_CLOCK多线程复制(5.7)
LOGICAL_CLOCK基于组提交的并行复制方式,允许并行回放的粒度为事务级别,即便在同一时间修改数据的操作针对的是同一个数据库,理论上只要事务之间不存在锁冲突,就允许并行。
WRITESET多线程复制(5.7.22,8)
只要不同事务的修改记录不重叠,就可以在从库中并行回放。通过计算每行记录的哈希值(hash)来确定其是否为相同的记录。该哈希值就是WRITESET值。
这个hash值是通过“库名+表名+索引名+值”计算出来的。如果一个表上除了有主键索引外,还有其他唯一索引,那么对于每个唯一索引,insert语句对应的writeset就要多增加一个hash值。
数据同步方法
MySQL 5.7支持以下两种数据同步方法(也可以称为复制模式或复制方法)
传统复制
也可以称为基于二进制日志文件和位置的复制,在从库中配置复制时,要求指定从主库中获取的二进制日志文件(binlog file)和位置(binlogposition),以便从库中的复制线程启动时,能够以指定的二进制日志文件和位置为起点,持续读取主库中的二进制日志,并在从库中应用,从而达到数据同步的目的。
GTID复制
GTID(全局事务标识符)是新的事务性复制方法,利用GTID可以自动在主库中寻找需要复制的二进制日志记录,因此不需要关心日志文件或位置,极大地简化了许多常见的复制任务。使用GTID复制可确保主库和从库之间的一致性。
-
GTID的组成部分 GDIT由两部分组成:GTID = source_id:transaction_id。 其中source_id是产生GTID的服务器,即是server_uuid,在第一次启动时生成(sql/mysqld.cc: generate_server_uuid()),并保存到DATADIR/auto.cnf文件里。transaction_id是序列号(sequence number),在每台MySQL服务器上都是从1开始自增长的顺序号,是事务的唯一标识。例如:3E11FA47-71CA-11E1-9E33-C80AA9429562:23 GTID 的集合是一组GTIDs,可以用source_id+transaction_id范围表示,例如:3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5 复杂一点的:如果这组 GTIDs 来自不同的 source_id,各组 source_id 之间用逗号分隔;如果事务序号有多个范围区间,各组范围之间用冒号分隔,例如:3E11FA47-71CA-11E1-9E33-C80AA9429562:23,3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5
-
GTID产生 GTID的生成受GTID_NEXT控制。
在主服务器上,GTID_NEXT默认值是AUTOMATIC,即在每次事务提交时自动生成GTID。它从当前已执行的GTID集合(即gtid_executed)中,找一个大于0的未使用的最小值作为下个事务GTID。同时在实际的更新事务记录之前,将GTID写入到binlog(set GTID_NEXT记录,mysql.gtid_executed表中)。 在Slave上,从binlog先读取到主库的GTID(即get GTID_NEXT记录),而后执行的事务采用该GTID。 -
