本文主要是介绍近三年CVPR引用量最高论文:恺明一如既往的正常发挥,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
近三年CVPR引用量最高论文(截止目前2022年11月):
- CVPR2020引用量最高的论文:MoCo
- CVPR2021引用量最高的论文:SimSiam
- CVPR2022引用量最高的论文:MAE
它们的共同点是:
- 三篇论文唯一单位:Facebook(FAIR)
- 三篇论文唯一共同作者:何恺明(KaimingHe)
- 三篇论文均属于:自监督学习(Self-Supervised Learning)
MoCo CVPR2020

- 论文地址:https://arxiv.org/pdf/1911.05722.pdf
- 开源地址:https://github.com/facebookresearch/moco
- 李沐精读:https://www.bilibili.com/video/BV1C3411s7t9/?spm_id_from=333.999.0.0&vd_source=ec54183c11e50329f6359027c7459966
- 知乎解读:https://zhuanlan.zhihu.com/p/382763210
- 知乎解读:https://zhuanlan.zhihu.com/p/365886585
MoCo为CV拉开了Self-Supervised的新篇章,与Transformer联手成为了深度学习炙手可热的研究方向。
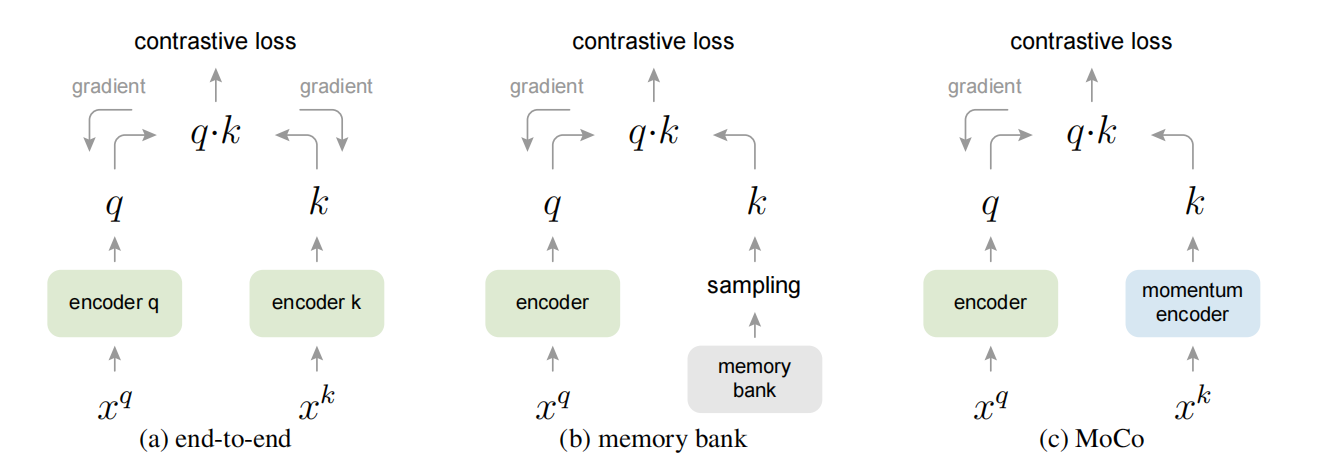
MoCo主要设计了三个核心操作:Dictionary as a queue、Momentum update和Shuffling BN。
Dictionary as a queue
MoCo提出了将memory bank的方法改进为dictionary as a queue,意思就是跟memory bank类似,也保存数据集中数据特征,只不过变成了queue的形式存储,这样每个epoch会enqueue进来一个batch的数据特征,然后dequeue出去dictionary中保存时间最久的一个batch的数据特征,整体上来看每个epoch,dictionary中保存的数据特征总数是不变的,并且随着epoch的进行会更新dictionary的数据特征。同时dictionary的容量不需要很大。
