本文主要是介绍多测师肖sir_高级金牌讲师___python之模块openpyxl,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
python之模块openpyxl
一、用python读写excel的强大工具:openpyxl
(1)定义: openpyxl模块是一个读写Excel 文档的Python库,openpyxl是一个比较综合的工具,能够同时读取和修改Excel文档。
(2)load_workbook 和workbook区别:
openpyxl.load_workbook(地址) - 打开给定的文件名并返回 工作簿
openpyxl.Workbook() - 新建一个 Workbook(工作簿)对象 ,即excel文件
(3)
(一)下载openpyxl的方式
方式一:python -m pip install openpyxl 或 pip install openpyxl
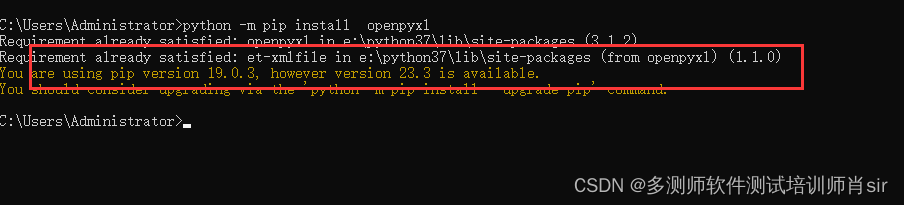
方式二:在pycharm中安装
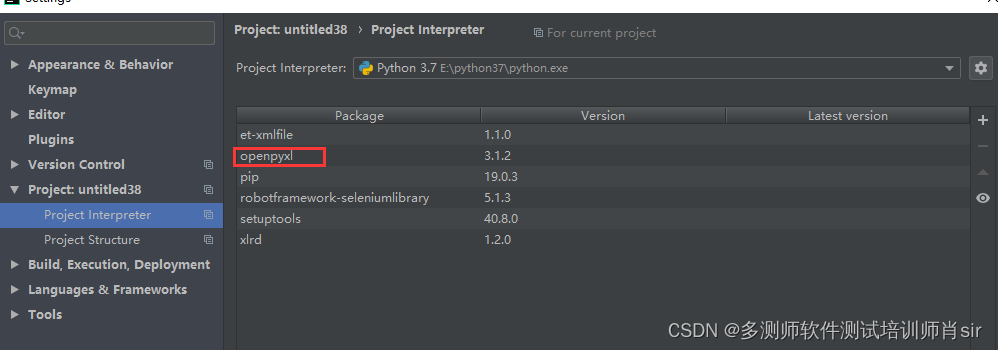
(二)openpyxl使用
1、新建一个文档
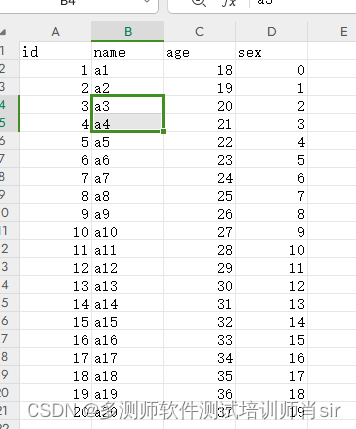
路径:
D:\Users\Desktop\hw\dcs35.xlsx
2、语句操作
(1)
注解:从工作簿中取得工作表
openpyxl.load_workbook(地址) - 打开给定的文件名并返回 工作簿
openpyxl.Workbook() - 新建一个 Workbook(工作簿)对象 ,即excel文件
工作簿对象.sheetnames - 获取当前工作簿中 所有表的名字
工作簿对象.active - 获取当前 活动表1 对应的Worksheet对象
工作簿对象[表名] - 根据表名获取指定 表对象
表对象.title - 获取表对象的 表名
表对象.max_row - 获取表的 最大有效行数
表对象.max_column - 获取表的 最大有效列数
from openpyxl import load_workbook
wb = load_workbook(r"E:\un\d.xlsx")
# print(wb.sheetnames) # 获取页面名
ym = wb['dcs'] #获取页面名
# print(wb.active) #获取当前活动的sheet名<Worksheet "dcs">
# v=ym['B1'].value #获取指定表格的数据
# print(ym.title) #dcs
print(ym.max_row) #21
print(ym.max_column) #3``
(2)从表中取得单元格
表对象[‘列号行号’] - 获取指定列的指定行对应的单元格对象(单元格对象是 Cell 类的对象,列号是从A开始,行号是从1开始)
表对象.cell(行号, 列号) - 获取指定行指定列对应的单元格(这儿的行号和列好号都可以用数字)
表对象.iter_rows() - 一行一行的取
表对象.iter_cols() - 列表一列的取
单元格对象.value - 获取单元格中的内容
单元格对象.row - 获取行号(数字1开始)
单元格对象.column - 获取列号(数字1开始)
单元格对象.coordinate - 获取位置(包括行号和列号)
案例:
获取单元格中的内容
content = a1.value
print(content)
调用表的 cell()方法时,可以传入整数 作为 row 和 column 关键字参数,也可以得到一个单元格
content2 = sheet.cell(2, 2).value
print(content2)
获取单元格的行和列信息
row = a1.row
print(‘行:’, row)
column = a1.column
print(‘列:’, column)
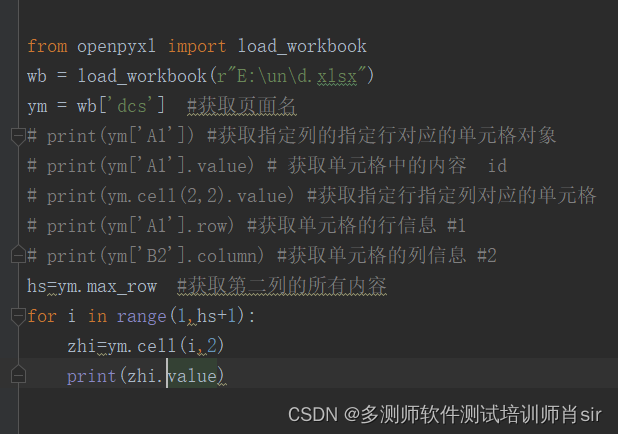
获取第二列的所有内容
row_num = sheet.max_row # 获取当前表中最大的行数
for row in range(1, row_num+1):
cell = sheet.cell(row, 2)
print(cell.value)
运行结果:
注意:在调用表的 cell()方法时,可以传入整数 作为 row 和 column 关键字参数,也可以得到一个单元格。
注意:第一行或第一列的对应的整数 是 1,不是 0。
