本文主要是介绍(转)C# 获取汉字的拼音首字母和全拼(含源码)[A],希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
https://blog.csdn.net/younghaiqing/article/details/62417269
C# 获取汉字的拼音首字母
一种是把所有中文字符集合起来组成一个对照表;另一种是依照汉字在Unicode编码表中的排序来确定拼音的首字母。碰到多音字时就以常用的为准(第一种方法中可以自行更改,方法为手动把该汉字移动到对应的拼音首字母队列,我们这里介绍第二种。
获取汉字拼音的首字母是一个在做项目的过程中经常需要用到的功能,今天我们主要来探讨下C# 获取汉字的拼音首字母
static void Main(string[] args)
{
Console.WriteLine(GetSpellCode("asdf牛逼你水电费")) ;
Console.ReadKey();
}
/// <summary>
/// 在指定的字符串列表CnStr中检索符合拼音索引字符串
/// </summary>
/// <param name="CnStr">汉字字符串</param>
/// <returns>相对应的汉语拼音首字母串</returns>
public static string GetSpellCode(string CnStr)
{
string strTemp = "";
int iLen = CnStr.Length;
int i = 0;
for (i = 0; i <= iLen - 1; i++)
{
strTemp += GetCharSpellCode(CnStr.Substring(i, 1));
}
return strTemp;
}
/// <summary>
/// 得到一个汉字的拼音第一个字母,如果是一个英文字母则直接返回大写字母
/// </summary>
/// <param name="CnChar">单个汉字</param>
/// <returns>单个大写字母</returns>
private static string GetCharSpellCode(string CnChar)
{
long iCnChar;
byte[] ZW = System.Text.Encoding.Default.GetBytes(CnChar);
//如果是字母,则直接返回
if (ZW.Length == 1)
{
return CnChar.ToUpper();
}
else
{
// get the array of byte from the single char
int i1 = (short)(ZW[0]);
int i2 = (short)(ZW[1]);
iCnChar = i1 * 256 + i2;
}
// iCnChar match the constant
if ((iCnChar >= 45217) && (iCnChar <= 45252))
{
return "A";
}
else if ((iCnChar >= 45253) && (iCnChar <= 45760))
{
return "B";
}
else if ((iCnChar >= 45761) && (iCnChar <= 46317))
{
return "C";
}
else if ((iCnChar >= 46318) && (iCnChar <= 46825))
{
return "D";
}
else if ((iCnChar >= 46826) && (iCnChar <= 47009))
{
return "E";
}
else if ((iCnChar >= 47010) && (iCnChar <= 47296))
{
return "F";
}
else if ((iCnChar >= 47297) && (iCnChar <= 47613))
{
return "G";
}
else if ((iCnChar >= 47614) && (iCnChar <= 48118))
{
return "H";
}
else if ((iCnChar >= 48119) && (iCnChar <= 49061))
{
return "J";
}
else if ((iCnChar >= 49062) && (iCnChar <= 49323))
{
return "K";
}
else if ((iCnChar >= 49324) && (iCnChar <= 49895))
{
return "L";
}
else if ((iCnChar >= 49896) && (iCnChar <= 50370))
{
return "M";
}
else if ((iCnChar >= 50371) && (iCnChar <= 50613))
{
return "N";
}
else if ((iCnChar >= 50614) && (iCnChar <= 50621))
{
return "O";
}
else if ((iCnChar >= 50622) && (iCnChar <= 50905))
{
return "P";
}
else if ((iCnChar >= 50906) && (iCnChar <= 51386))
{
return "Q";
}
else if ((iCnChar >= 51387) && (iCnChar <= 51445))
{
return "R";
}
else if ((iCnChar >= 51446) && (iCnChar <= 52217))
{
return "S";
}
else if ((iCnChar >= 52218) && (iCnChar <= 52697))
{
return "T";
}
else if ((iCnChar >= 52698) && (iCnChar <= 52979))
{
return "W";
}