GTID的工作原理
GTID在所有主从服务器上都是不重复的。所以所有在从服务器上执行的事务都可以在bnlog找到。一旦一个事务提交了,与拥有相同GTID的后续事务都会被忽略。这样可以保证从服务器不会重复执行同一件事务。
当使用GTID时,从服务器不需要保留任何非本地数据。使用数据都可以从replicate data stream。从DBA和开发者的角度看,从服务器无保留file-offset pairs以决定如何处理主从服务器间的数据流。 -
GTID的生成和使用由以下几步组成
-
主服务器更新数据时,会在事务前产生GTID,一同记录到binlog日志中。
-
binlog传送到从服务器后,被写入到本地的relay log中。从服务器读取GTID,并将其设定为自己的GTID(GTID_NEXT系统)。
-
sql线程从relay log中获取GTID,然后对比从服务器端的binlog是否有记录。
-
如果有记录,说明该GTID的事务已经执行,从服务器会忽略。
-
如果没有记录,从服务器就会从relay log中执行该GTID的事务,并记录到binlog。
-
复制的格式
-
基于statement的复制(Statement Based Replication,SBR):当系统变量binlog_format设置为statement时表示使用SBR。SBR复制的是整个SQL语句的原始文本,日志量较小,但容易出现主从库数据不一致。对于SBR,当执行的某个语句被判定为不安全时,是否允许其执行还取决于事务的隔离级别。
-
基于row的复制(Row Based Replication,RBR):当系统变量binlog_format设置为row时表示使用RBR。RBR复制的是发生更改的数据行的实际记录(原始语句会被转换为发生变更的行数据记录),日志量较大,但可以保证主从库数据的一致性。
-
混合复制(Mixed Based Replication,MBR):系统变量binlog_format设置为mixed时表示使用MBR。MBR实际上是由MySQL自行判断的,即在不影响数据一致性的情况下,使用SBR;如果可能影响数据一致性,则自动转换为RBR。
数据同步方式
异步复制
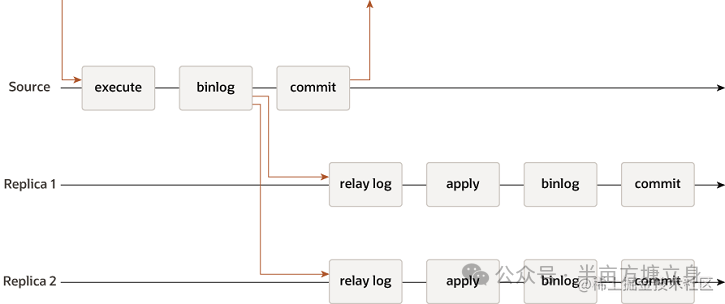
image.png
-
复制过程 传统的 MySQL 复制提供了一种简单的主从复制方法。有一个主要(源)和一个或多个次要(副本)。主节点执行事务,提交它们,然后它们稍后(因此异步)发送到辅助节点以重新执行(在基于语句的复制中)或应用(在基于行的复制中)。它是一个无共享系统,默认情况下所有服务器都有数据的完整副本。
-
数据一致性 主库在执行完客户端提交的事务后会立即提交并返回,不关心从库是否已经接收到日志并处理。如果此时主库上已经提交的事务因为某些原因未传送到从库,同时主库发生宕机,且在此时从库提升为主库,就会导致新主库数据缺失,从而造成主从数据不一致的情况发生。该复制模式下必然存在此问题。
半同步复制
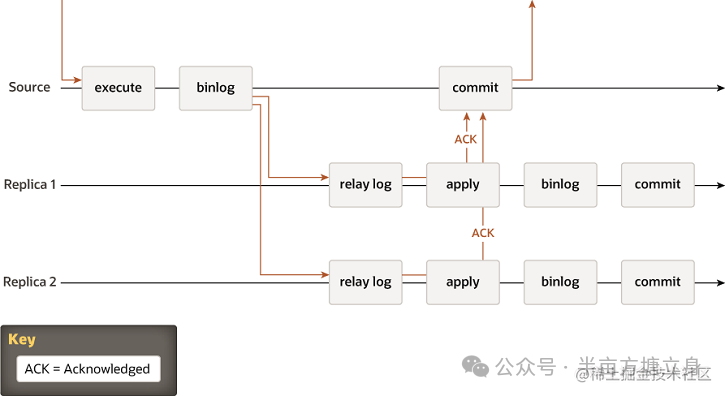