截图:
二、写入数据
2.1 创建Workbook对象来创建Excel文件并保存
openpyxl.Workbook() - 创建空的 Excel 文件对应的工作簿对象
工作簿对象.save(文件路径) - 保存文件
工作簿对象.create_sheet(title, index) - 在指定工作簿中的指定位置(默认是最后)创建指定名字的表,并且返回表对象
工作簿对象.remove(表对象) - 删除工作簿中的指定表
表对象[位置] = 值 - 在表中指定位置对应的单元格中写入指定的值,位置是字符串:‘A1’(第1列的第一行)、‘B1’(第二列的第一行)
示例代码:
import openpyxl
创建空的Workbook对象
w_data = openpyxl.Workbook()
获取所有表名
print(w_data.sheetnames) # [‘Sheet’]
可知默认情况下,新建的Workbook对象对应的Excel 文件中只有一张名字是 ‘Sheet’ 的表
获取活动表
sheet_active = w_data.active
修改表的名字
sheet_active.title = ‘first_table’
保存至文件
w_data.save(filename=‘data/info.xlsx’)
新建表
w_data.create_sheet()
w_data.create_sheet()
for i in range(20):
wb.create_sheet()
print(w_data.sheetnames) # [‘first_table’, ‘Sheet’, ‘Sheet1’]
新建表时,从Sheet开始一直到Sheet n
w_data.create_sheet(‘second_table’)
工作簿对象.create_sheet(title, index) - 在指定工作簿中的指定位置(默认是最后)创建指定名字的表,并且返回表对象
w_data.create_sheet(‘third_table’, 1)
print(w_data.sheetnames) # [‘first_table’, ‘third_table’, ‘Sheet’, ‘Sheet1’, ‘second_table’]
删除表
w_data.remove(w_data[‘Sheet1’])
w_data.save(filename=‘data/info.xlsx’)
写入数据
w_data = openpyxl.load_workbook(‘data/info.xlsx’)
sheet = w_data[‘first_table’] # 获取表
sheet[‘A1’] = ‘姓名’
sheet[‘B1’] = ‘年龄’
sheet[‘C1’] = ‘性别’
sheet[‘A2’] = ‘张三’
sheet[‘B2’] = 25
sheet[‘C2’] = ‘男’
w_data.save(‘data/info.xlsx’)
运行结果:
2.2 案例分析一 :爬取数据并保存excel中
示例代码:
利用requests获取天行数据中疫情数据,并且将获取到的数据使用excel文件保存到表中。
import requests
import openpyxl
from openpyxl.utils import get_column_letter
1.获取数据
url = ‘http://api.tianapi.com/txapi/ncovabroad/index?key=c9d408fefd8ed4081a9079d0d6165d43’
rep = requests.get(url)
news_list = rep.json()[‘newslist’]
2.设置表头信息
headers = {‘continents’: (‘洲’, ‘A’),
‘provinceName’: (‘国家’, ‘B’),
‘currentConfirmedCount’: (‘现有确诊’, ‘C’),
‘confirmedCount’: (‘累计确诊’, ‘D’),
‘curedCount’: (‘治愈’, ‘E’),
‘deadCount’: (‘死亡’, ‘F’)}
3.创建工作表
wb = openpyxl.Workbook()
sheet = wb.active
4.写入数据
先写入第一行的表头
column_num = 1
for key in headers:
column = get_column_letter(column_num)
location = f’{column}1’
