本文主要是介绍flyway使用配置参数和注意事项介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 业务场景
- 参数介绍
- initSqls
- baselineOnMigrate
- baselineVersion
- target
- validateOnMigrate
- SQL注意事项
业务场景
- 对于生产环境,随着项目版本迭代,数据库结构也会变动。如果一个项目在多个地方实施部署,且版本不一致,就需要一个方法来管理数据库结构。
- flyway是个简单易用的轻量级数据库版本管理工具,可以让我们像使用 Git 管理代码一样,对数据库版本和变动,进行详细的记录
- 使用flyway时,我们按照版本整理数据库SQL脚本,当发布新的项目版本时,同时发布SQL变动文件
- 举例说明,对于第一个正式版本,我们的SQL文件包含数据库表初始化SQL,数据的初始化SQL;对于第二个版本,我们需要数据库表结构变动的SQL。每一个SQL文件都带有版本号,在各地实施时,会根据基础版本号和schema表里记录的情况,自动进行数据库结构校验和更新,保持表结构一致。
- 对于新部署的项目,没有数据,可以不指定初始版本,直接从第一个数据库脚本开始执行,创建数据库,初始化数据,一直更新到需要的版本
- 对于已经在运行的项目,数据库是已有的,里面也有客户的数据,不需要走创建数据库和初始化数据的过程。这时候需要设置基础版本的版本号,在进行表结构更新时,就会忽略之前的版本的SQL文件,只执行需要更新的SQL文件
参数介绍
- 我的flyway的在spring boot应用里的application.yml配置
spring:datasource:type: com.zaxxer.hikari.HikariDataSourceurl: jdbc:postgresql://192.168.x.xx:5432/coreusername: xxxpassword: xxxxxxxhikari:poolName: Hikariauto-commit: falseflyway:enabled: trueschemas: publicencoding: UTF-8locations: classpath:db/migrationsql-migration-prefix: Vsql-migration-separator: __sql-migration-suffixes: .sqltable: flyway_schema_historybaseline-on-migrate: truevalidate-on-migrate: truebaseline-version: 2.0.0.1
- enabled:默认
true,是否启用flyway,设置为true,flyway才会生效 - locations:默认
classpath:db/migration,迁移脚本的位置 - schemas:由 Flyway 管理的schema的名称(区分大小写)
- encoding:默认
UTF_8,SQL 迁移的编码 - table:默认
flyway_schema_history,Flyway 将使用的架构历史表的名称。 - sqlMigrationPrefix:默认
V,SQL 迁移的文件名前缀 - sqlMigrationSuffixes:默认
.sql,SQL 迁移的文件名后缀 - sqlMigrationSeparator:默认
__,SQL 迁移的文件名分隔符 - repeatableSqlMigrationPrefix:默认
R,可重复 SQL 迁移的文件名前缀 - cleanDisabled:是否禁用数据库清理
- cleanOnValidationError:验证错误时是否自动调用clean
- baselineVersion:默认
1,执行基线时用于标记现有模式的版本 - target:应考虑迁移到的目标版本
- initSqls:获取连接后立即执行初始化连接的 SQL 语句
- baselineOnMigrate:迁移非空schema时是否自动调用基线