else if ((iCnChar >= 52980) && (iCnChar <= 53640))
{
return "X";
}
else if ((iCnChar >= 53689) && (iCnChar <= 54480))
{
return "Y";
}
else if ((iCnChar >= 54481) && (iCnChar <= 55289))
{
return "Z";
}
else
return ("?");
}
static void Main(string[] args){Console.WriteLine(GetSpellCode("asdf牛逼你水电费")) ;Console.ReadKey();}/// <summary>/// 在指定的字符串列表CnStr中检索符合拼音索引字符串/// </summary>/// <param name="CnStr">汉字字符串</param>/// <returns>相对应的汉语拼音首字母串</returns>public static string GetSpellCode(string CnStr){string strTemp = "";int iLen = CnStr.Length;int i = 0;for (i = 0; i <= iLen - 1; i++){strTemp += GetCharSpellCode(CnStr.Substring(i, 1));}return strTemp;}/// <summary>/// 得到一个汉字的拼音第一个字母,如果是一个英文字母则直接返回大写字母/// </summary>/// <param name="CnChar">单个汉字</param>/// <returns>单个大写字母</returns>private static string GetCharSpellCode(string CnChar){long iCnChar;byte[] ZW = System.Text.Encoding.Default.GetBytes(CnChar);//如果是字母,则直接返回if (ZW.Length == 1){return CnChar.ToUpper();}else{// get the array of byte from the single charint i1 = (short)(ZW[0]);int i2 = (short)(ZW[1]);iCnChar = i1 * 256 + i2;}// iCnChar match the constantif ((iCnChar >= 45217) && (iCnChar <= 45252)){return "A";}else if ((iCnChar >= 45253) && (iCnChar <= 45760)){return "B";}else if ((iCnChar >= 45761) && (iCnChar <= 46317)){return "C";}else if ((iCnChar >= 46318) && (iCnChar <= 46825)){return "D";}else if ((iCnChar >= 46826) && (iCnChar <= 47009)){return "E";}else if ((iCnChar >= 47010) && (iCnChar <= 47296)){return "F";}else if ((iCnChar >= 47297) && (iCnChar <= 47613)){return "G";}else if ((iCnChar >= 47614) && (iCnChar <= 48118)){return "H";}else if ((iCnChar >= 48119) && (iCnChar <= 49061)){return "J";}else if ((iCnChar >= 49062) && (iCnChar <= 49323)){return "K";}else if ((iCnChar >= 49324) && (iCnChar <= 49895)){return "L";}else if ((iCnChar >= 49896) && (iCnChar <= 50370)){return "M";}else if ((iCnChar >= 50371) && (iCnChar <= 50613)){return "N";}else if ((iCnChar >= 50614) && (iCnChar <= 50621)){return "O";}else if ((iCnChar >= 50622) && (iCnChar <= 50905)){return "P";}else if ((iCnChar >= 50906) && (iCnChar <= 51386)){return "Q";}else if ((iCnChar >= 51387) && (iCnChar <= 51445)){return "R";}else if ((iCnChar >= 51446) && (iCnChar <= 52217)){return "S";}else if ((iCnChar >= 52218) && (iCnChar <= 52697)){return "T";}else if ((iCnChar >= 52698) && (iCnChar <= 52979)){return "W";}else if ((iCnChar >= 52980) && (iCnChar <= 53640)){return "X";}else if ((iCnChar >= 53689) && (iCnChar <= 54480)){return "Y";}else if ((iCnChar >= 54481) && (iCnChar <= 55289)){return "Z";}elsereturn ("?");}运行结果:
额外补贴:
1. ASCII码
