本文主要是介绍Linux进程间通信(IPC)机制之一:管道(Pipes)详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🎬慕斯主页:修仙—别有洞天
♈️今日夜电波:Nonsense—Sabrina Carpenter
0:50━━━━━━️💟──────── 2:43
🔄 ◀️ ⏸ ▶️ ☰
💗关注👍点赞🙌收藏您的每一次鼓励都是对我莫大的支持😍
目录
进程间通信介绍
进程间通信目的
进程间通信分类
什么是管道?
管道详解
匿名管道
匿名管道的创建
匿名管道的特性与情况
命名管道
指令级
代码级
🌰
进程间通信介绍
进程间通信目的
数据传输:一个进程需要将它的数据发送给另一个进程
资源共享:多个进程之间共享同样的资源。
通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
进程间通信分类
管道匿名管道、pipe、命名管道
System V IPC
System V 消息队列、System V 共享内存、System V 信号量
POSIX IPC
消息队列、共享内存、信号量、互斥量、条件变量、读写锁
以下是一些主要的进程间通信方式:
- 管道(Pipes):包括无名管道和命名管道。无名管道是半双工的,数据只能单向流动,通常用于有亲缘关系的进程间通信,如父子进程之间。命名管道则允许无亲缘关系的进程间通信。
- 消息队列(Message Queues):消息队列是由消息的链表组成,存放在内核中并由消息队列标识符标识。它允许进程之间发送格式化的消息。
- 信号量(Semaphores):信号量是一个计数器,可以用来控制多个进程对共享资源的访问,实现进程间的同步。
- 共享内存(Shared Memory):共享内存允许多个进程访问同一块内存区域,从而快速地共享数据。
- 套接字(Sockets):套接字支持不同主机上的两个进程进行通信,常用于网络编程中。它实际上不仅用于不同的主机进程间通信,还可以用于本地主机进程间通信。
什么是管道?
管道是一种在Linux中用于进程间通信的机制,它可以将一个进程的输出作为另一个进程的输入。
管道的概念来源于日常生活中的水管,就像水管可以将水从一个地方输送到另一个地方一样,管道在Linux系统中用于传递数据流。具体来说,管道可以分为两类:
- 无名管道(匿名管道):这是最初UNIX系统中使用的管道形式,通常用于有亲缘关系的进程间通信,如父子进程。无名管道是通过系统调用pipe()创建的,并且它们是半双工的,意味着数据只能在一个方向上流动。
- 命名管道(也称为FIFO):与无名管道不同,命名管道可以在不相关的进程之间进行通信。它们通过文件系统创建,并具有路径名,因此可以被任何知道该路径名的进程访问。
管道的大小是固定的,并且在创建时就已经确定。在Linux中,管道的大小是可以调整的,但是这通常需要重新编译内核或使用特定的系统调用来改变。
总结:我们把从一个进程连接到另一个进程的一个数据流称为一个“管道”。
管道详解
匿名管道
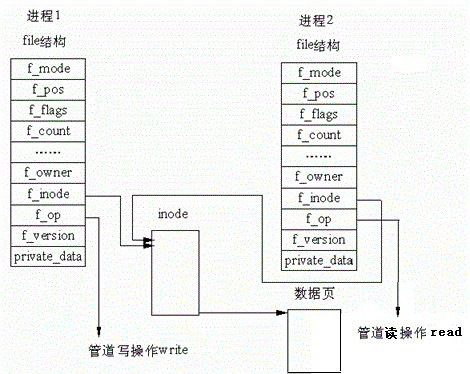
通常一个进程管理文件是通过PCB控制对应的struct files_struct 结构体,然后在struct files_struct 结构体中会存在一个struct files *fd_array[]存放着该进程打开文件的struct files,接着再通过对应的struct files指向对应的缓冲区等等,大致过程如下:

