本文主要是介绍【极数系列】Flink配置参数如何获取?(06),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- gitee码云地址
- 简介概述
- 01 配置值来自.properties文件
- 1.通过路径读取
- 2.通过文件流读取
- 3.通过IO流读取
- 02 配置值来自命令行
- 03 配置来自系统属性
- 04 注册以及使用全局变量
- 05 Flink获取参数值Demo
- 1.项目结构
- 2.pom.xml文件如下
- 3.配置文件
- 4.项目主类
- 5.运行查看相关日志
gitee码云地址
直接下载解压可用 https://gitee.com/shawsongyue/aurora.git
模块:aurora_flink
主类:GetParamsStreamingJob
简介概述
1.几乎所有的批和流的 Flink 应用程序,都依赖于外部配置参数。这些配置参数可以用于指定输入和输出源(如路径或地址)、系统参数(并行度,运行时配置)和特定的应用程序参数(通常使用在用户自定义函数)。
2.为解决以上问题,Flink 提供一个名为 Parametertool 的简单公共类,其中包含了一些基本的工具。请注意,这里说的 Parametertool 并不是必须使用的。Commons CLI 和 argparse4j 等其他框架也可以非常好地兼容 Flink。
3.**ParameterTool**定义了一组静态方法,用于读取配置信息。该工具类内部使用了 Map` 类型,这样使得它可以很容易地与你的配置集成在一起。
01 配置值来自.properties文件
1.通过路径读取
//定义文件路径
String propertiesFilePath = "E:\\project\\aurora_dev\\aurora_flink\\src\\main\\resources\\application.properties";//方式一:直接使用内置工具类
ParameterTool parameter_01 = ParameterTool.fromPropertiesFile(propertiesFilePath);
String jobName_01 = parameter_01.get("jobName");
logger.info("方式一:读取配置文件中指定的key值={}",jobName_01);
2.通过文件流读取
//定义文件路径
String propertiesFilePath = "E:\\project\\aurora_dev\\aurora_flink\\src\\main\\resources\\application.properties";//方式二:使用文件
File propertiesFile = new File(propertiesFilePath);
ParameterTool parameter_02 = ParameterTool.fromPropertiesFile(propertiesFile);
String jobName_02 = parameter_02.get("jobName");
logger.info("方式二:读取配置文件中指定的key值={}",jobName_02);
3.通过IO流读取
//定义文件路径
String propertiesFilePath = "E:\\project\\aurora_dev\\aurora_flink\\src\\main\\resources\\application.properties";//方式三:使用IO流
InputStream propertiesFileInputStream = new FileInputStream(new File(propertiesFilePath));
ParameterTool parameter_03 = ParameterTool.fromPropertiesFile(propertiesFileInputStream);
String jobName_03 = parameter_03.get("jobName");
logger.info("方式三:读取配置文件中指定的key值={}",jobName_03);
02 配置值来自命令行
tips:在idea的命令行传参,格式:–jobName program_job_aurora
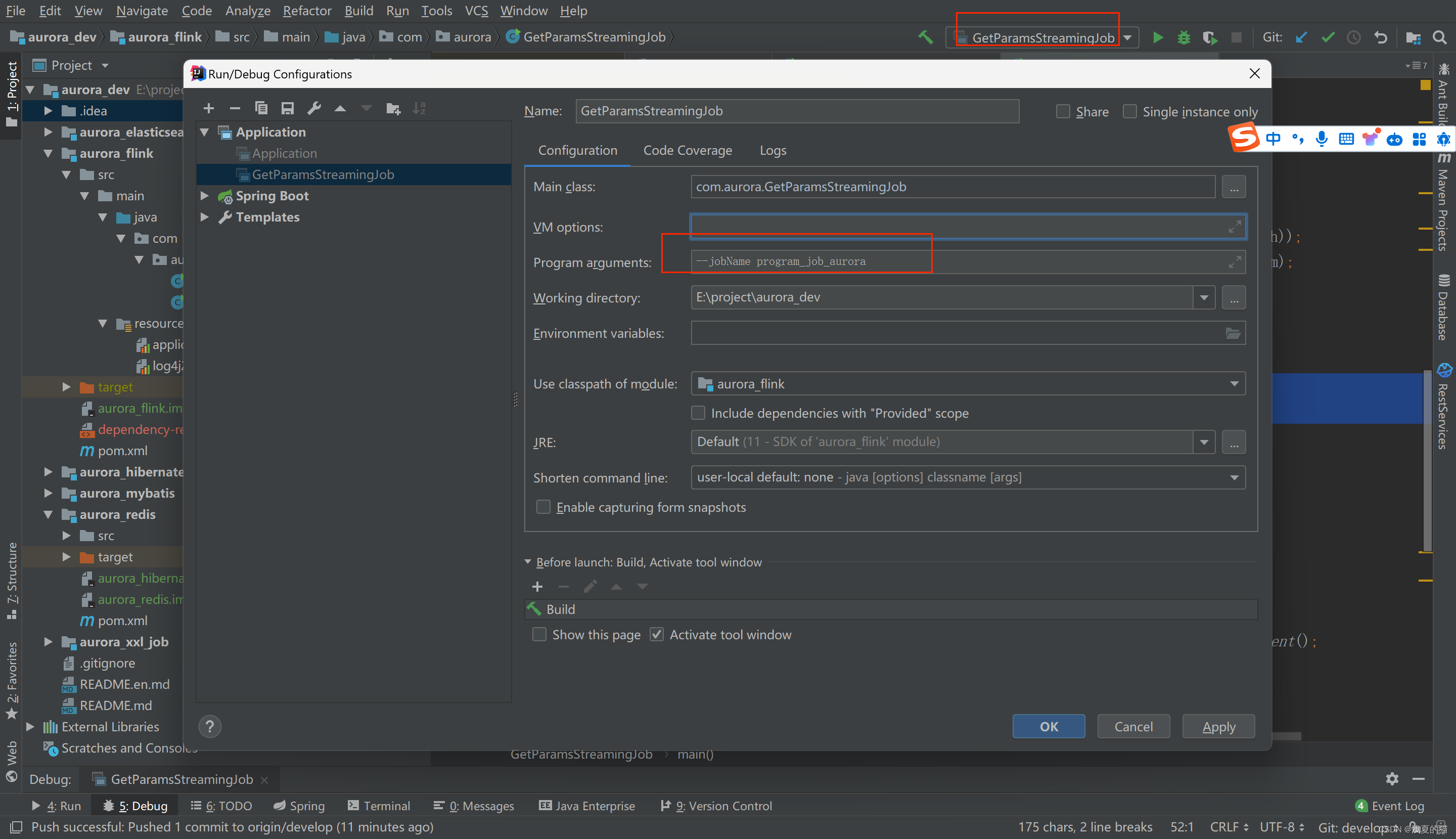
ParameterTool parameter_04 = ParameterTool.fromArgs(args);
String jobName_04 = parameter_04.get("jobName");
logger.info("方式四:命令行传参key值={}",jobName_04);
03 配置来自系统属性
tips:在idea的的jvm系统参数设置,格式:-Dinput=hdfs:///mydata
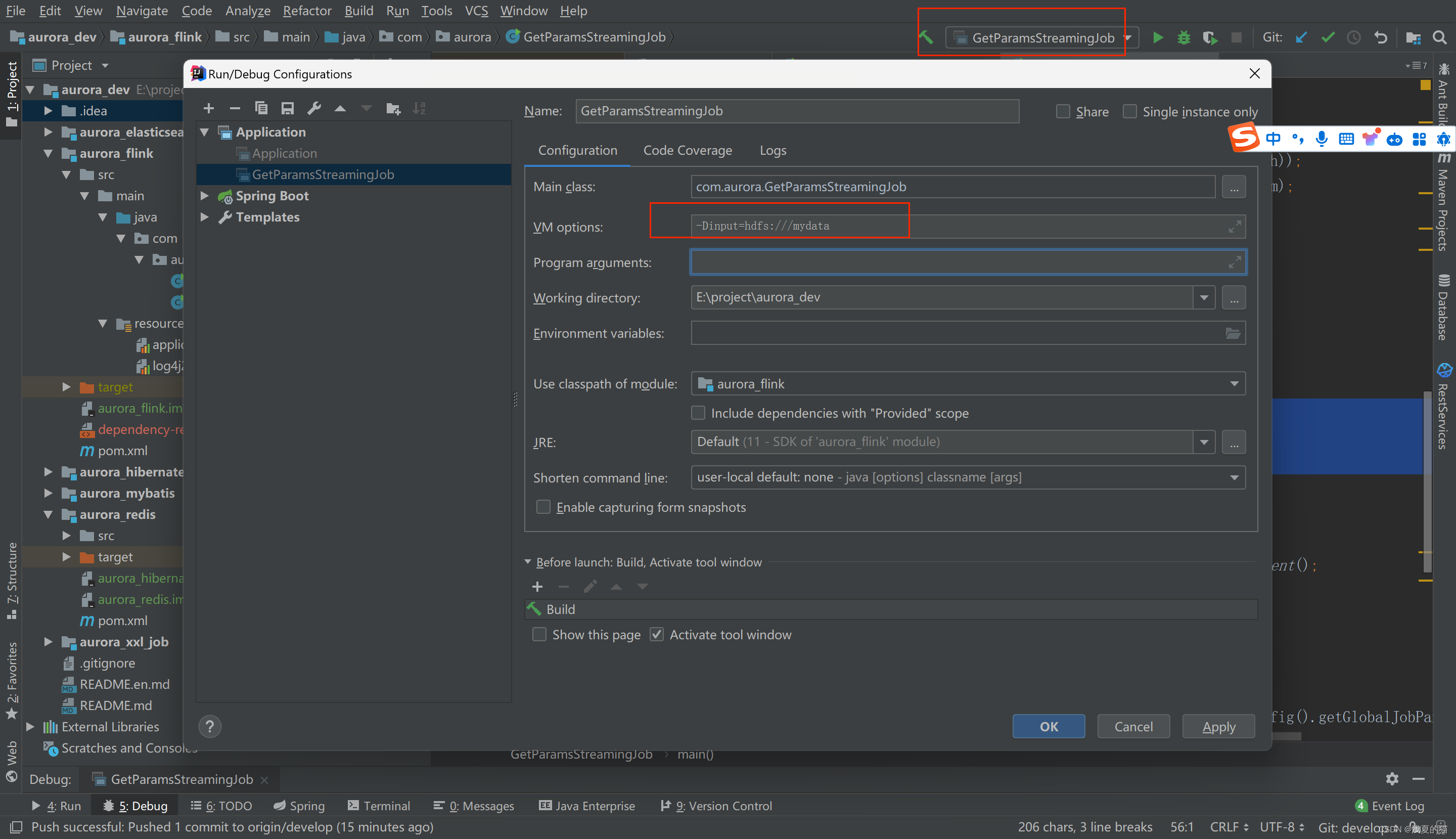
//方式五:获取jvm参数值
ParameterTool parameter_05 = ParameterTool.fromSystemProperties();
String jobName_05 = parameter_05.get("input");
logger.info("方式五:获取jvm参数key值={}",jobName_05);
