本文主要是介绍分类预测:会员回购预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目说明
数据集来自阿里天池:会员回购预测
目的是为了判断顾客是否会响应活动从而回购,也就是一个是否响应活动的二分类模型
数据说明
train&test
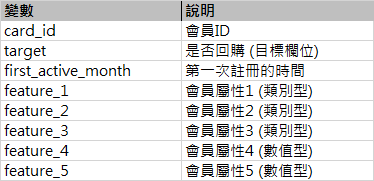
target:“0”代表不回购,“1”代表回购
transactions

代码
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from imblearn.over_sampling import SMOTE
from sklearn.svm import SVC
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import roc_auc_score, average_precision_score, confusion_matrix, classification_report# 读取数据
filename = r'C:\Users\liuhao\Desktop\新建文件夹\会员回购\train.csv'
filename1 = r'C:\Users\liuhao\Desktop\新建文件夹\会员回购\test.csv'
data = pd.read_csv(filename)
data1 = pd.read_csv(filename1)
train = data.copy()
test = data1.copy()# 数据处理和特征构造
train['first_active_month'] = pd.to_datetime(train['first_active_month'],format='%Y-%m-%d')
day = pd.to_datetime('2018-02-02')# 表中最大日期的后一个月,以此为基准
train['month_lag'] = day - train['first_active_month']
train['month_lag'] = train['month_lag'].apply(lambda x:x.days//30)
train.drop(train[train['month_lag'] == 244].index,inplace=True)# 去除一个异常值
train['year'] = train['first_active_month'].dt.year
train['month'] = train['first_active_month'].dt.month
yearlist = sorted(train['year'].unique())
train['year'] = train['year'].apply(lambda x:yearlist.index(x))# 将年份值缩小
x = train.iloc[:,3:]
x = pd.get_dummies(x,columns=['feature_1','feature_2','feature_3']).values# one-hot编码
y = train['target'].valuestest['first_active_month'] = pd.to_datetime(test['first_active_month'],format='%Y-%m-%d')
test['month_lag'] = day - test['first_active_month']
test['month_lag'] = test['month_lag'].apply(lambda x:x.days//30)
test['year'] = test['first_active_month'].dt.year
test['month'] = test['first_active_month'].dt.month
test['year'] = test['year'].apply(lambda x:yearlist.index(x))
test_x = test.iloc[:,3:]
test_x = pd.get_dummies(test_x,columns=['feature_1','feature_2','feature_3']).values
test_y = test['target'].values# 样本分布不均衡,采用过采样处理平衡数据
model_smote = SMOTE()
x_smote, y_smote = model_smote.fit_sample(x, y)
X_train, X_test, y_train, y_test = train_test_split(x_smote, y_smote,random_state=1)# LogisticRegression
lgr = LogisticRegression()
lgr.fit(X_train, y_train)print(lgr.score(X_test, y_test))
print(lgr.score(X_train, y_train))# 逻辑回归模型评估
print("LGR-test数据集")
print(lgr.score(test_x,test_y))
print("混淆矩阵")
print(confusion_matrix(test_y,lgr.predict(test_x)))
print('分类报告')
print(classification_report(test_y,lgr.predict(test_x)))
print("平均准确率:",average_precision_score(test_y,lgr.predict_proba(test_x)[:, 1]))
print("AUC:",roc_auc_score(test_y,lgr.predict_proba(test_x)[:, 1]))# SVM
svm = SVC(C=100)
svm.fit(X_train, y_train)print(svm.score(X_test, y_test))
print(svm.score(X_train,y_train))# SVM模型评估
print("SVM-test数据集")
print(svm.score(test_x, test_y))
print("混淆矩阵")
print(confusion_matrix(test_y,svm.predict(test_x)))
print('分类报告')
print(classification_report(test_y,svm.predict(test_x)))
print("平均准确率:",average_precision_score(test_y,svm.decision_function(test_x)))
print("AUC:",roc_auc_score(test_y,svm.decision_function(test_x)))# GradientBoostingClassifier
gbc = GradientBoostingClassifier(learning_rate=0.15,max_depth=4,random_state=0)
gbc.fit(X_train, y_train)print(gbc.score(X_train, y_train))