我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
2、非ASCII编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。
比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0—127表示的符号是一样的,不一样的只是128—255的这一段。至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号。中文编码的问题需要专文讨论,这篇笔记不涉及。这里只指出,虽然都是用多个字节表示一个符号,但是GB类的汉字编码与后文的Unicode和UTF-8是毫无关系的。
3.Unicode
正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字“严”。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
4. Unicode的问题
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字“严”的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别unicode和ascii?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示unicode。2)unicode在很长一段时间内无法推广,直到互联网的出现。
5.UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
代码二:C# 获取汉字的拼音首字母和全拼
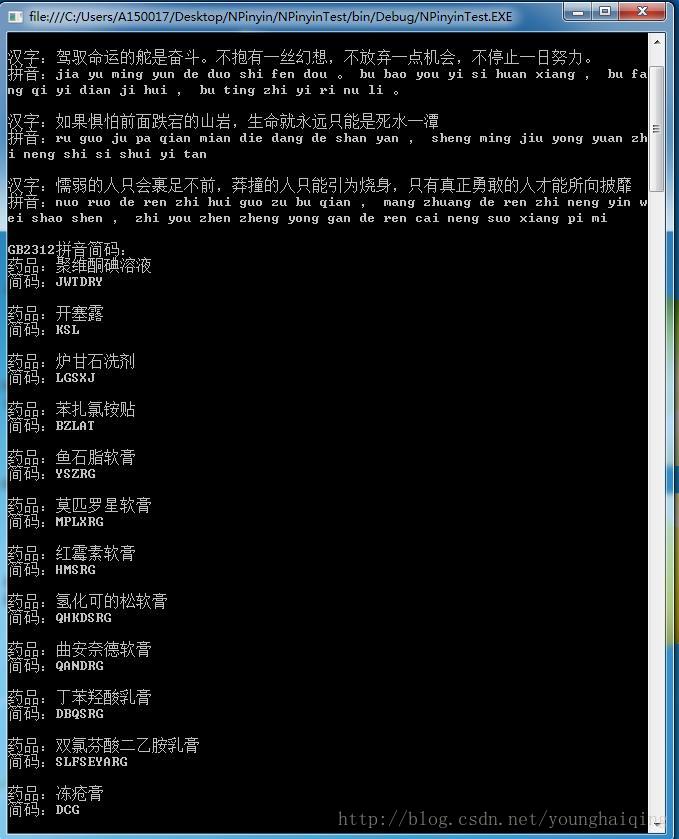
static void Main(string[] args){string[] maxims = new string[]{"事常与人违,事总在人为","骏马是跑出来的,强兵是打出来的","驾驭命运的舵是奋斗。不抱有一丝幻想,不放弃一点机会,不停止一日努力。 ","如果惧怕前面跌宕的山岩,生命就永远只能是死水一潭", "懦弱的人只会裹足不前,莽撞的人只能引为烧身,只有真正勇敢的人才能所向披靡"};string[] medicines = new string[] {"聚维酮碘溶液","开塞露","炉甘石洗剂","苯扎氯铵贴","鱼石脂软膏","莫匹罗星软膏","红霉素软膏","氢化可的松软膏","曲安奈德软膏","丁苯羟酸乳膏","双氯芬酸二乙胺乳膏","冻疮膏","克霉唑软膏","特比奈芬软膏","酞丁安软膏","咪康唑软膏、栓剂","甲硝唑栓","复方莪术油栓"};Console.WriteLine("UTF8句子拼音:");foreach (string s in maxims){Console.WriteLine("汉字:{0}\n拼音:{1}\n", s, Pinyin.GetPinyin(s));}Encoding gb2312 = Encoding.GetEncoding("GB2312");Console.WriteLine("GB2312拼音简码:");foreach (string m in medicines){string s = Pinyin.ConvertEncoding(m, Encoding.UTF8, gb2312);Console.WriteLine("药品:{0}\n简码:{1}\n", s, Pinyin.GetInitials(s, gb2312));}Console.ReadKey();}
static void Main(string[] args)
{
string[] maxims = new string[]{
"事常与人违,事总在人为",
"骏马是跑出来的,强兵是打出来的",
"驾驭命运的舵是奋斗。不抱有一丝幻想,不放弃一点机会,不停止一日努力。 ",
"如果惧怕前面跌宕的山岩,生命就永远只能是死水一潭",
"懦弱的人只会裹足不前,莽撞的人只能引为烧身,只有真正勇敢的人才能所向披靡"
};
string[] medicines = new string[] {
"聚维酮碘溶液",
"开塞露",
"炉甘石洗剂",
"苯扎氯铵贴",
"鱼石脂软膏",
"莫匹罗星软膏",
"红霉素软膏",
"氢化可的松软膏",
"曲安奈德软膏",
"丁苯羟酸乳膏",
"双氯芬酸二乙胺乳膏",
"冻疮膏",
"克霉唑软膏",
"特比奈芬软膏",
"酞丁安软膏",
"咪康唑软膏、栓剂",
"甲硝唑栓",
"复方莪术油栓"
};
Console.WriteLine("UTF8句子拼音:");
foreach (string s in maxims)
{
Console.WriteLine("汉字:{0}\n拼音:{1}\n", s, Pinyin.GetPinyin(s));
}
Encoding gb2312 = Encoding.GetEncoding("GB2312");
Console.WriteLine("GB2312拼音简码:");
foreach (string m in medicines)
{
string s = Pinyin.ConvertEncoding(m, Encoding.UTF8, gb2312);
Console.WriteLine("药品:{0}\n简码:{1}\n", s, Pinyin.GetInitials(s, gb2312));
}
Console.ReadKey();
}
这篇关于(转)C# 获取汉字的拼音首字母和全拼(含源码)[A]的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


![C#实战|大乐透选号器[6]:实现实时显示已选择的红蓝球数量](https://i-blog.csdnimg.cn/direct/cda2638386c64e8d80479ab11fcb14a9.png)