04 注册以及使用全局变量
注意:Flink全局变量仅支持在富函数中使用,即Rich开头的类使用
//定义文件路径
String propertiesFilePath = "E:\\project\\aurora_dev\\aurora_flink\\src\\main\\resources\\application.properties";//直接使用内置工具类获取参数
ParameterTool parameter_01 = ParameterTool.fromPropertiesFile(propertiesFilePath);//方式六:注册全局参数final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.getConfig().setGlobalJobParameters(parameter_01);//在任意富函数中均可以获取,注意!注意!注意!只有富文本函数才可以使用//1.创建富函数RichFlatMapFunction<String, String> richFlatMap = new RichFlatMapFunction<>() {@Overridepublic void flatMap(String s, Collector<String> collector) throws Exception {//获取运行环境ParameterTool parameters = (ParameterTool) getRuntimeContext().getExecutionConfig().getGlobalJobParameters();//获取对应的值String jobName = parameters.getRequired("jobName");logger.info("方式六:获取全局注册参数key值={}",jobName_05);}};//2.创建数据集ArrayList<String> list = new ArrayList<>();list.add("001");list.add("002");list.add("003");//3.把有限数据集转换为数据源DataStreamSource<String> dataStreamSource = env.fromCollection(list).setParallelism(1);//4.执行富文本处理dataStreamSource.flatMap(richFlatMap);//5.启动程序env.execute();
05 Flink获取参数值Demo
1.项目结构
2.pom.xml文件如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.xsy</groupId><artifactId>aurora_flink</artifactId><version>1.0-SNAPSHOT</version><!--属性设置--><properties><!--java_JDK版本--><java.version>11</java.version><!--maven打包插件--><maven.plugin.version>3.8.1</maven.plugin.version><!--编译编码UTF-8--><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><!--输出报告编码UTF-8--><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><!--json数据格式处理工具--><fastjson.version>1.2.75</fastjson.version><!--log4j版本--><log4j.version>2.17.1</log4j.version><!--flink版本--><flink.version>1.18.0</flink.version><!--scala版本--><scala.binary.version>2.11</scala.binary.version><!--log4j依赖--><log4j.version>2.17.1</log4j.version></properties><!--通用依赖--><dependencies><!-- json --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>${fastjson.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><!--================================集成外部依赖==========================================--><!--集成日志框架 start--><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>${log4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-api</artifactId><version>${log4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>${log4j.version}</version></dependency><!--集成日志框架 end--></dependencies><!