本文主要是介绍PostgreSQL技术大讲堂 - 第43讲:流复制原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

PostgreSQL从小白到专家,是从入门逐渐能力提升的一个系列教程,内容包括对PG基础的认知、包括安装使用、包括角色权限、包括维护管理、、等内容,希望对热爱PG、学习PG的同学们有帮助,欢迎持续关注CUUG PG技术大讲堂。
第43讲:流复制原理
PostgreSQL第43讲:1月27日(周六)19:30直播
内容1:流式复制的启动方式
内容2:如何在主服务器和备用服务器之间传输数据
内容3:主服务器如何管理多个备用服务器
内容4:主服务器如何检测备用服务器的故障
流复制启动流程
开始流复制
1、主库启动walsender进程
2、备库启动startup与walreceiver进程
3、发出连接请求
4、握手成功
5、追赶没有同步的数据
6、开始正常流复制
如何开始流复制
开始流复制
walsender进程保持如下可能状态:
start-up –从启动walsender到握手结束。
catch-up – 在追赶阶段。
streaming –流媒体复制正在工作。
backup –为备份工具(如pg_basebackup utility)发送整个数据库集群的文件时。 pg_stat_replication视图显示所有正在运行的walsender的状态。示例如下:
testdb=# SELECT application_name,state FROM pg_stat_replication;
application_name | state
------------------+-----------
standby1 | streaming
standby2 | streaming
pg_basebackup | backup
预防归档日志缺失
预防归档日志缺失
如果备用服务器在长时间处于停止状态后重新启动,会发生什么情况?
在9.3或更早版本中,如果备用服务器所需的主服务器的WAL段已被回收,则备用服务器无法赶上主服务器。对于这个问题没有可靠的解决方案,只能对配置参数wal_keep_segments设置一个较大的值,以减少发生这种情况的可能性。这是权宜之计。
在9.4版或更高版本中,可以使用复制插槽来防止此问题。复制槽是一种扩展WAL数据发送灵活性的功能,主要用于逻辑复制,这也为解决这个问题提供了解决方案-包含pg_xlog(或pg_WAL,如果版本10或更高版本)下未发送数据的WAL段文件可以通过暂停回收过程而保留在复制槽中。
如何进行流式复制
如何进行流复制
流复制同步有两个方面:日志传送和数据库同步
日志传送是其中主要的同步方式,因为流复制是基于它的——主服务器在写入WAL数据时会将WAL数据发送到连接的备用服务器。
数据块传输是同步复制时需要用到的另外一种方式—主服务器与每个多个备用服务器通信以同步其数据库群集。
备库可配置只读访问/不可访问
假设备用服务器处于同步复制模式,hot standby配置为只读访问,配置如下:
synchronous_standby_names = 'standby1'
hot_standby = on
wal_level = archive
主备如何进行通讯
1、主库写WAL信息到WAL段文件。
2、主库进程将WAL数据发送给备库。
3、主库继续等待备库的ACK响应。
4、备库的将接收到的WAL数据写入备库的WAL缓冲区,并将ACK响应返回给主库。
5、备库将WAL数据写到WAL段,向主库返回另一个ACK响应。
6、备库重放已写入WAL段的WAL数据,向主库返回另一个ACK响应
7、主库在收到最后ACK响应时释放锁,然后提交完成。
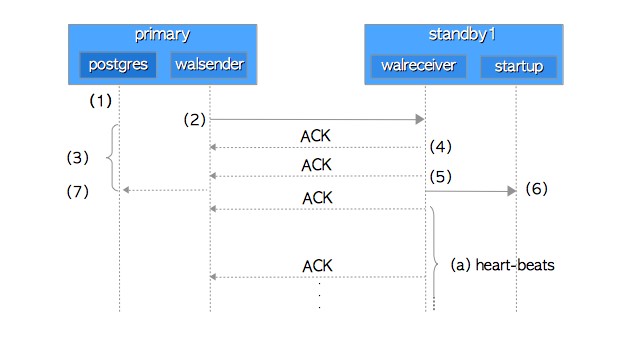
备库ACK响应
每个ACK响应通知主服务器备用服务器的内部信息。它包含以下四项:
已写入wal缓存的最新WAL数据的LSN位置。
已刷新最新WAL数据的LSN位置。
启动过程重放最新WAL数据的LSN位置。
发送此响应的时间戳。查看备库写入、刷新、应用wal日志的状态
testdb=# SELECT application_name AS host, write_lsn AS write_LSN, flush_lsn AS flush_LSN, replay_lsn AS replay_LSN FROM pg_stat_replication;??
