本文主要是介绍让Oracle和SqlServer结婚(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
虚拟化封装
通过前面的展示,我们清楚的看到在hgsql中,oracle和sqlserver可以很好的工作在一起,这仅仅是解决了访问问题,虚拟集成的最终目的是以一种虚拟化的方式对外提供,最终用户不需要关心所访问的数据物理存储。Hgsql通过视图、同义词、存储过程和目录多种进行虚拟化的封装。
视图
我们前面提到的原生查询例子,我们可以保存为视图,sql如下:
create or replace view v_ora_sql_emp as
select empno ora_empno,
(#sqlserver select ename from emp where empno=&empno&) sql_ename
from (#oracle select * from emp where rownum < 5)
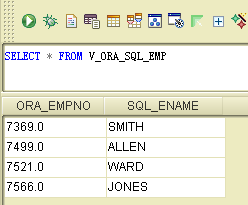
select * from v_ora_sql_emp
此时我们就可以直接查询 v_ora_sql_emp视图获取数据,而不用关心数据来源。
Hgsql的视图创建语法内容可以是一个程序块,这样就可以处理更为复杂的逻辑。这里暂不讨论。
同义词
同义词是对象的别名,我们前面在使用sqlserver的substring函数时,调用方式为substring@sqlserver,下面我们来创建一个同义词:
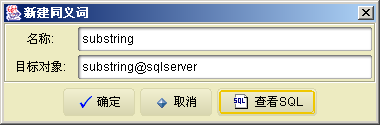
create synonym PUBLIC.substring for substring@sqlserver
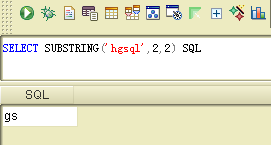
同义词创建完成后,我们就可以直接调用同义词了,sql引擎会自动做转换:
存储过程
存储过程是sql脚本程序块。我们也可以使用存储过程来实现上面同义词的功能,创建sql脚本如下:
create procedure substring(p_str,p_start,p_count) as
substring@sqlserver(p_str,p_start,p_count);
下面我们来使用我们的存储过程
select substring('hgsql',2,2) proc
使用存储过程,可以实现更为复杂的逻辑控制,下面我们对 p_start的参数做一个校验,sql脚本如下:
create or replace procedure substring(p_str,p_start,p_count) as
begin
if p_start is null then
raise 'p_start is null';
end if;
substring@sqlserver(p_str,p_start,p_count);
end
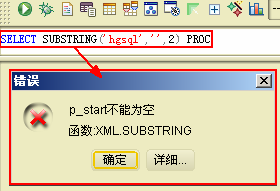
当我们调用 substring函数对参数p_start传入空值时,会抛出如下错误提示:
目录
连接到各种数据库,我们能够很容易的将表引入,进行调用,但我们在调用时必须知道模式,其实也就是要知道所属数据库,虽然我们可以使用同义词进行虚拟化,但灵活性还是非常有限。目录就是解决深度虚拟化的好工具。
我们创建一个mytable目录,如下:
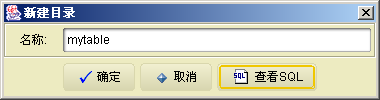
create directory //mytable
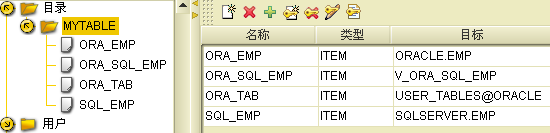
创建完成目录,我们就可以添加目录项了, sql如下:
alter directory //mytable add item ora_emp for oracle.emp;
alter directory //mytable add item ora_sql_emp for v_ora_sql_emp;
alter directory //mytable add item ora_tab for user_tables@oracle;
alter directory //mytable add item sql_emp for sqlserver.emp;
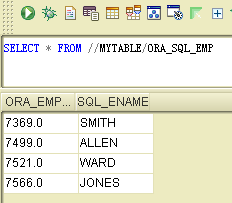
下面我们直接通过目录进行对象访问:
select * from //mytable/ora_sql_emp
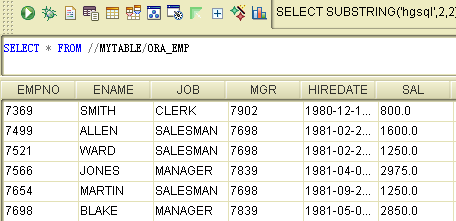
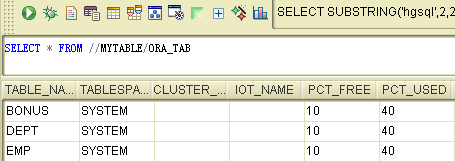
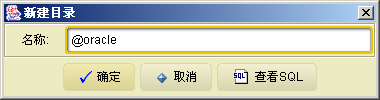
我们还可以创建一个特殊目录,格式为: @模式名,该目录会将远程的sqlhub中的目录和其它数据库中的模式映射为一个子目录使用,下面我们来创建指向oracle的目录,如下图:
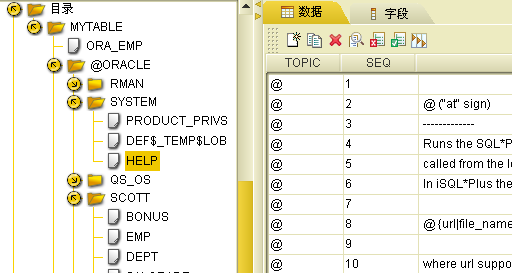
创建完成后,我们展开目录,发现 oracle的所有模式都自动展开,如下图:
我们可以直接查询目录下的资源,如下:
select * from //mytable/@oracle/system/help
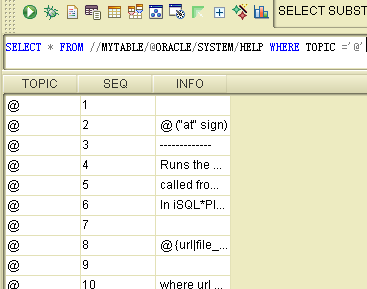
使用目录,我们可以对集成的数据进行灵活的组织,以资源的方式对外提供。
总结
上面展示的仅仅是针对 oracle和sqlserver,其它数据库也同样适用。Sqlhub解决的不仅仅是异构数据库之间的互访问题,它对任意数据源提供的基于sql的互相操作能力,例如:xml、html、excel、txt等。上面讨论到的视图、存储过程等使用也只是一个应用点。
上面 sql的运行环境为SQLHUB4.1版。
http://www.hgsql.com
sqlhub@163.com
这篇关于让Oracle和SqlServer结婚(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