--编译打包--><build><finalName>${project.name}</finalName><!--资源文件打包--><resources><resource><directory>src/main/resources</directory></resource><resource><directory>src/main/java</directory><includes><include>**/*.xml</include></includes></resource></resources><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.1.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>org.apache.flink:force-shading</exclude><exclude>org.google.code.flindbugs:jar305</exclude><exclude>org.slf4j:*</exclude><excluder>org.apache.logging.log4j:*</excluder></excludes></artifactSet><filters><filter><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>org.xsy.sevenhee.flink.TestStreamJob</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins><!--插件统一管理--><pluginManagement><plugins><!--maven打包插件--><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>${spring.boot.version}</version><configuration><fork>true</fork><finalName>${project.build.finalName}</finalName></configuration><executions><execution><goals><goal>repackage</goal></goals></execution></executions></plugin><!--编译打包插件--><plugin><artifactId>maven-compiler-plugin</artifactId><version>${maven.plugin.version}</version><configuration><source>${java.version}</source><target>${java.version}</target><encoding>UTF-8</encoding><compilerArgs><arg>-parameters</arg></compilerArgs></configuration></plugin></plugins></pluginManagement></build><!--配置Maven项目中需要使用的远程仓库--><repositories><repository><id>aliyun-repos</id><url>https://maven.aliyun.com/nexus/content/groups/public/</url><snapshots><enabled>false</enabled></snapshots></repository></repositories><!--用来配置maven插件的远程仓库--><pluginRepositories><pluginRepository><id>aliyun-plugin</id><url>https://maven.aliyun.com/nexus/content/groups/public/</url><snapshots><enabled>false</enabled></snapshots></pluginRepository></pluginRepositories></project>
3.配置文件
(1)application.properties
jobName=job_aurora
jobMemory=1024
taskName=task_aurora
(2)log4j2.properties
rootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmprootLogger.level=INFO
rootLogger.appenderRef.console.ref=ConsoleAppender
appender.console.name=ConsoleAppender
appender.console.type=CONSOLE
appender.console.layout.type=PatternLayout
appender.console.layout.pattern=%d{HH:mm:ss,SSS} %-5p %-60c %x - %m%n
log.file=D:\\tmp
4.项目主类
package com.aurora;import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;/*** @description flink获取外部参数作业** @author 浅夏的猫* @datetime 15:54 2024/1/28
