本文主要是介绍【JAVA语言-第16话】集合框架(三)——Set、HashSet、LinkedHashSet、TreeSet集合的详细解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Set集合
1.1 概述
1.2 特点
1.3 HashSet集合
1.3.1 概述
1.3.2 哈希表
1.3.3 哈希值
1.3.4 练习
1.3.5 HashSet存储自定义类型元素
1.4 LinkedHashSet集合
1.4.1 概述
1.4.2 特点
1.4.3 练习
1.5 TreeSet集合
1.5.1 概述
1.5.2 练习
1.6 HashSet、LinkedHashSet、TreeSet 的异同点
Set集合
1.1 概述
java.util.Set:是一个接口,和List一样,也是继承自Collection,常用的实现类有TreeSet、HashSet,LinkedHashSet。
1.2 特点
- 存取无序,存储的顺便和取出的数据不一定一致。
- 没有索引,不能通过索引操作元素。
- 不可以存储重复的元素。相同元素的判断:哈希值相同,内容相同。
1.3 HashSet集合
1.3.1 概述
java.util.HashSet:在Java中,HashSet是一种基于哈希表的集合实现。它继承自AbstractSet类并实现了Set接口。HashSet类在内部使用哈希表来存储元素,并且不保证元素的顺序。它允许存储唯一的元素,不允许重复。HashSet提供了常量时间的查找、插入和删除操作,因此可以在大多数情况下提供高效的性能。
1.3.2 哈希表
在jdk1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一个哈希值的元素都存储在一个链表中,但是当位于一个链表中的元素较多,即哈希值相等的元素较多时,通过Key值依次查找的效率较低;所以在jdk1.8中,哈希表存储采用数组+链表/红黑树实现,当链表的长度超过8时,将链表转换为红黑树,这样大大减少了查找时间。

1.3.3 哈希值
是一个十进制整数,由系统随机给出(就是对象的地址,是一个逻辑地址,是模拟出来得到的地址,不是数据实际存储的物理地址),在Object类中有一个方法,可以获取对象的哈希值。
public native int hashCode():返回该对象的哈希码值。
toString方法的源码:内部就是调用hashCode()方法
public String toString(){
return getClass().getName() + "@" + Integer.toHaxString(hashCode());
}
1.3.4 练习
package com.zhy.coll;import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;public class TestHashSet {public static void main(String[] args) {//多态,接口引用 指向 实现类对象Set<Integer> set = new HashSet<>();//往Set集合中添加元素,Set和List一样继承了Collection,所有两个类操作元素有着相似的方法set.add(10);set.add(20);set.add(30);//猜猜:这个元素能不能存储进Set集合?set.add(10);//打印Set集合印证一下//输出:初始化Set集合:[20, 10, 30]//明明添加了4个元素,但是最终Set集合中只有三个,这就是Set区别于List的地方,前者是不允许存储重复数据的//且存储是10,20,30,但是输出且不是按照存储数据打印,这也是Set区别于List的地方,前者是无序的System.out.println("初始化Set集合:" + set);//遍历集合,可以使用迭代器或者增强for循环//1.使用迭代器Iterator<Integer> iterator = set.iterator();while(iterator.hasNext()){Integer integer = iterator.next();System.out.print(integer + " ");}//2.使用增强forfor(Integer integer : set){System.out.print(integer + " ");}}
}
1.3.5 HashSet存储自定义类型元素
Set集合保证元素唯一:(String,Integer,...Student,Person),自定义的类如果想要使用Set集合存储,必须重写hashCode方法和equals方法,才能过滤掉重复的数据。
源代码:
package com.zhy.coll;import java.util.Objects;public class Persion {private String name;private int age;public Persion() {}public Persion(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}/*** 自定义类型,重写equals方法* 比较规则:name 和 age 内容都相同,返回true,否则,返回false* @param o* @return*/@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Persion persion = (Persion) o;if (age != persion.age) return false;return name != null ? name.equals(persion.name) : persion.name == null;}/*** 获取对象的hashCode,必须和equals一起重写* @return*/@Overridepublic int hashCode() {int result = name != null ? name.hashCode() : 0;result = 31 * result + age;return result;}/*** 重写toString,返回对象的内容,如果不重写,默认对象的地址* @return*/@Overridepublic String toString() {return "Persion{" +"name='" + name + '\'' +", age=" + age +'}';}
}
package com.zhy.coll;import java.util.HashSet;public class TestPersion {public static void main(String[] args) {//使用HashSet存储String类型的数据//排除重复元素规则:首先比较两个值的hashCode是否相同,其次比较两个值的内容是否相同//如果两种情况都相同,HashSet会判定为这两个值是同一个元素,只会存储一个//如果hashCode相同,内容不相同,那么会以链表的形式存储在一个hashCode下面HashSet<String> set1 = new HashSet<>();String str1 = new String("abc");String str2 = new String("abc");String str3 = new String("重地");String str4 = new String("通话");System.out.println("str1的hashCode:" + str1.hashCode());System.out.println("str2的hashCode:" + str2.hashCode());System.out.println("str3的hashCode:" + str3.hashCode());System.out.println("str4的hashCode:" + str4.hashCode());System.out.println("str1 和 str2是否是同一个元素:" + (str1.hashCode() == str2.hashCode() && str1.equals(str2)));System.out.println("str3 和 str4是否是同一个元素:" + (str3.hashCode() == str4.hashCode() && str3.equals(str4)));set1.add(str1);set1.add(str2);set1.add(str3);set1.add(str4);System.out.println("初始化String类型的Set集合:" + set1);System.out.println("========================================================");//使用HashSet存储自定义类型Persion的数据,为了保证Set集合不重复存储的特性,自定义类型必须重写hashCode和equals方法//比较规则:// 根据name和age获取唯一的hashCode值,然后在比较两个对象的名称+年龄是否相同// 二者都相同,代表同一个对象,不重复存储HashSet<Persion> set2 = new HashSet<>();Persion p1 = new Persion("张三",18);Persion p2 = new Persion("张三",18);Persion p3 = new Persion("李思",28);System.out.println("p1的hashCode:" + p1.hashCode());System.out.println("p2的hashCode:" + p2.hashCode());System.out.println("p3的hashCode:" + p3.hashCode());System.out.println("p1 和 p2是否是同一个元素:" + (p1.hashCode() == p2.hashCode() && p1.equals(p2)));set2.add(p1);set2.add(p2);set2.add(p3);System.out.println("初始化Persion类型的Set集合:" + set2);}
}
输出结果:

1.4 LinkedHashSet集合
1.4.1 概述
java.util.LinkedHashSet:在Java中,LinkedHashSet是一种集合类,它是HashSet的子类。它继承了HashSet的特性,同时还保持了元素的插入顺序。与HashSet不同的是,LinkedHashSet使用链表来维护集合中元素的顺序。
1.4.2 特点
底层是一个哈希表(数组+链表/红黑树)+链表:多了一条链表(记录元素的存储顺序),保证元素有序。
1.4.3 练习
源代码:
package com.zhy.coll;import java.util.Iterator;
import java.util.LinkedHashSet;public class TestLinkedHashSet {public static void main(String[] args) {//创建集合,存储Integer类型的数据LinkedHashSet<Integer> linkedHashSet = new LinkedHashSet<Integer>();//往集合中添加数据linkedHashSet.add(10);linkedHashSet.add(20);linkedHashSet.add(30);linkedHashSet.add(40);linkedHashSet.add(20);//遍历集合,迭代器或者增强forSystem.out.print("使用迭代器遍历集合:");Iterator<Integer> iterator = linkedHashSet.iterator();while (iterator.hasNext()){Integer integer = iterator.next();System.out.print(integer + " ");}}
}
输出结果:
查看集合的数据,不仅遍历的顺序和添加的顺序一致,还过滤掉了重复数据。

1.5 TreeSet集合
1.5.1 概述
java.util.TreeSet:在Java中,TreeSet是一个实现了Set接口的有序集合。它是通过红黑树数据结构实现的,可以保证元素按照自然排序或者通过Comparator进行排序。TreeSet不允许重复元素,并且可以高效地进行插入、删除和查找操作。由于TreeSet是有序的,因此它提供了一些额外的方法,如获取最小元素、获取最大元素、获取小于等于某个值的最大元素等。
1.5.2 练习
源代码:
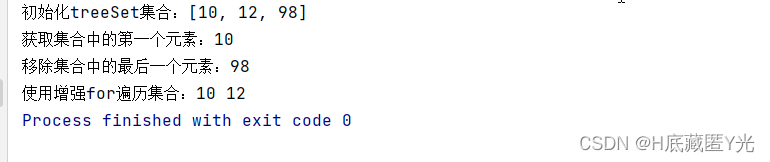
package com.zhy.coll;import java.util.TreeSet;public class TestTreeSet {public static void main(String[] args) {TreeSet<Integer> treeSet = new TreeSet<>();treeSet.add(12);treeSet.add(98);treeSet.add(10);System.out.println("初始化treeSet集合:" + treeSet);Integer first = treeSet.first();System.out.println("获取集合中的第一个元素:" + first);Integer integer = treeSet.pollLast();System.out.println("移除集合中的最后一个元素:" + integer);System.out.print("使用增强for遍历集合:");for (Integer i : treeSet){System.out.print(i + " ");}}
}
输出结果:
1.6 HashSet、LinkedHashSet、TreeSet 的异同点
HashSet、LinkedHashSet和TreeSet是Java中集合框架中Set集合的三个实现类,它们之间有一些异同点。
数据结构:
- HashSet是基于哈希表实现的集合,它使用哈希函数来确定元素的存储位置。
- LinkedHashSet是HashSet的子类,它在哈希表的基础上使用链表来维护元素的插入顺序。
- TreeSet是基于红黑树实现的集合,它能够自动将元素按照自然顺序或自定义的比较器顺序进行排序。
插入顺序:
- HashSet不保证元素的插入顺序,元素在集合中的位置是根据哈希函数计算得到的。
- LinkedHashSet保持元素的插入顺序,即元素按照插入的顺序进行迭代。
- TreeSet会根据元素的排序规则对元素进行排序,并且在遍历时按照排序后的顺序进行迭代。
排序:
- HashSet和LinkedHashSet不对元素进行排序,元素的顺序是根据哈希函数计算得到的。
- TreeSet会根据元素的自然顺序或自定义的比较器顺序对元素进行排序。
性能:
- HashSet的性能通常比较好,它提供了O(1)的常数时间复杂度的插入、删除和查找操作。
- LinkedHashSet的插入、删除和查找操作的性能稍微低于HashSet,因为它还需要维护插入顺序。
- TreeSet提供了O(log n)的时间复杂度的插入、删除和查找操作,它的性能较HashSet和LinkedHashSet要低。
总而言之,HashSet适用于需要快速插入、删除和查找操作的场景;LinkedHashSet适用于需要保持插入顺序的场景;TreeSet适用于需要对元素进行排序的场景。
这篇关于【JAVA语言-第16话】集合框架(三)——Set、HashSet、LinkedHashSet、TreeSet集合的详细解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