Momentum update 动量更新
MoCo在dictionary as a queue的基础上,增加了一个momentum encoder的操作,key的encoder参数等于query的encoder参数的滑动平均,公式如下:
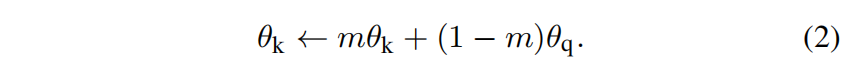
θ k \theta_k θk和 θ q \theta_q θq分别是key的encoder和query的encoder的参数,m是0-1之间的动量系数。因为momentum encoder的存在,导致key支路的参数避免了突变,可以将多个epoch的数据特征近似成一个静止的大batch数据特征。
MoCo伪代码如下:
f_k.params = f_q.params # 初始化
for x in loader: # 输入一个图像序列x,包含N张图,没有标签x_q = aug(x) # 用于查询的图(数据增强得到)x_k = aug(x) # 模板图(数据增强得到),自监督就体现在这里,只有图x和x的数据增强才被归为一类q = f_q.forward(x_q) # 提取查询特征,输出NxCk = f_k.forward(x_k) # 提取模板特征,输出NxC# 不使用梯度更新f_k的参数,这是因为文章假设用于提取模板的表示应该是稳定的,不应立即更新k = k.detach() # 这里bmm是分批矩阵乘法l_pos = bmm(q.view(N,1,C), k.view(N,C,1)) # 输出Nx1,也就是自己与自己的增强图的特征的匹配度l_neg = mm(q.view(N,C), queue.view(C,K)) # 输出Nxk,自己与上一批次所有图的匹配度(全不匹配)logits = cat([l_pos, l_neg], dim=1) # 输出Nx(1+k)labels = zeros(N)# NCE损失函数,就是为了保证自己与自己衍生的匹配度输出越大越好,否则越小越好loss = CrossEntropyLoss(logits/t, labels) loss.backward()update(f_q.params) # f_q使用梯度立即更新# 由于假设模板特征的表示方法是稳定的,因此它更新得更慢,这里使用动量法更新,相当于做了个滤波。f_k.params = m*f_k.params+(1-m)*f_q.params enqueue(queue, k) # 为了生成反例,所以引入了队列dequeue(queue)
SimSiam CVPR2021
- 论文地址:https://arxiv.org/pdf/2011.10566.pdf
- 知乎解读:https://zhuanlan.zhihu.com/p/452659570
- 解读博客:https://www.cnblogs.com/wyboooo/p/14036948.html
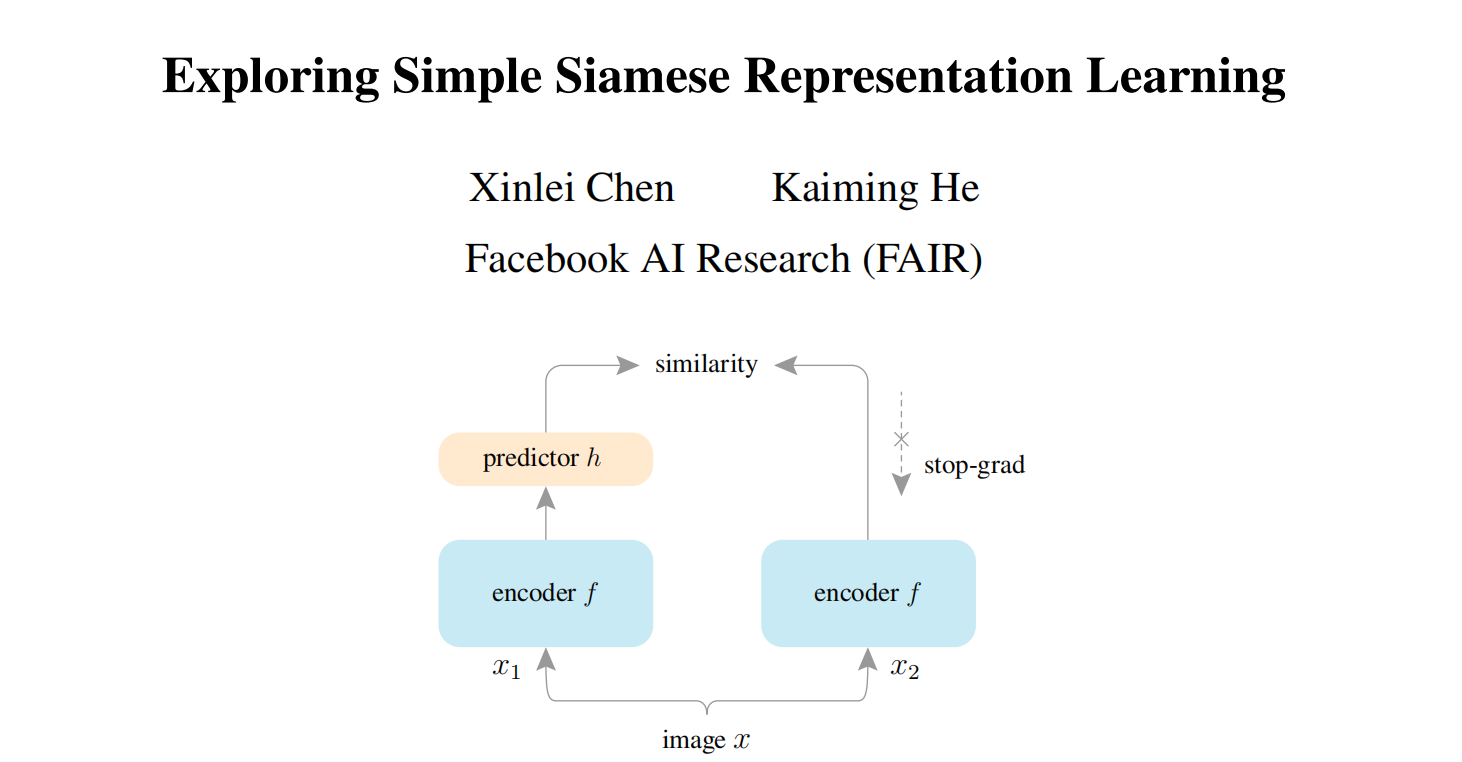
Siamese Network是近年来自监督/无监督任务中非常常用的网络,他是应用于两个或更多输入的一个权值共享的网络,是比较两个实体天然的工具。目前的大部分方法都是用一个图像的两种augmentation作为输入,在不同的条件下来最大化他们的相似度。但是Siamese Network会遇到的一个问题是,他的解可能会collapse至一个常量。目前常用的解决这个问题的方法有:Contrastive Learning,引入负样本,负样本会把constant 输出排除到解空间以外;Clustering;momentum encoder。
在本文中作者就指出,一个简单的Siamese 网络不需要以上方法也可以有效避免collapsing问题,并且不依赖于large-batch训练。作者将他们的方法称为“SimSiam”,并指出其中的stop-gradient操作才是在避免collapsing中非常重要的。这可能是由于有一个潜在的优化问题被解决了。作者推测实际上这里有两组变量,SimSiam实际上是在交替优化每一组变量。