- validateMigrationNaming:默认
false,是否验证脚本不遵守正确命名约定的迁移和回调 - validateOnMigrate:默认
true,执行迁移时是否自动调用validate - 下面对于我有使用经验的,个人认为比较重要的几个参数,详细讲一下。
initSqls
- 对于初次部署的系统,可以使用flyway新建表和初始化数据,但是没法新建库
- 一开始想用
init-sqls参数建库,发现不行 - 一方面,在数据库连接参数
url里就要指定库名了,如果这时候库还没创建,连接这个库的时候就会报错了,也不会进行下去 - 另一方面,postgresql不支持
create xx if not exists的用法,没法判断库不存在再去创建 initSqls参数,可以指定一些SQL语句,获取连接后立即执行初始化连接的 SQL 语句- 我没有需要在连接后执行SQL语句的场景,暂时未使用此参数
baselineOnMigrate
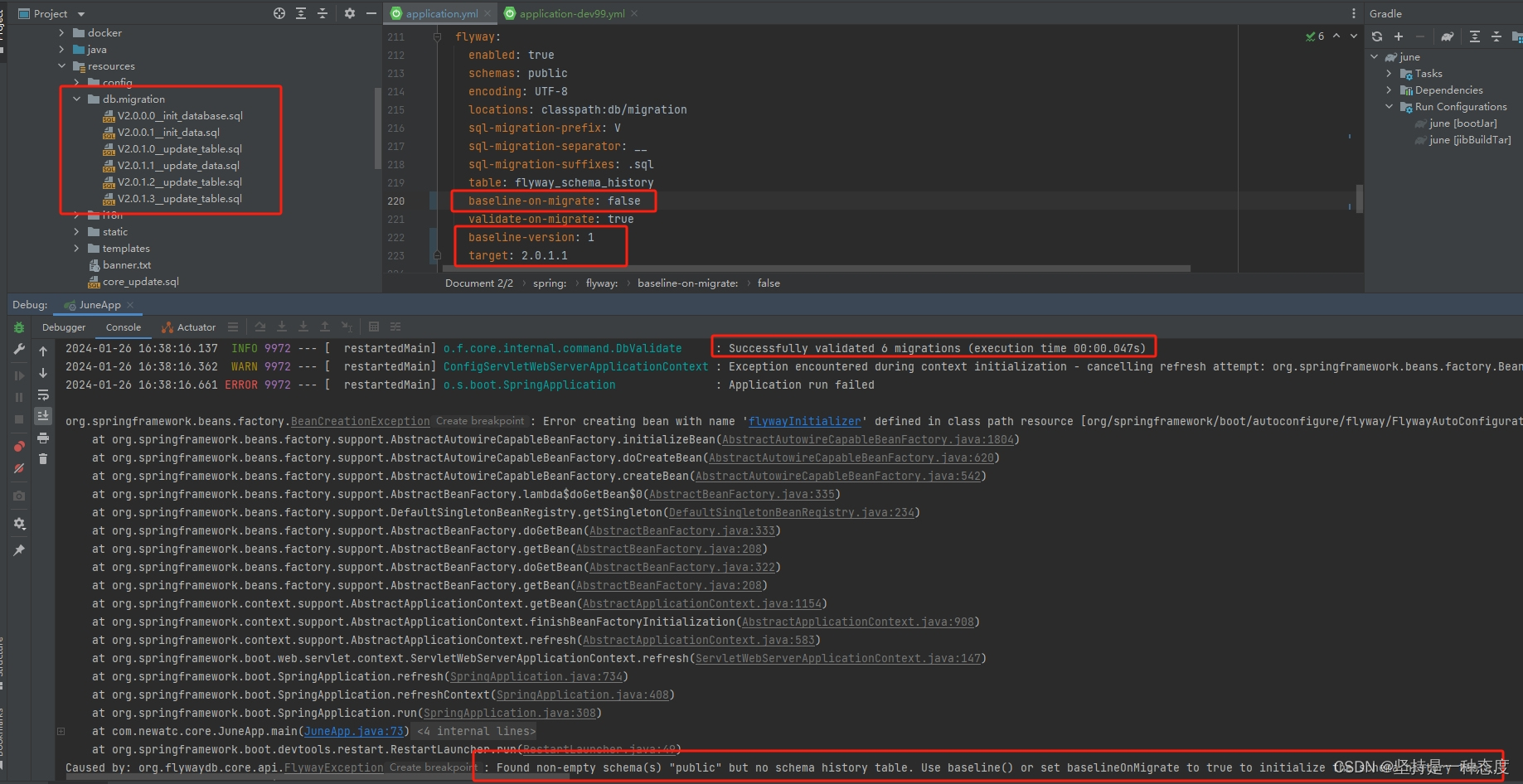
baseline-on-migrate参数,迁移非空schema时是否自动调用基线,主要是指数据库已存在,已经有数据库表和数据,此时开始使用flyway管理数据库的场景(此时flyway_schema_history表不存在)- schema(一般默认都是public)为空时,
baseline-on-migrate参数就没有意义了,为空就直接走创建过程了,维护表结构时,会首先创建flyway_schema_history表,再去逐个执行SQL脚本 - 在判断schema(一般默认都是public)非空时,设值为false,
flyway_schema_history表不存在,就返回报错
- 在判断schema(一般默认都是public)非空时,设置为true,会去创建
flyway_schema_history表,然后按照版本号逐个执行SQL文件
baselineVersion
baseline-version参数,指定基础版本,只有大于这个版本的SQL文件才会被检查和执行- 需要注意的是,只有在
