本文主要是介绍马哈鱼SQLFlow Lite的python版本,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Gudu SQLFlow 是一款用来分析各种数据库的 SQL 语句和存储过程来获取复杂的数据血缘关系并进行可视化的工具。
Gudu SQLFlow Lite version for python 可以让 python 开发者把数据血缘分析和可视化能力快速集成到他们自己的 python 应用中。
Gudu SQLFlow Lite version for python 对非商业用途来说是免费的,它可以处理 10k 长度以下的任意复杂的 SQL 语句,包含对存储过程的支持。
Gudu SQLFlow Lite version for python 包含一个 Java 类库,通过分析复杂的 SQL 语句和存储过程来获取数据血缘关系,一个 python 文件,
通过 jpype 来调用 Java 类库中的 API, 一个 Javascript 库,用来可视化数据血缘关系。
Gudu SQLFlow Lite version for python 还可以自动从数据库中导出的 DDL 脚本中获取表和表,字段和字段间的约束关系,画出 ER Diagram.
自动可视化数据血缘关系
通过执行这条命令,
python dlineage.py /t oracle /f test.sql /graph
我们可以自动获得下面这个 Oracle SQL 语句包含的数据血缘关系
CREATE VIEW vsal
AS SELECT a.deptno "Department", a.num_emp / b.total_count "Employees", a.sal_sum / b.total_sal "Salary" FROM (SELECT deptno, Count() num_emp, SUM(sal) sal_sum FROM scott.emp WHERE city = 'NYC' GROUP BY deptno) a, (SELECT Count() total_count, SUM(sal) total_sal FROM scott.emp WHERE city = 'NYC') b
;INSERT ALLWHEN ottl < 100000 THENINTO small_ordersVALUES(oid, ottl, sid, cid)WHEN ottl > 100000 and ottl < 200000 THENINTO medium_ordersVALUES(oid, ottl, sid, cid)WHEN ottl > 200000 THENinto large_ordersVALUES(oid, ottl, sid, cid)WHEN ottl > 290000 THENINTO special_orders
SELECT o.order_id oid, o.customer_id cid, o.order_total ottl,
o.sales_rep_id sid, c.credit_limit cl, c.cust_email cem
FROM orders o, customers c
WHERE o.customer_id = c.customer_id;
并可视化为:
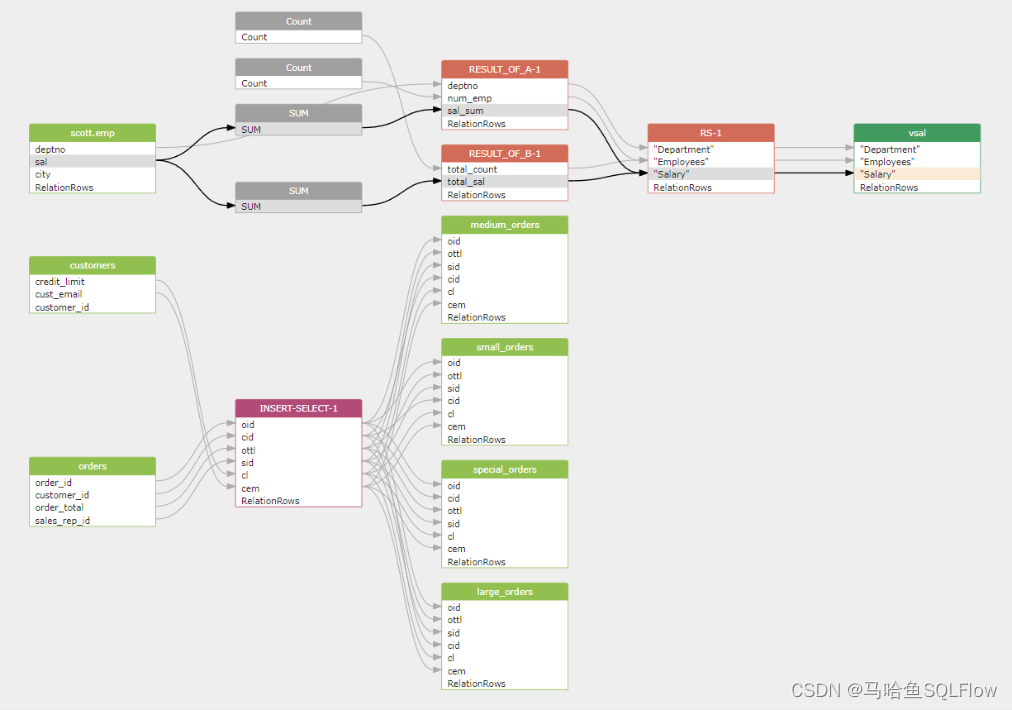
Oracle PL/SQL Data Lineage
python dlineage.py /t oracle /f samlples/oracle_plsql.sql /graph

The source code of this sample Oracle PL/SQL.