而当我们通过fork()创建子进程后,新创建的子进程会根据父进程的模板拷贝相关的内核数据结构,其中会经过类似“浅拷贝”的过程,使得子进程会指向内存中已经存在的且被父进程指向的文件,这就创建了两个进程指向同一份文件的效果。

而实际上,我们的同一个进程如果要对一个文件进行读写,一个struct file是不够的,这是因为我们在读或者写的位置可能是不同的,我们需要控制对应的读写,其中会包含对应的变量来保存读或者写的位置。因此是需要创建两个对应的 struct file来控制读写,只不过他们会指向同一个inode、同一个方法集、同一个缓冲区。你也会发现,当父子进程对屏幕用printf打印时,可能会出现数据错乱的情况,这是因为子进程发生了“浅拷贝”,双方的printf都是打印到同一个文件。那么当我们对一个文件进行读写,并且创建子进程的时候,子进程与父进程都会通过同样的两个 struct file指向同一个文件,当我们将他们间一个的读 struct file关闭,另一个的写 struct file关闭,这不就形成了一个进程连接到另一个进程的一个数据流吗?这就是管道的原理。当然, struct file中会有一个类似“引用计数”的功能来控制是否关闭对应的struct file。如下图:

匿名管道的创建
对此,理解了上面的过程后,我们继续理解接下来的创建管道的操作,系统中提供了对应的接口:
#include <unistd.h>
功能:创建一无名管道
原型
int pipe(int fd[2]);
参数
fd:文件描述符数组,其中fd[0]表示读端, fd[1]表示写端
返回值:成功返回0,失败返回错误代码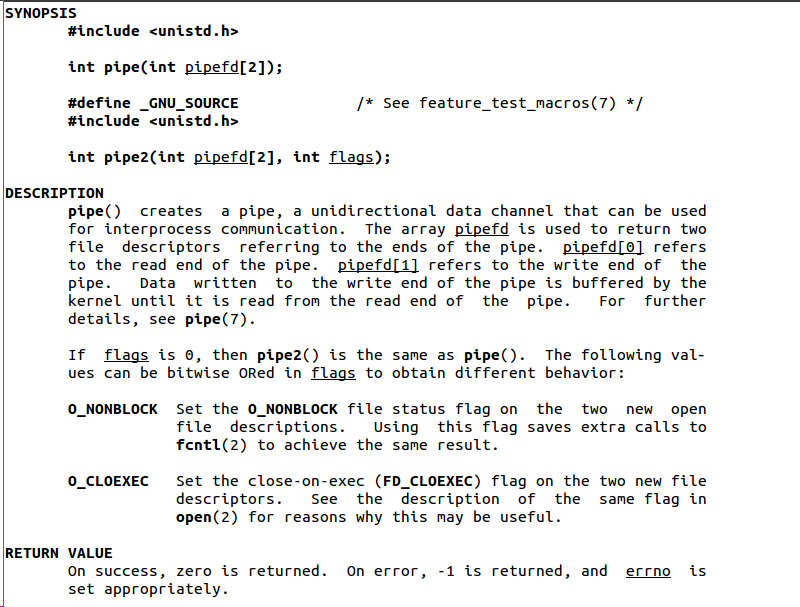
结合上面的知识,以父子进程间管道通信为例子,详细的创建过程如下:

我们通过fork()后,子进程会拷贝和父进程的内核数据结构,那么所有的子进程实际上的内核数据结构实际上都是差不多的。既然我们可以进行父子进程间的管道通信,我们当然也可以进行子与子之间、子与孙、父与孙之间的管道通信!如下为一个使用管道让父子进程间通信的例子:
#include <iostream>
#include <cassert>
#include <cstring>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <cstdio>
#include <cstdlib>#define MAX 1024using namespace std;int main()
{// 第1步,建立管道int pipefd[2]={0};int n=pipe(pipefd);assert(n==0);(void)n; // 防止编译器告警,意料之中,用assert,意料之外,用if// 第2步,创建子进程pid_t id=fork();if(id<0){perror("fork");return 1;}// 子写,父读// 第3步,父子关闭不需要的fd,形成单向通信的管道if (id == 0){//子关读close(pipefd[0]);int cnt = 0;while(true){//利用write写char message[MAX];snprintf(message, sizeof(message), "hello father, I am child, pid: %d, cnt: %d", getpid(), cnt);cnt++;write(pipefd[1], message, strlen(message));sleep(1);}cout << "child close w piont" << endl;exit(0);}// 父进程,关闭写close(pipefd[1]);char buffer[MAX];while(true){// sleep(2000);ssize_t n = read(pipefd[0], buffer, sizeof(buffer)-1);if(n > 0){buffer[n] = 0; // '\0', 当做字符串cout << getpid() << ", " << "child say: " << buffer << " to me!" << endl;}else if(n == 0){cout << "child quit, me too !" << endl;break;}cout << "father return val(n): " << n << endl;sleep(1);}cout << "read point close"<< endl;close(pipefd[0]);return 0;
}
匿名管道的特性与情况
// a. 管道的4种情况
// 1. 正常情况,如果管道没有数据了,读端必须等待,直到有数据为止(写端写入数据了)
// 2. 正常情况,如果管道被写满了,写端必须等待,直到有空间为止(读端读走数据)
// 3. 写端关闭,读端一直读取, 读端会读到read返回值为0, 表示读到文件结尾
// 4. 读端关闭,写端一直写入,OS会直接杀掉写端进程,通过想目标进程发送SIGPIPE(13)信号,终止目标进程
// b. 管道的5种特性
// 1. 匿名管道,可以允许具有血缘关系的进程之间进行进程间通信,常用与父子,仅限于此
// 2. 匿名管道,默认给读写端要提供同步机制 --- 了解现象就行
// 3. 面向字节流的 --- 了解现象就行
// 4. 管道的生命周期是随进程的
// 5. 管道是单向通信的,半双工通信的一种特殊情况命名管道
通过前面的知识点,我们知道匿名管道可以让有“血缘关系”的进程进行通信,那如果我们要让没有血缘关系、毫不相干的进程进行通信呢?这个时候就需要使用到命名管道了。对于命名管道,我们可以使用指令来创建,也可以使用代码来创建。下面分别介绍两种方式:
指令级
系统中的指令手册如下:



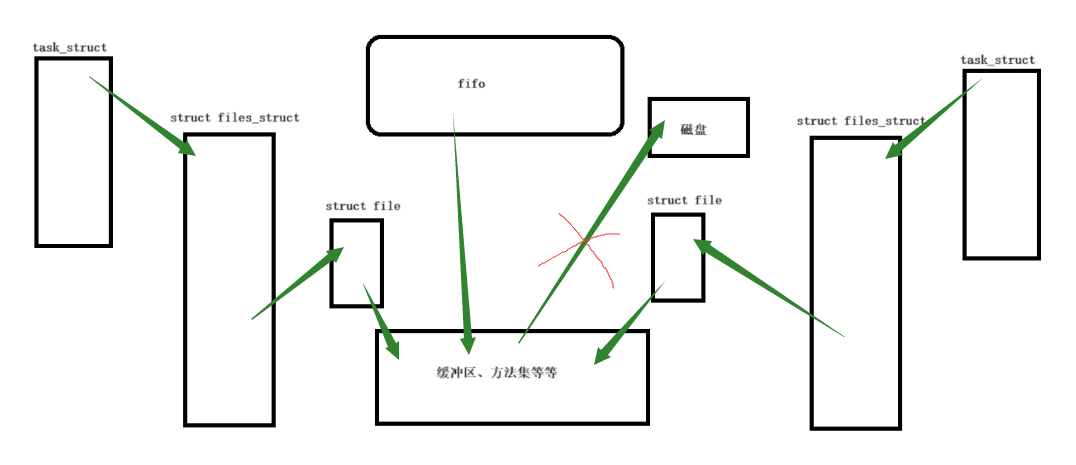
如上图所示,我们通过命名管道让两个毫不相干的进程进行了通信。需要注意的是:我们创建的命名管道虽然是一个文件,他是存在在磁盘上的。但是,他是没有大小的!
进程间相互通信的本质实际上是让不同的进程看到同一份资源,而命名管道的原理则是:因为路径是具有唯一性的,那么我们可以使用路径加文件名,来唯一的让不同的进程看到同一份资源。当我们让不同的进程看到了同一份资源,对应的进程struct file就会向匿名管道一样指向该文件的方法集、缓冲区等等,但是文件是不会对于缓冲区进行刷盘操作的,因为磁盘中并没有存储信息。大致的图示如下:
代码级
手册如下:

函数原型:
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);参数说明:
pathname:指定要创建的FIFO文件的路径名。mode:设置新创建的FIFO文件的权限模式,默认是0666。
返回值:
- 成功时返回0,失败时返回-1,并设置errno以指示错误类型。
使用场景:
- 当需要在进程间传递数据时,可以使用mkfifo创建命名管道,然后通过读写该管道来实现通信。
- 命名管道可以用于不同进程、不同主机甚至不同操作系统之间的通信。
注意事项:
- 在创建命名管道之前,需要确保路径中的目录已经存在,否则可能需要先创建这些目录。
- 在使用命名管道进行通信时,需要注意同步和互斥的问题,以避免数据的混乱和竞争条件。
- 由于命名管道存在于文件系统中,因此也需要考虑文件系统的权限和安全性问题。
🌰
server.cc
#include <iostream>
#include <cstring>
#include <cerrno>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define FILENAME "fifo"bool MakeFifo()
{int n = mkfifo(FILENAME, 0666);if(n < 0){std::cerr << "errno: " << errno << ", errstring: " << strerror(errno) << std::endl;return false;}std::cout << "mkfifo success... read" << std::endl;return true;
}int main()
{
Start:int rfd = open(FILENAME, O_RDONLY);if(rfd < 0){std::cerr << "errno: " << errno << ", errstring: " << strerror(errno) << std::endl;if(MakeFifo()) goto Start;else return 1;}std::cout << "open fifo success..." << std::endl;char buffer[1024];while(true){ssize_t s = read(rfd, buffer, sizeof(buffer)-1);if(s > 0){buffer[s] = 0;std::cout << "Client say# " << buffer << std::endl;}else if(s == 0){std::cout << "client quit, server quit too!" << std::endl;break;}}close(rfd);std::cout << "close fifo success..." << std::endl;return 0;
}
client.cc
#include <iostream>
#include <cstring>
#include <cerrno>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define FILENAME "fifo"int main()
{int wfd = open(FILENAME, O_WRONLY);if (wfd < 0){std::cerr << "errno: " << errno << ", errstring: " << strerror(errno) << std::endl;return 1;}std::cout << "open fifo success... write" << std::endl;std::string message;while (true){std::cout << "Please Enter# ";std::getline(std::cin, message);ssize_t s = write(wfd, message.c_str(), message.size());if (s < 0){std::cerr << "errno: " << errno << ", errstring: " << strerror(errno) << std::endl;break;}}close(wfd);std::cout << "close fifo success..." << std::endl;return 0;
}Makefile
.PHONY:all
all:server clientserver:server.ccg++ -o $@ $^ -std=c++11
client:client.ccg++ -o $@ $^ -std=c++11
.PHONY:clean
clean:rm -f server client fifo
感谢你耐心的看到这里ღ( ´・ᴗ・` )比心,如有哪里有错误请踢一脚作者o(╥﹏╥)o!

给个三连再走嘛~
这篇关于Linux进程间通信(IPC)机制之一:管道(Pipes)详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