flyway_schema_history表不存在时,baseline-version参数才会生效
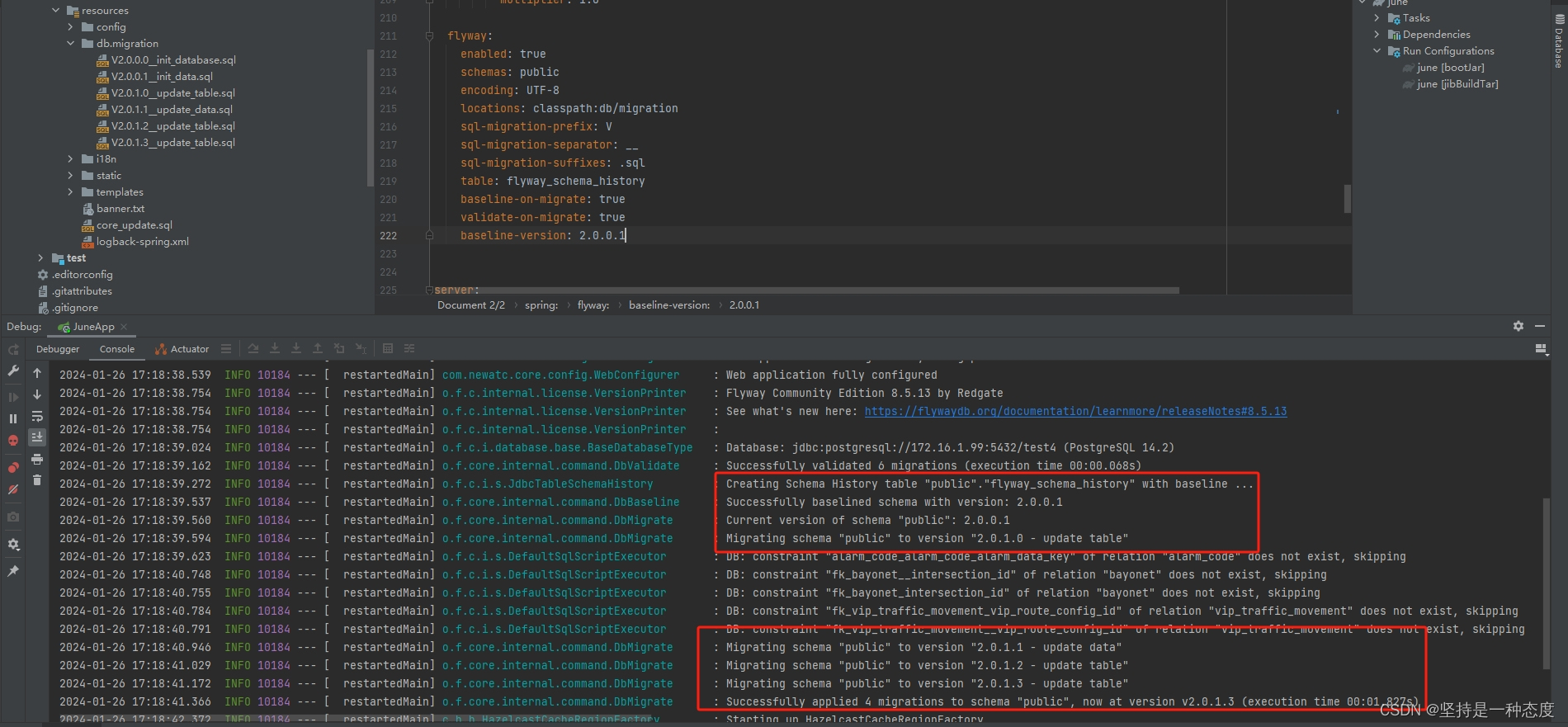
- 当
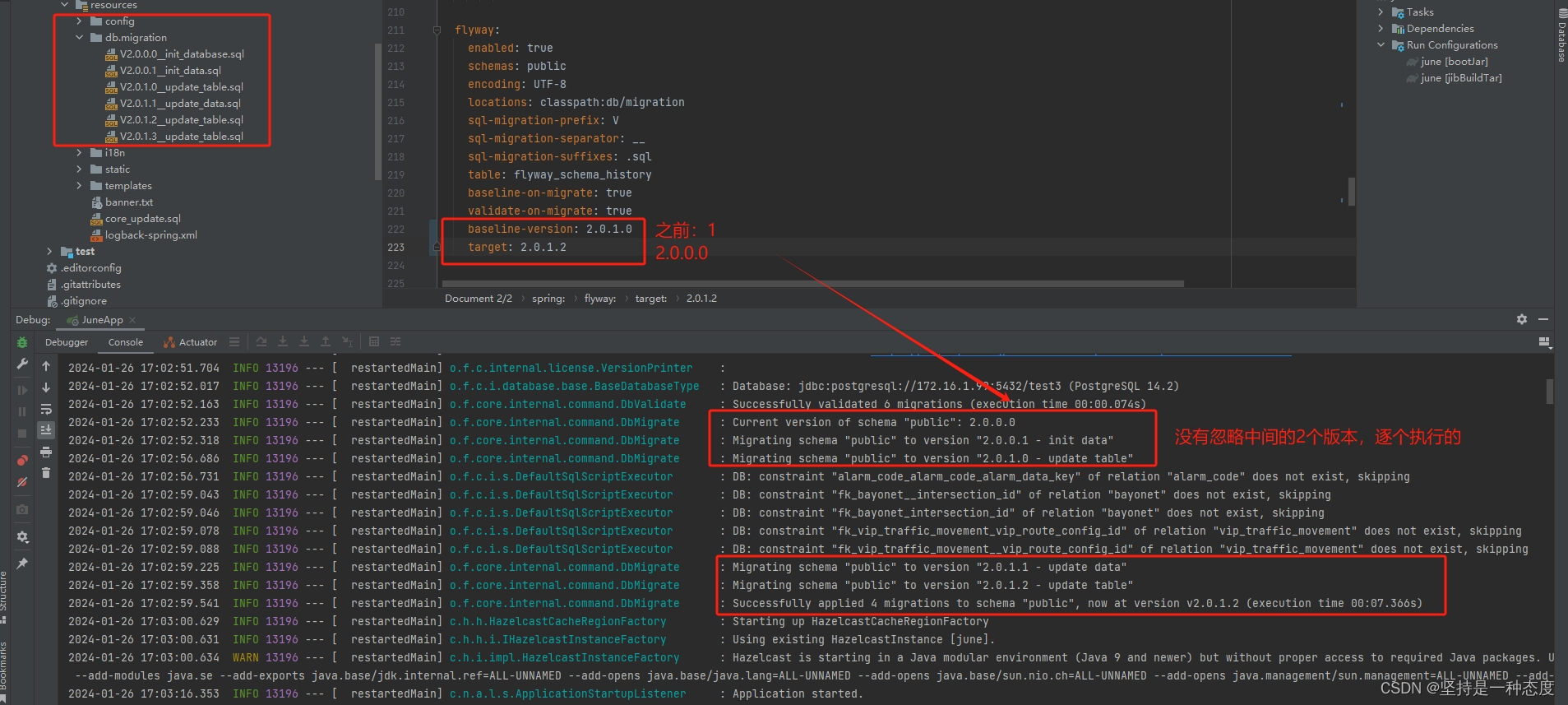
flyway_schema_history表存在时,会根据表里的记录继续进行升级,baseline-version参数没有意义 - 当schema表存在但表内容为空时,
baseline-version参数同样没有意义,会根据locations的SQL文件,逐个版本升级,直到最新或者target版本
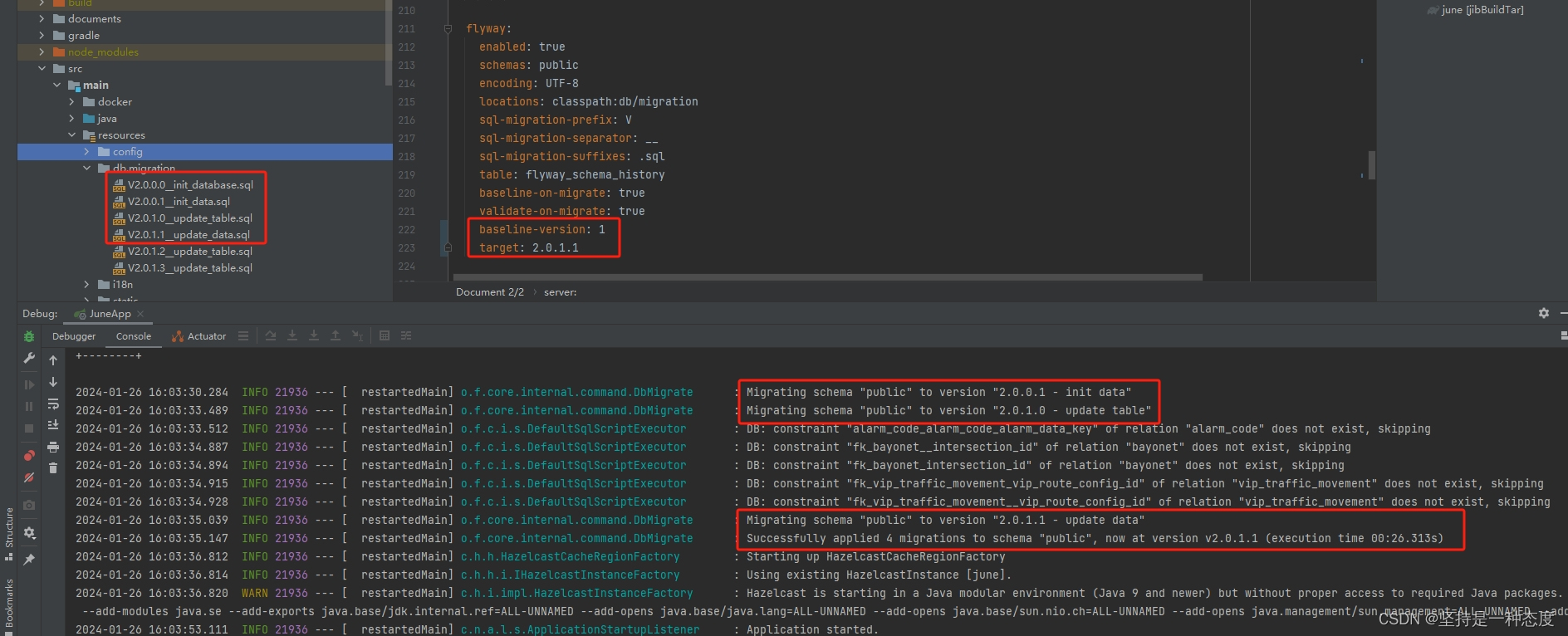
target
- 默认是迁移到最新版本,不配置时,就会根据
locations的SQL文件,逐个版本升级,一直到全部文件执行完成 - 如果指定版本号,则迁移到该版本,后续版本不升级
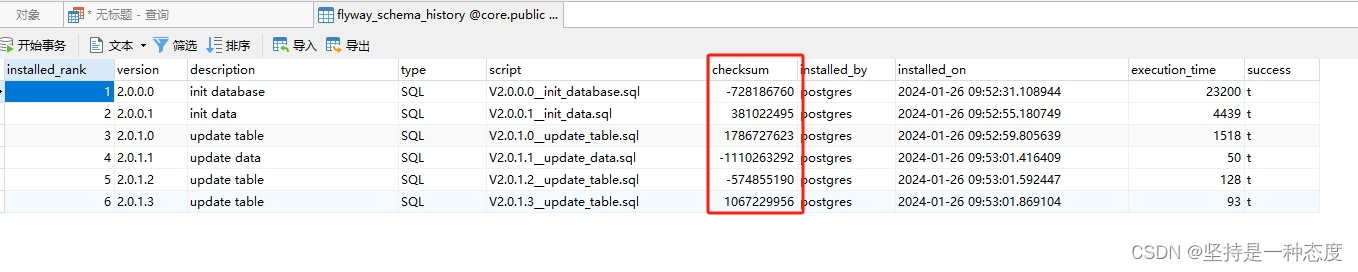
validateOnMigrate
- 默认
true,执行迁移时自动调用validate,对SQL文件进行校验 - 如果已有
flyway_schema_history,会对里面的记录逐个校验checksum字段的值 - 每个文件,会根据文件信息,生成一个 checksum 值,flyway在SQL文件执行时会在表里插入一条记录,包含checksum值
- 当已经同步过的SQL文件发生变动时, checksum 值就会和数据库里的记录对应不上,就会校验失败
SQL注意事项
- 保证SQL能正确执行,可以多加些判断
- 建表语句,新增字段的语句,可以多加一个
IF NOT EXISTS
CREATE TABLE IF NOT EXISTS "public"."sys_log"