Able to analyze dynamic SQL to get data lineage (Postgres stored procedure)
CREATE OR REPLACE FUNCTION t.mergemodel(_modelid integer)
RETURNS void
LANGUAGE plpgsql
AS $function$
BEGINEXECUTE format ('INSERT INTO InSelectionsSELECT * FROM AddInSelections_%s', modelid);END;
$function$

Nested CTE with star columns (Snowflake SQL sample)
python dlineage.py /t snowflake /f samlples/snowflake_nested_cte.sql /graph

The snowflake SQL source code of this sample.
分析 DDL, 自动画出 ER Diagram
通过执行这条命令,
python dlineage.py /t sqlserver /f samples/sqlserver_er.sql /graph /er
我们可以自动获得下面这个 SQL Server 数据库的 ER Diagram.
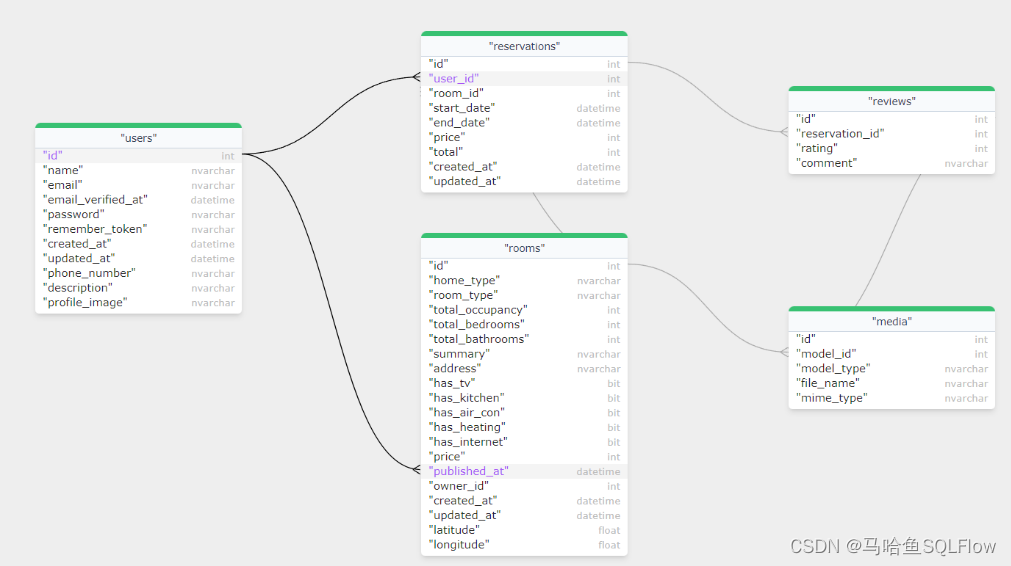
The DDL script of the above ER diagram is here.
Try your own SQL scripts
You may try more SQL scripts in your own computer without any internet connection by cloning this python data lineage repo
git clone https://github.com/sqlparser/python_data_lineage.git
- No database connection is needed.
- No internet connection is needed.
You only need a JDK and a python interpreter to run the Gudu SQLFlow lite version for python.