sheet[location] = headers[key][0]
column_num += 1
再从第二行开始写入爬取到的数据
row = 2
for news in news_list: # 遍历每条数据项,一个数据项对应一个字典
for key in news: # 遍历数据键值
if key in headers: # 保证键是表头中的某一项我们需要的数据
location = f’{headers[key][1]}{row}’ # 存在表中的位置
value = news[key] # 需要的数据
sheet[location] = value # 写入
row += 1
wb.save(filename=‘data/epidemic.xlsx’)
运行结果:
2.3 案例分析二: 操作单元格中内容样式并保存数据
示例代码:
import openpyxl
from openpyxl.styles import Font, PatternFill, Border, Side, Alignment # 字体、填充图案、边框、侧边、对齐方式
1.打开工作簿
data = openpyxl.load_workbook(‘data/体检表.xlsx’)
sheet = data.active
2.设置单元格字体样式
“”"
Font(
name=None, # 字体名,可以用字体名字的字符串
strike=None, # 删除线,True/False
color=None, # 文字颜色
size=None, # 字号
bold=None, # 加粗, True/False
italic=None, # 倾斜,Tue/False
underline=None # 下划线, ‘single’, ‘singleAccounting’, ‘double’,‘doubleAccounting’
)
“”"
创建字体对象,并调整合适的参数
font1 = Font(
name=‘微软雅黑’,
size=15,
italic=False,
color=‘ff0000’,
bold=False,
strike=False,
underline=‘single’,
)
设置指定单元格的字体
单元格对象.font = 字体对象
area = sheet[‘A1’:‘E1’]
for row in area:
for _ in row:
_.font = font1 # 调整字体
3.设置单元格填充样式
“”"
PatternFill(
fill_type=None, # 设置填充样式: ‘darkGrid’, ‘darkTrellis’, ‘darkHorizontal’, ‘darkGray’, ‘lightDown’, ‘lightGray’, ‘solid’, ‘lightGrid’, ‘gray125’, ‘lightHorizontal’, ‘lightTrellis’, ‘darkDown’, ‘mediumGray’, ‘gray0625’, ‘darkUp’, ‘darkVertical’, ‘lightVertical’, ‘lightUp’
# '深色网格“,”深色网格“,”深色水平“,”深色灰色“,”浅色向下“,”浅灰色“,”纯色“,”浅色网格“,”灰色125“,”浅色水平“,”浅色网格“,”深色向下“,”中灰色“,”灰色0625“,”深色向上“,”深色垂直“,”浅色垂直“,”浅色向上“
start_color=None# 设置填充颜色
)
“”"
设置填充对象
fill = PatternFill(fill_type=‘solid’, start_color=‘FFC0CB’)
设置单元格的填充样式
单元格对象.fill = 填充对象
area = sheet[‘A1’:‘E1’]
for row in area:
for _ in row:
_.fill = fill # 调整填充格式
4. 设置单元格对齐样式
创建对象
al = Alignment(
horizontal=‘right’, # 水平方向:center, left, right
vertical=‘top’, # 垂直方向: center, top, bottom
)
设置单元格的对齐方式
sheet[‘B2’].alignment = al
5. 设置边框样式
设置边对象(四个边的边可以是一样的也可以不同,如果不同就创建对个Side对象)