SimSiam 伪代码如下:
# Algorithm1 SimSiam Pseudocode, Pytorch-like
# f: backbone + projection mlp
# h: prediction mlp
for x in loader: # load a minibatch x with n samplesx1, x2 = aug(x), aug(x) # random augmentationz1, z2 = f(x1), f(x2) # projections, n-by-dp1, p2 = h(z1), h(z2) # predictions, n-by-dL = D(p1, z2)/2 + D(p2, z1)/2 # lossL.backward() # back-propagateupdate(f, h) # SGD updatedef D(p, z): # negative cosine similarityz = z.detach() # stop gradientp = normalize(p, dim=1) # l2-normalizez = normalize(z, dim=1) # l2-normalize
return -(p*z).sum(dim=1).mean()
MAE CVPR2022
- 论文地址:https://arxiv.org/pdf/2111.06377.pdf
- 开源地址:https://github.com/facebookresearch/mae
- 李沐精读:https://www.bilibili.com/video/BV1sq4y1q77t/?spm_id_from=333.788&vd_source=ec54183c11e50329f6359027c7459966
- 知乎解读:https://zhuanlan.zhihu.com/p/432950958
- 知乎解读:https://zhuanlan.zhihu.com/p/448407149
Motivation
虽然预训练在NLP上正发展的如火如荼,但是在计算机视觉方向却鲜有文章,究其原因,论文中给出了三个重要的点。