host | write_lsn | flush_lsn | replay_lsn
----------+-----------+-----------+------------
standby1 | 0/5000280 | 0/5000280 | 0/5000280
standby2 | 0/5000280 | 0/5000280 | 0/5000280
(2 rows)
心跳的间隔设置为参数wal_receiver_status_interval,默认为10秒。
复制故障排除
如何排除故障
同步备用服务器发生故障并且不再能够返回ACK响应,主服务器仍将继续永远等待响应。因此,无法提交正在运行的事务,也无法启动后续查询处理。
流式复制不支持通过超时自动还原到异步模式(降级)的功能。
两种解决办法:
使用多个备用服务器来提高系统可用性
通过手动执行从同步模式切换到异步模式
(1) 将参数synchronous_standby_names设置为空字符串。
(2) 使用reload选项执行pg_ctl命令。
postgres> pg_ctl -D $PGDATA reload
上述过程不影响连接的客户端。主服务器继续事务处理,同时保留客户端和相应后端进程之间的所有会话。
多备库优先级状态
多备库优先级状态
通过发出以下查询,可以显示备用服务器的优先级和状态:
testdb=# SELECT application_name AS host, sync_priority, sync_state FROM pg_stat_replication;
host | sync_priority | sync_state
----------+---------------+------------
standby1 | 1 | sync
standby2 | 2 | potential
Sync是所有工作备用服务器(异步服务器除外)中优先级最高的同步备用服务器的状态。
Potential是所有工作备用服务器(异步服务器除外)中优先级第二或更低的备用同步备用服务器的状态。如果处于同步(sync状态)的备库失败,它将替换为潜在待机中优先级最高的待机。
Async是异步备用服务器的状态,此状态是固定的。主服务器以与潜在备用服务器相同的方式处理异步备用服务器,只是它们的同步状态永远不是“sync”或“potential”。
管理多备库
主库与多备库通讯方式
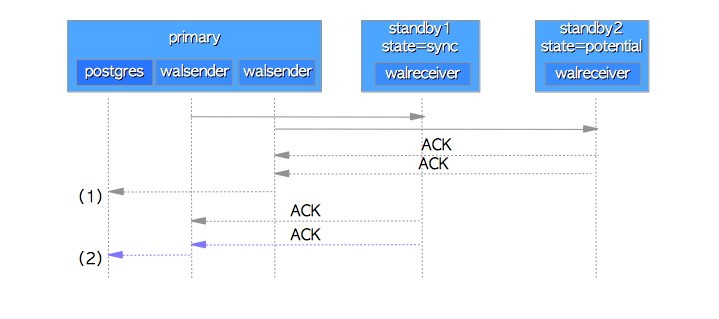
备库优先级转换
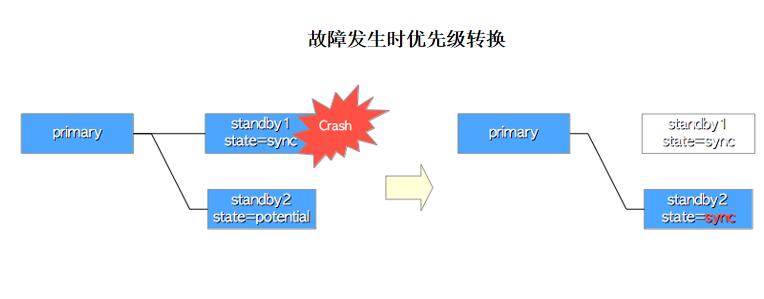
管理多备库
备库故障检测
备库进程故障检测
当检测到walsender和walreceiver之间的连接断开时,主服务器立即确定备用服务器或walreceiver进程有故障。当底层网络函数由于未能写入或读取walreceiver的socket接口而返回错误时,主函数也会立即确定其故障。
备库硬件和网络的故障检测
如果walreceiver在为参数wal_sender_timeout(默认60秒)设置的时间内未返回任何内容,则主服务器将确定备用服务器存在故障。与上述故障相反,即使备用服务器无法再通过某些故障(例如,备用服务器的硬件故障、网络故障等)发送任何响应,也需要一定时间(最长为wal_sender_timeout 秒)来确认主服务器上的备用服务器已死亡。(在确定故障之前的这段时间主服务器停止所有事务处理。)
这篇关于PostgreSQL技术大讲堂 - 第43讲:流复制原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




