本文主要是介绍论文阅读(5)利用C-UNet进行皮肤病变分割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- Skin Lesion Segmentation with C-UNet
- 摘要
- 1、引言
- 2、方法
- 2.1数据集
- 2.2 C-UNet 结构
- 2.3 训练
- 2.4 利用Dice损失函数进行微调
- 3、结果
- 4、讨论
Skin Lesion Segmentation with C-UNet
摘要
本文主要是为了解决皮肤病变分割的问题。C-UNet整合了类似Inception卷积模块,循环卷积块和空洞卷积。在用常用的交叉熵损失训练模型后,本文还应用了一种使用Dice损失的微调技术。利用条件随机场用于进一步平滑预测标签图。该模型较于U-Net拥有更好的分割效果和鲁棒性。
1、引言
恶性黑色素瘤是一种常见且具有威胁性的皮肤癌。它是世界上增长最快的癌症之一[1]。虽然目前已有一些先进的治疗方法,如放射治疗和免疫治疗,但晚期黑色素瘤的五年存活率仍低至15%。然而,对于早期黑色素瘤,5年存活率超过95%[3]。这一重大差异突出了黑色素瘤的及时诊断和治疗对患者生存的关键重要性。
恶性黑色素瘤在疾病的早期并不明显,很难通过肉眼观察来诊断。皮肤镜检查是目前早期诊断恶性黑色素瘤的最佳方法,皮肤镜手术也是通过解剖消除恶性黑色素瘤威胁的常用方法。然而,当医生使用皮肤镜图像进行诊断和治疗时,人工检查皮肤镜图像通常非常耗时和主观。因此,计算机辅助诊断(CAD)方法是必要的,可以大大提高诊断的效率和准确性。
皮肤镜图像中对皮肤病变的分割是皮肤病诊断的重要步骤[4][5]。皮肤科医生通过对痣的目视检查,利用临床评估工具如ABCD标准来诊断黑色素瘤,即检查皮损的不对称性、边界、颜色和演变过程[6]。最近,计算机视觉工具被引入,以辅助定量分析皮损。由于深度学习在医学领域的发展,已经有很多人尝试用全自动的方式对皮肤病变进行分割。
近年来,深度学习方法,特别是卷积神经网络(CNN)在医学图像诊断中得到了广泛的应用。完全卷积网络(FCN)[7]是图像分割领域的开创性工作。PSPNet[8]、DeepLab[9]和Mask-RCNN[10]进一步提高了深度神经网络在图像分割任务中的性能。在医学图像分割中,UNET是最流行的网络架构,已被广泛用于各种医学成像模式以及许多分割任务[11]。
本文是基于U-Net的改进。
2、方法
2.1数据集
我们采用ISIC 2018 挑战赛官方训练数据集,其中有2594张皮肤镜图像和相应的病变掩模[12]。我们取三分之二的图像作为训练集,留下三分之一的图像作为测试集。目的是在不同的背景下准确预测三种皮肤病变的二元掩模。病变类型包括痣、脂溢性角化病和黑色素瘤。除了官方的训练集,主办方还提供了100张图片的验证数据集和1000张图片的测试数据集。不过,验证数据集和测试数据集的真实掩模并未提供。参赛者可在比赛结束前在线提交成绩,最终排名以Jaccard指数为准。然而,由于在线提交在比赛结束后关闭,我们无法在官方测试数据集上评估我们的模型,因此无法将我们的结果与排行榜上的顶级结果进行比较。最后的结果是在我们的测试数据集上进行评估的。
由于图片的尺寸不一,我们首先将所有图片的尺寸调整为256×342。我们发现,网络在训练过程中往往偏向于深色区域,病变区域和非病变区域的对比不是很明显。因此,在数据增强中,我们采用直方图均衡法来增强图像的色彩对比度。作为网络的输入,我们将增强后的图像与原始图像相结合,以学习更多的特征。所以每个输入有六个通道。
2.2 C-UNet 结构
该结构修改了U-Net原始结构中的卷积和反卷积模块。
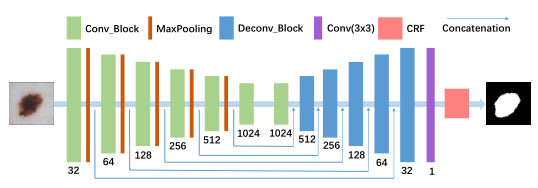

RCL为了增强模型综合上下文信息的能力。感觉和DenseNet的思路有点像。
- 本文采用了后处理操作-CRF来精细化分割结果。
2.3 训练
Adam优化器+batch_size 为8+初始学习率为0.0001,并使用学习率的指数衰减+每一层的卷积使用了p=0.9的dropout方法+训练时的损失函数为交叉熵损失函数,微调时使用Dice 损失函数。
2.4 利用Dice损失函数进行微调
除了使用交叉熵损失进行训练外,我们还应用了Dice finetune技术。也就是说,我们先用常用的交叉熵损失对模型进行训练,当验证损失不再减少后,再用Dice损失对模型进行微调。
该loss函数有0.8的前景Dice loss和0.2的背景Dice loss决定。
3、结果
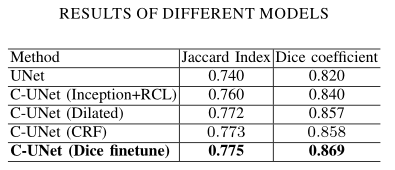
利用损失函数的微调得到不错的结果。作者希望能将该策略应用到其他分割 场景下。
4、讨论
下面讨论了一下实验过程中使用的其他技术:
我们用ResNet-101[17]、VGG16[18]等富特征模型代替原来的UNet编码器,并从ImageNet中预先训练好权重,我们只对解码器部分进行微调。与原始 UNet编码器相比,ResNet和VGG应该是在不同分辨率下抽象出复杂的特征。所以我们期望使用这些骨干作为编码器可以在复杂图像上获得更高的性能。但出乎我们意料的是,Jaccard指数急剧下降。同时在UNet损失函数中加入边界权重,也会导致分数略低。
基于检测的模型,如Mask-RCNN也在这个任务上进行了测试。以COCO数据集上预训练的ResNet101为骨干的Mask-RCNN模型在验证数据集上给出了0.65的Jaccard指数。Mask-RCNN最大的挑战之一是如何将小块的预测区域组合成一个大的掩模。我们减少预测区域的数量,并在推理中允许非常低的阈值,以保持非常大的边界框。否则,模型只保留高置信度分数的小区域。然后使用非最大抑制(NMS)将所有的边界框合并成一个大的边界框。在大多数图像中,其性能与普通的UNet相似,但在具有挑战性的图像中合并预测区域时,仍会遇到困难。
通过本文学习到了一些优秀的模型结构设计。
这篇关于论文阅读(5)利用C-UNet进行皮肤病变分割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