image.png
-
复制过程 MySQL 5.7(从MySQL 5.5开始支持半同步复制)除内置了异步复制之外,还支持半同步复制。使用半同步复制时,主库的会话在提交事务之前,会等待至少一个从库返回收到二进制日志的ACK消息(确认接收,并将事务的事件记录到从库的中继日志中)。
半同步复制,它的协议增加了一个同步步骤。这意味着主节点在提交时等待辅助节点确认它已收到事务。只有这样,主节点才会恢复提交操作。
半同步复制介于异步复制和完全同步复制之间。源等待至少一个副本接收并记录事件(所需的副本数量是可配置的),然后提交事务。源不会等待所有副本都确认收到,它只需要来自副本的确认,而不是事件已在副本端完全执行和提交。因此,半同步复制保证如果源崩溃,它提交的所有事务都已传输到至少一个副本。
与异步复制相比,半同步复制提供了改进的数据完整性,因为当提交成功返回时,知道数据至少存在于两个地方。在半同步源从所需数量的副本收到确认之前,事务将被搁置且未提交。
与异步复制相比,半同步复制的性能影响是增加数据完整性的权衡。减速量至少是将提交发送到副本并等待副本确认接收的 TCP/IP 往返时间。这意味着半同步复制最适合通过快速网络进行通信的近距离服务器,而对于通过慢速网络进行通信的远程服务器则最差。半同步复制还通过限制二进制日志事件从源发送到副本的速度来限制繁忙会话的速率。当一个用户太忙时,这会减慢速度,这在某些部署情况下很有用。
该 ACK 是确保日志传送到从库并写入到中继日志,而不是从库已经完成重放、将数据写入完成 -
数据一致性
-
普通半同步 AFTER_COMMIT。处理流程如下。首先要理解第三步引擎层提交的含义。第三步完成后,由于主库还未收到从库返回的确认信息,当前会话一直无法完成并返回给客户端,但主库的其他会话已经可以看到执行的结果了。如果按照事务隔离级别来理解,就相当于对主库的读取出现了脏读。
(1)数据层不一致。主库宕机重启后,依然有之前的记录,由于从库未接收到日志,且提升为主库后无法再同步这部分数据,而原主库重启后数据库会跳过 ACK验证,引擎层会将事务再次提交,就会比新主库多一条记录。
(2)应用层不一致。前后看到的结果不一致。 -
增强半同步 AFTER_SYNC。MySQL 从 5.7 版本开始支持增强半同步并设为默认值,增强半同步是接收从库返回 ACK 信息后再做引擎层提交,解决了普通半同步的脏读、应用层不一致的问题。处理流程如下:
(1)日志丢失,主从切换。如果出现主库日志未同步到从库或从库接收后未写入 Relay Log,且此时发生主从切换就会导致从库应用日志丢失,出现数据不一致的情况。所以出现主从数据不一致要具备 2 个条件 :主库日志未同步到从库 ;同时发生主从切换。
应用客户端向主库发起一条插入请求,然后开始提交,如果此时网络中断,日志未发送到从库,也就无法接受从库的 ACK 信息,于是提交无法进行,处于 hang 状态。这时如果主库宕机,且同时发生主从切换,那么应用客户端会出现报错,记录未插入成功,新主库同样也没有这条记录。当应用客户端连接新主库后重新发起请求,可再次插入这条记录,应用逻辑没有被破坏,数据是一致的。
