本文主要是介绍记录 | ubuntu nm命令的基本使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是nm命令
nm命令是linux下针对某些特定文件的分析工具,能够列出库文件(.a、.lib)、目标文件(*.o)、可执行文件的符号表。
nm命令的常用参数
-A 或 -o 或 --print-file-name:打印出每个符号属于的文件
-a 或 --debug-syms:显示调试符号。
-B:等同于–format=bsd,用来兼容MIPS的nm。
-C 或 --demangle:将低级符号名解码(demangle)成用户级名字。这样可以使得C++函数名具有可读性。
-D 或 --dynamic:显示动态符号。该任选项仅对于动态目标(例如特定类型的共享库)有意义。
-f forma 或 --format=formatt:使用format格式输出。format可以选取bsd、sysv或posix,该选项在GNU的nm中有用。默认为bsd。
-g 或 --extern-only:仅显示外部符号。
-n 、-v 或 --numeric-sort:按符号对应地址的顺序排序,而非按符号名的字符顺序。
-p 或 --no-sort:按目标文件中遇到的符号顺序显示,不排序。
-P 或 --portability:使用POSIX.2标准输出格式代替默认的输出格式。等同于使用任选项-f posix。
-s 或 --print-armap:当列出库中成员的符号时,包含索引。索引的内容包含:哪些模块包含哪些名字的映射。
-r 或 --reverse-sort:反转排序的顺序(例如,升序变为降序)。
--size-sort:按大小排列符号顺序。该大小是按照一个符号的值与它下一个符号的值进行计算的。
-t radix 或 --radix=radix:使用radix进制显示符号值。radix只能为“d”表示十进制、“o”表示八进制或“x”表示十六进制。
--target=bfdname:指定一个目标代码的格式,而非使用系统的默认格式。
-u 或 --undefined-only:仅显示没有定义的符号(那些外部符号)。
-l 或 --line-numbers:对每个符号,使用调试信息来试图找到文件名和行号。对于已定义的符号,查找符号地址的行号。对于未定义符号,查找指向符号重定位入口的行号。如果可以找到行号信息,显示在符号信息之后。
-V 或 --version:显示nm的版本号。
--help:显示nm的任选项。
举个栗子
- 编写源文件test.c
#include <stdio.h>const char ch = 'x';
int uninit;
int init = 10;void function() {int *ref = &init;static int sta_int = 10;printf("%c", ch);
}- 编译test.c文件 生成test.o
gcc -c test.c- 用nm命令分析符号表
nm -n test.o(-n以地址排序,方便查看)
输出结果:
U putchar
0000000000000000 R ch
0000000000000000 T function
0000000000000000 D init
0000000000000004 d sta_int.2182
0000000000000004 C uninit各列信息的含义:
第一列:符号值,即该符号的起始地址
第二列:符号类型,各字母代表什么类型在下一小节中介绍
第三列:符号名称
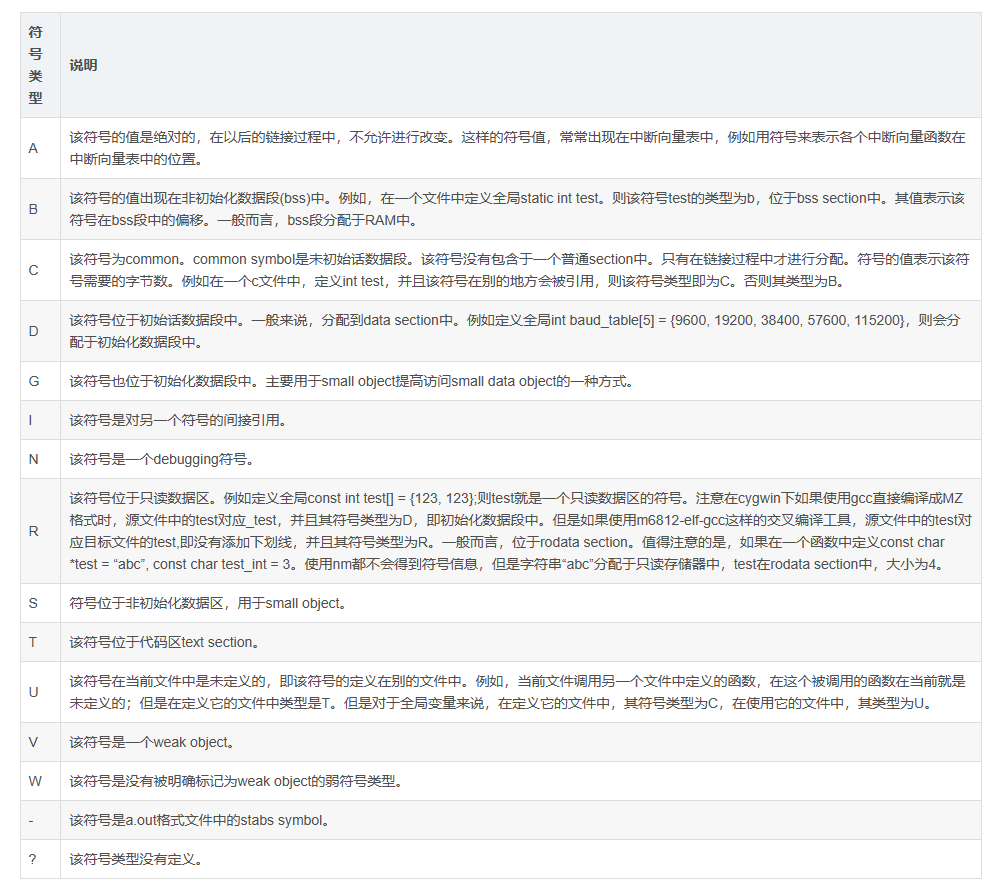
输出符号类型详解
- 符号类型大写代表全局符号,小写代表本地符号
这篇关于记录 | ubuntu nm命令的基本使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