("id" int8 NOT NULL,"op_desc" varchar(255) COLLATE "pg_catalog"."default","op_time" timestamp(6),CONSTRAINT "sys_log_pkey" PRIMARY KEY ("id")
);ALTER TABLE "public"."sys_setting" ADD COLUMN IF NOT EXISTS "enable_scheme_review" bool NOT NULL DEFAULT false;
- 删除语句,可以多加一个
IF EXISTS
ALTER TABLE "public"."wireless_security" DROP COLUMN IF EXISTS "dev_no";
ALTER TABLE "public"."bayonet" DROP CONSTRAINT IF EXISTS "fk_bayonet__intersection_id";
- postgresql不支持
create xx if not exists的用法,如果是增加外键、唯一键等操作,可以尝试先删除后新增,保证SQL一定执行成功
ALTER TABLE "public"."vip_traffic_movement" DROP CONSTRAINT IF EXISTS "fk_vip_traffic_movement__vip_route_config_id";
ALTER TABLE "public"."vip_traffic_movement" ADD CONSTRAINT "fk_vip_traffic_movement_vip_route_config_id" FOREIGN KEY ("vip_route_config_id") REFERENCES "public"."vip_route_config" ("id") ON DELETE NO ACTION ON UPDATE NO ACTION;这篇关于flyway使用配置参数和注意事项介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