但此时会出现数据层的不一致。当原主库再次启动后,会跳过 ACK 验证,对PendingBinlog 进行引擎层面的提交,所以启动后原主库就会存在这条记录,而新主库并没有,从而造成数据层的不一致。
当应用连接新主库再次执行这条记录时,新主库会把这条记录发送给原主库,就会报错(如果是主键)或出现重复数据。
(2)日志未丢失,主从未切换。主库因为无法接收到从库的ACK 信息而无法提交并返回,此时主库宕机,如果主库重启动后未切换,主库可以正常启动,那么这条记录同样会被提交。而应用层的反应是异常,该条记录并未成功,那么会出现应用层的不一致。
(3)一主多从,日志丢失。有一种极端情况,即使是增强半同步,也会出现数据层和应用层的数据不一致在一主多从的情况下,将应答从库数量设置为 1,同城数据中心 A 的从库首先接收到日志并返回 ACK 给主库,主库就可以正常提交。如果数据中心 A 的主库和从库均发生宕机,而这此时日志尚未发送给数据库中心 B、异地数据中心的从库,并且发生了主从切换,那么这两个数据中心从库就会在数据层和应用层均出现和原主库数据不一致的现象
延迟复制
MySQL 5.7 支持延迟复制,以便副本服务器故意落后于源至少指定的时间。默认延迟为 0 秒。使用 MASTER_DELAY选项将延迟设置为N秒。
延迟复制可用于多种目的:
-
防止用户在源头上犯错。DBA 可以将延迟的副本回滚到灾难发生之前的时间。
-
测试系统在滞后时的行为。例如,在应用程序中,延迟可能是由副本上的重负载引起的。但是,生成这种负载级别可能很困难。延迟复制可以模拟滞后,而不必模拟负载。它还可用于调试与滞后副本相关的条件。
同步复制
指的是需要保证写操作完全同步到其他数据节点,而不仅仅是二进制日志被其他节点接收。例如NDB Cluster,它是一种集群架构,所有节点都可以进行读/写,而且每个节点上发生的写操作都会实时同步到其他节点。对于需要同步复制的场景,可以使用NDB Cluster,或者其他类似的开源解决方案(虚拟同步,非完全同步),例如Percona XtraDB Cluster(PXC)、MariaDB Galera Cluster(MGC)、MySQL Group Replication(MGR)。
复制的应用-canal
canal是什么
基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
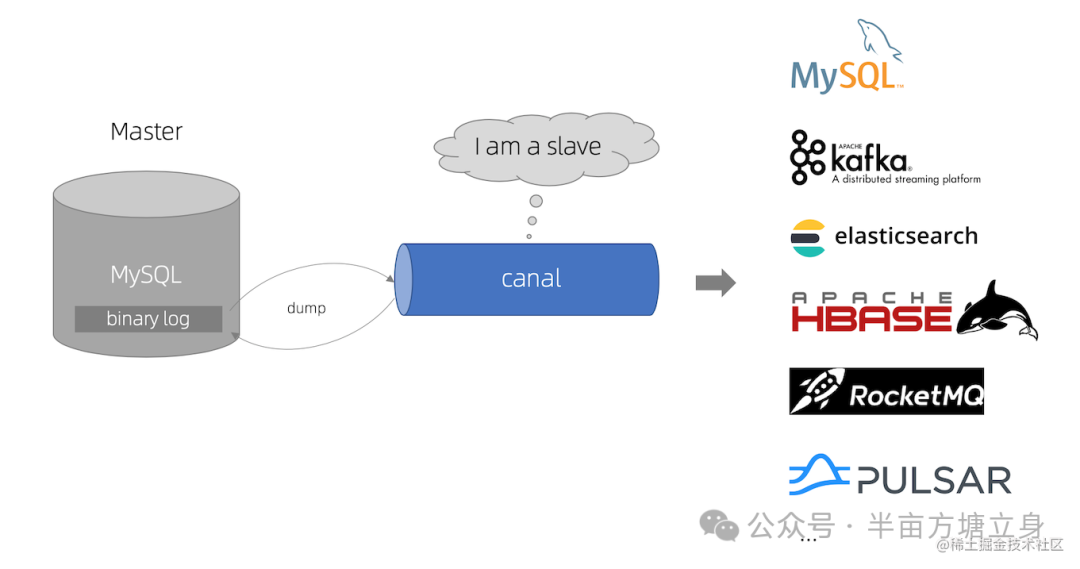
image.png
canal的数据同步不是全量的,而是增量。基于binary log增量订阅和消费,canal可以做:
-
数据库镜像
-
数据库实时备份
-
索引构建和实时维护
-
业务cache(缓存)刷新
-
带业务逻辑的增量数据处理
canal 工作原理
-
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
-
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
-
canal 解析 binary log 对象(原始为 byte 流)
这篇关于面试官:说一说Binlog是怎么实现的的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