- 模型架构不同:在过去的几十年,计算机视觉被卷积神经网络所垄断着,卷积是一个基于划窗的算法,它和其它嵌入(位置嵌入等)的融合比较困难,直到Transformer的提出才解决了这个问题。
- 信息密度不同:文本数据是经过人类高度抽象之后的一种信号,它的信息是密集的,所以仅仅预测文本中的几个被掩码掉的单词就能很好的捕捉文本的语义特征。而图像数据是一个信息密度非常小的矩阵,其中包含着大量的冗余信息,而且像素和它周围的像素仅仅在纹理上就有非常大的相似性,恢复被掩码的像素并不需要太多的语义信息。
- 解码器的作用不同:在BERT的掩码语言模型任务中,预测被掩码掉的单词是需要解码器了解文本的语义信息的。但是在计算机视觉的掩码预测任务中,预测被掩码的像素往往对图像的语义信息依赖的并不严重。
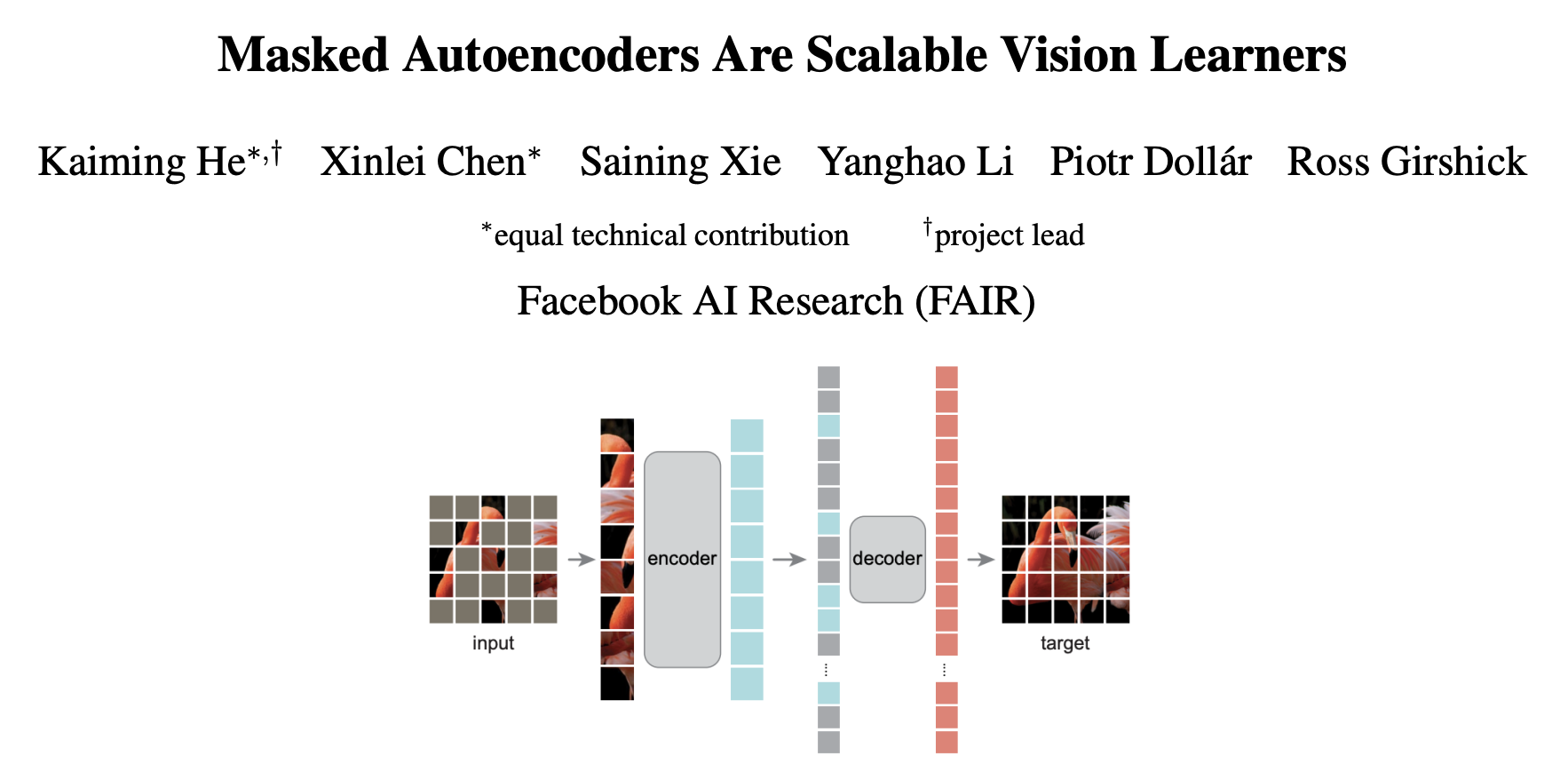
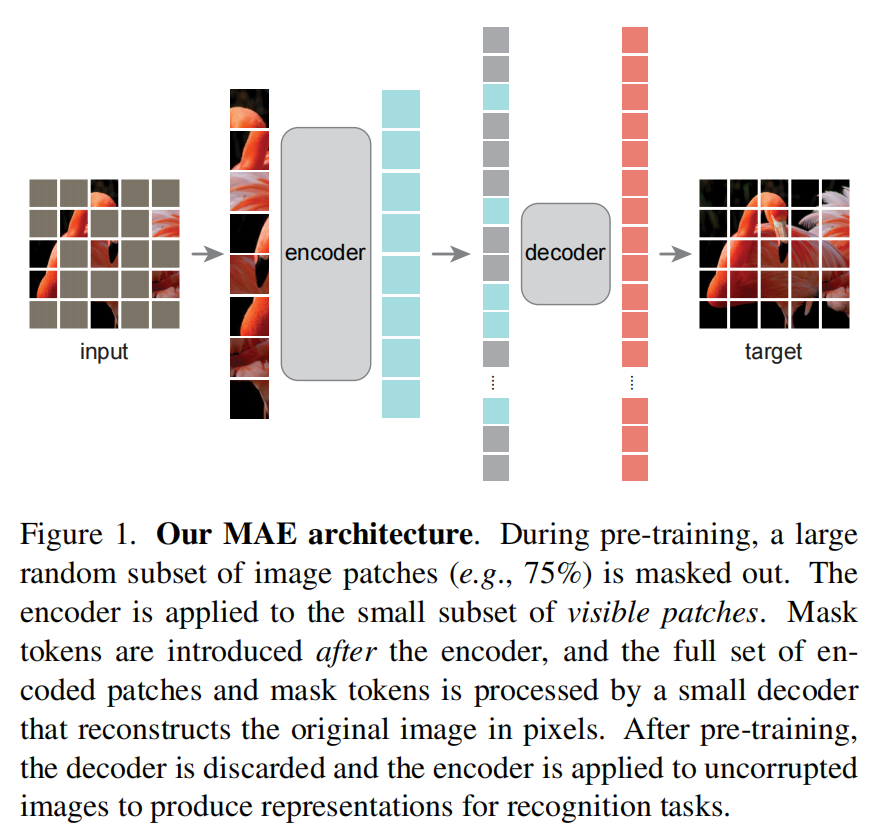
基于这三个动机,作者设计了基于掩码自编码器(Masked AutoEncoder,MAE)的图像预训练任务。MAE的先对图像的Patch进行掩码,然后通过模型还原这些掩码,从事实现模型的预训练。MAE的核心是通过75%的高掩码率来对图像添加噪音,这样图像便很难通过周围的像素来对被掩码的像素进行重建,迫使编码器去学习图像中的语义信息。
模型介绍
MAE的网络结构如图1所示,它是一个非对称的Encoder-Decoder架构的模型,Encoder架构是采用了ViT提出的以Transformer为基础的骨干网络,它的基于Patch的输入正好可以拿来作为掩码的基本单元。MAE的Decoder是一个轻量级的结构,它在深度和宽度上都比Encoder小很多。MAE的另一个非对称的表现在Encoder仅将未被掩码的部分作为输入,而Decoder将整个图像的Patch(掩码标志和Encoder编码后的未被掩码patch的图像特征)作为输入。
本文由mdnice多平台发布
这篇关于近三年CVPR引用量最高论文:恺明一如既往的正常发挥的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