step 1 环境准备
-
安装python3
安装完python3后,还需要安装python依赖组件jpype。
-
安装 java jdk, 要求jdk1.8及以上版本
以ubuntu操作系统下安装为例:
检查jdk版本:
java -version。如果未安装或版本小于1.8,则需要安装jdk1.8:
sudo apt install openjdk-8-jdk如果报错:
Unable to locate package openjdk-8-jdk则执行以下命令安装:
sudo add-apt-repository ppa:openjdk-r/ppa apt-get update sudo apt install openjdk-8-jdk
step 2 打开web服务
切换到本项目widget目录,执行以下命令启动web服务:
python -m http.server 8000
浏览器内打开以下网址验证是否启动成功:http://localhost:8000/
注意:如果要修改8000端口,需要同时在dlineage.py里修改widget_server_url
step 3 执行python脚本
切换到本项目根目录,即dlineage.py所在目录,执行以下命令:
python dlineage.py /f test.sql /graph
此命令,会将test.sql进行血缘分析,并打开一个浏览器页面,图形化方式展示血缘分析结果。
dlineage.py 支持的命令参数说明:
/f: 可选, sql文件./d: 可选, 包含sql文件的文件夹路径./j: 可选, 返回包含join关系的结果./s: 可选, 简单输出,忽略中间结果./topselectlist: 可选, 简单输出,包含最顶端的输出结果./withTemporaryTable: 可选, 简单输出,包含临时表./i: 可选, 与/s选项相同,但将保留SQL函数生成的结果集,此参数将与/s/topselectlist+keep SQL函数生成结果集具有相同的效果。/showResultSetTypes: 可选, 带有指定结果集类型的简单输出,用逗号分隔, 结果集类型有: array, struct, result_of, cte, insert_select, update_select, merge_update, merge_insert, output, update_set pivot_table, unpivot_table, alias, rs, function, case_when/if: 可选, 保留所有中间结果集,但删除 SQL 函数生成的结果集。/ic: 可选, 忽略输出中的坐标./lof: 必选, 将孤立列链接到第一个表./traceView: 可选,只输出源表和视图的名称,忽略所有中间数据./text: 可选, 如果只使用/s 选项,则在文本模式下输出列依赖项./json: 可选, 打印json格式输出./tableLineage [/csv /delimiter]: 可选, 输出表级血缘关系./csv: 可选, 输出csv格式的列一级的血缘关系./delimiter: 可选, 输出csv格式的分隔符./t: 必选, 指定数据库类型. 支持 access,bigquery,couchbase,dax,db2,greenplum, gaussdb, hana,hive,impala,informix,mdx,mssql,sqlserver,mysql,netezza,odbc,openedge,oracle,postgresql,postgres,redshift,snowflake,sybase,teradata,soql,vertica the default value is oracle/env: 可选, 指定一个 metadata.json 来获取数据库元数据信息./transform: 可选, 输出关系转换码./coor: 可选, 输出关系转换坐标,但不输出代码./defaultDatabase: 可选, 指定默认database./defaultSchema: 可选, 指定默认schema./showImplicitSchema: 可选, 显示间接schema./showConstant: 可选, 显示常量./treatArgumentsInCountFunctionAsDirectDataflow: 可选,将 count 函数中的参数视为直接数据流./filterRelationTypes: 可选, 过滤关系类型,支持 fdd,fdr,join,call,er,如果有多个关系类型用英文半角逗号分隔./graph: 可选, 打开一个浏览器页面,图形化方式展示血缘分析结果/er: 可选, 打开一个浏览器页面,图形化方式展示ER图
从各种数据库中导出元数据
SQLFlow ingester 可以中数据库中导出元数据,交给 Gudu SQLFlow 进行数据血缘分析。
SQLFlow ingester 的使用文档
Trobule shooting
1.脚本执行报错:SystemError: java.lang.ClassNotFoundException: org.jpype.classloader.DynamicClassLoader
Traceback (most recent call last):
File "/home/grq/python_data_lineage/dlineage.py", line 231, in <module>
call_dataFlowAnalyzer(args)
File "/home/grq/python_data_lineage/dlineage.py", line 20, in call_dataFlowAnalyzer
jpype.startJVM(jvm, "-ea", jar)
File "/usr/lib/python3/dist-packages/jpype/_core.py", line 224, in startJVM
_jpype.startup(jvmpath, tuple(args),
SystemError: java.lang.ClassNotFoundException: org.jpype.classloader.DynamicClassLoader
这个问题在ubuntu系统预装的python3 jpype环境中常见,原因是在/usr/lib/python3/dist-packages/目录下缺少org.jpype.jar。
需要将org.jpype.jar 复制到/usr/lib/python3/dist-packages/目录下。
cp /usr/share/java/org.jpype.jar /usr/lib/python3/dist-packages/org.jpype.jar
这篇关于马哈鱼SQLFlow Lite的python版本的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