print(gbc.score(X_test, y_test))# GBC模型评估
print("GBC-test数据集")
print(gbc.score(test_x, test_y))
print("混淆矩阵")
print(confusion_matrix(test_y,gbc.predict(test_x)))
print('分类报告')
print(classification_report(test_y,gbc.predict(test_x)))
print("平均准确率:",average_precision_score(test_y,gbc.decision_function(test_x)))
print("AUC:",roc_auc_score(test_y,gbc.decision_function(test_x)))
结论
从精度和平均准确率上的表现来看,GBC远大于后两者,后两者的表现差不多。但模型最终还是服务于业务,从实际问题出发,最终目的是要更精准的唤醒休眠用户进行回购。所以更改评估指标,追求对目标的召回率和准确率,最终采用 SVM 模型。
SVM 模型评估结果
SVC-测试集
0.5258001306335728
混淆矩阵
[[1107 1166][ 286 503]]
分类报告precision recall f1-score support0 0.79 0.49 0.60 22731 0.30 0.64 0.41 789accuracy 0.53 3062macro avg 0.55 0.56 0.51 3062
weighted avg 0.67 0.53 0.55 3062平均准确率: 0.30681997055555077
AUC: 0.5767292462293625
在测试集中样本的分布并不均衡,尤其是目标样本数量较少,调整 SVM 模型决策函数的阈值会得到更好的结果。
#
y_pred_lower_threshold_svc_test = svm.decision_function(test_x) > -.8y_pred_lower_threshold_svc_test = svm.decision_function(test_x) > -.8
print(classification_report(test_y, y_pred_lower_threshold_svc_test))
print(confusion_matrix(test_y, y_pred_lower_threshold_svc_test))
print("平均准确率:",average_precision_score(test_y,y_pred_lower_threshold_svc_test))
print("AUC:",roc_auc_score(test_y,y_pred_lower_threshold_svc_test))SVC调整阈值precision recall f1-score support0 0.82 0.18 0.29 22731 0.27 0.88 0.42 789accuracy 0.36 3062macro avg 0.54 0.53 0.36 3062
weighted avg 0.68 0.36 0.33 3062[[ 408 1865][ 91 698]]
平均准确率: 0.27064600633385816
AUC: 0.5320812959985993
说明
- 数据处理部分,train 和 test 可以先拼接再一起处理的。另外在实际过程中有对数据做过缩放,可能是因为数据的量纲相差不大,对模型结果没啥影响,也就去掉了。
- 开始并未使用 SMOTE 对数据过抽样处理,模型的精度会更好一点,在0.7-0.8之间。但是在目标的召回率 - 准确率上表现极差,所以采用过抽样和欠抽样处理。只是欠抽样处理结果不如过抽样。另外也用了
SVC(class_weight='balanced')调节权重,结果不是很好。 - 有简单尝试根据stacking思路将几个模型的结果整合后再训练一个新模型,但结果也不是很好。
- 在 transactions 数据集中有用户的交易数据,曾想套用 RFM 模型多构造几个特征,构造完连接两个数据集发现两边独立用户并不一样。有想过计算 RFM 得分然后用算法回归填充。
- 进一步优化思路可以尝试集成算法或者调参
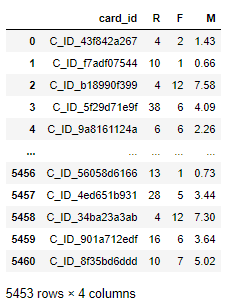
最后贴上 RFM 实现代码
import pandas as pd
import numpy as npfilename1 = r'C:\Users\liuhao\Desktop\新建文件夹\会员回购\train.csv'
filename2 = r'C:\Users\liuhao\Desktop\新建文件夹\会员回购\transactions.csv'
data1 = pd.read_csv(filename1)
data2 = pd.read_csv(filename2)train = data1.copy()
transactions = data2.copy()transactions['purchase_date'] = transactions['purchase_date'].apply(lambda x:x.split(" ")[0])
transactions['purchase_date'] = pd.to_datetime(transactions['purchase_date'],format = "%Y-%m-%d")rfm = pd.pivot_table(transactions,index=['card_id'],values=['purchase_date','month_lag','purchase_amount'],aggfunc={'purchase_date':'max','month_lag':'count',"purchase_amount":lambda x:abs(x).sum()})
inner_concat = pd.merge(train,rfm,how='inner',on='card_id')inner_concat['first_active_month'] = pd.to_datetime(inner_concat['first_active_month'],format='%Y-%m-%d %H:%M:%S')
inner_concat['lifetime'] = (inner_concat['purchase_date'] - inner_concat['first_active_month'])
inner_concat['lifetime'] = inner_concat['lifetime'].apply(lambda x:x.days//30)
RFM = pd.DataFrame()
RFM['card_id'] =inner_concat['card_id']
RFM['R'] = inner_concat['lifetime']
RFM['F'] = inner_concat['month_lag']
RFM['M'] = inner_concat['purchase_amount'].round(2)
RFM.drop_duplicates(subset=['card_id'],inplace=True)
这篇关于分类预测:会员回购预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