*/
public class GetParamsStreamingJob {private static final Logger logger = LoggerFactory.getLogger(GetParamsStreamingJob.class);public static void main(String[] args) throws Exception {//定义文件路径String propertiesFilePath = "E:\\project\\aurora_dev\\aurora_flink\\src\\main\\resources\\application.properties";//方式一:直接使用内置工具类ParameterTool parameter_01 = ParameterTool.fromPropertiesFile(propertiesFilePath);String jobName_01 = parameter_01.get("jobName");logger.info("方式一:读取配置文件中指定的key值={}",jobName_01);//方式二:使用文件File propertiesFile = new File(propertiesFilePath);ParameterTool parameter_02 = ParameterTool.fromPropertiesFile(propertiesFile);String jobName_02 = parameter_02.get("jobName");logger.info("方式二:读取配置文件中指定的key值={}",jobName_02);//方式三:使用IO流InputStream propertiesFileInputStream = new FileInputStream(new File(propertiesFilePath));ParameterTool parameter_03 = ParameterTool.fromPropertiesFile(propertiesFileInputStream);String jobName_03 = parameter_03.get("jobName");logger.info("方式三:读取配置文件中指定的key值={}",jobName_03);//方式四:命令行传参格式:--jobName program_job_auroraParameterTool parameter_04 = ParameterTool.fromArgs(args);String jobName_04 = parameter_04.get("jobName");logger.info("方式四:命令行传参key值={}",jobName_04);//方式五:获取jvm参数值ParameterTool parameter_05 = ParameterTool.fromSystemProperties();String jobName_05 = parameter_05.get("input");logger.info("方式五:获取jvm参数key值={}",jobName_05);//方式六:注册全局参数final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.getConfig().setGlobalJobParameters(parameter_01);//在任意富函数中均可以获取,注意!注意!注意!只有富文本函数才可以使用//1.创建富函数RichFlatMapFunction<String, String> richFlatMap = new RichFlatMapFunction<>() {@Overridepublic void flatMap(String s, Collector<String> collector) throws Exception {//获取运行环境ParameterTool parameters = (ParameterTool) getRuntimeContext().getExecutionConfig().getGlobalJobParameters();//获取对应的值String jobName = parameters.getRequired("jobName");logger.info("方式六:获取全局注册参数key值={}",jobName_05);}};//2.创建数据集ArrayList<String> list = new ArrayList<>();list.add("001");list.add("002");list.add("003");//3.把有限数据集转换为数据源DataStreamSource<String> dataStreamSource = env.fromCollection(list).setParallelism(1);//4.执行富文本处理dataStreamSource.flatMap(richFlatMap);//5.启动程序env.execute();}}
5.运行查看相关日志

这篇关于【极数系列】Flink配置参数如何获取?(06)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