border_style取值(‘dashDot’,‘dashDotDot’, ‘dashed’,‘dotted’,‘double’,‘hair’, ‘medium’, ‘mediumDashDot’, ‘mediumDashDotDot’,‘mediumDashed’, ‘slantDashDot’, ‘thick’, ‘thin’)
单点划线,双点划线,点划线,双划线,头发,中划线,单点中划线,双点中划线,中划线,斜划线,粗划线,细划线
side = Side(border_style=‘thin’, color=‘000000’)
设置边框对象
left、right、top、bottom表示的是边框的四个边,四个边可以使用一个边对象
bd = Border(left=side, right=side, top=side, bottom=side)
设置单元格的边框
area = sheet[‘A1’:‘E1’]
for row in area:
for _ in row:
_.border = bd
6.设置单元格的宽度和高度
设置列宽
sheet.column_dimensions[‘A’].width = 10
设置行高
sheet.row_dimensions[1].height = 30
7. 保存
data.save(filename=‘data/体检表2.xlsx’)
运行结果:
2.4 案例分析三:将列表数据写入excel中
示例代码:
import openpyxl
import datetime
datas = [
(‘学号’, ‘姓名’, ‘年龄’, ‘专业’, ‘考试时间’),
(‘B00001’, ‘张1’, 18, ‘语文’, datetime.datetime(2019, 6, 18, 0, 0)),
(‘B00002’, ‘张2’, 19, ‘数学’, datetime.datetime(2019, 6, 19, 0, 0)),
(‘B00003’, ‘张3’, 20, ‘英语’, datetime.datetime(2019, 6, 20, 0, 0)),
(‘B00004’, ‘张4’, 21, ‘物理’, datetime.datetime(2019, 6, 21, 0, 0)),
(‘B00005’, ‘张5’, 22, ‘化学’, datetime.datetime(2019, 6, 22, 0, 0)),
(‘B00006’, ‘张6’, 23, ‘生物’, datetime.datetime(2019, 6, 23, 0, 0)),
(‘B00007’, ‘张7’, 24, ‘历史’, datetime.datetime(2019, 6, 24, 0, 0))
]
创建空的Workbook对象
w_data = openpyxl.Workbook()
获取活动表
sheet = w_data.active
for i in range(1, len(datas) + 1):
for j in range(1, 6):
sheet.cell(row=i, column=j, value=datas[i - 1][j - 1])
w_data.save(‘data/info.xlsx’)
运行结果:
2.5 案例分析四:将列表数据写入excel中的多个sheet中,并设置标题行
示例代码:
import openpyxl
import datetime
datas = [
(‘B00001’, ‘张1’, 18, ‘语文’, datetime.datetime(2019, 6, 18, 0, 0)),
(‘B00002’, ‘张2’, 19, ‘数学’, datetime.datetime(2019, 6, 19, 0, 0)),
(‘B00003’, ‘张3’, 20, ‘英语’, datetime.datetime(2019, 6, 20, 0, 0)),
(‘B00004’, ‘张4’, 21, ‘物理’, datetime.datetime(2019, 6, 21, 0, 0)),
(‘B00005’, ‘张5’, 22, ‘化学’, datetime.datetime(2019, 6, 22, 0, 0)),
(‘B00006’, ‘张6’, 23, ‘生物’, datetime.datetime(2019, 6, 23, 0, 0)),
(‘B00007’, ‘张7’, 24, ‘历史’, datetime.datetime(2019, 6, 24, 0, 0))
]
这篇关于多测师肖sir_高级金牌讲师___python之模块openpyxl的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




