本文主要是介绍分币不花,K哥带你白嫖海外代理 ip!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

前言
近来,国内的数据采集环境越来越严峻,不是“非法入侵计算机信息系统”,就是“侵犯公民个人隐私信息”,一个帽子砸下来,直接就“包吃包住”,推荐阅读一下 【K哥爬虫普法专栏】。虽然大伙常说“搏一搏单车变摩托”,但这就像高空走钢丝,谁也说不好下一步会不会掉入万丈深渊。因此何不换个赛道,把目标放到各类海外数据,比如海外电商平台、社交媒体平台等等,同样能带来巨大的价值,最重要的,大多数人的技术也不足以惊动 FBI、ICPO,整个国际红色通缉令,被跨国追捕 ≖‿≖。
不过很多海外平台都有着较严格的风控策略,既然咱无法“肉身出国”,全球各地到处跑,最好的选择自然是使用海外代理 ip,但是大多数海外代理 ip 都价格不菲,下图是一家海外代理商官网的 ISP(住宅)按流量付费产品的价格表,注意货币单位可是“美元”:
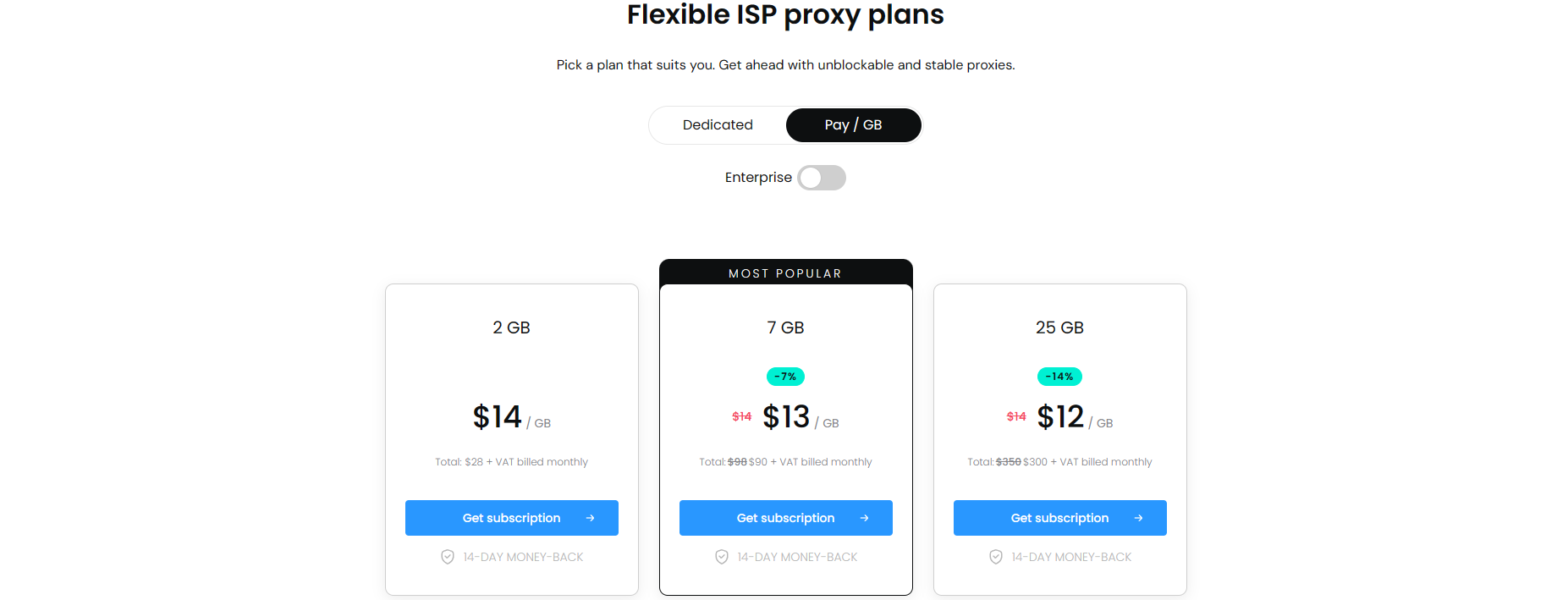
这么一来,采集海外数据的成本就太高了,那有什么好的解决办法呢?自然是有的,K哥深知大伙都坚决贯彻着“能白嫖绝不付费”的思想,有免费的用绝不花钱买 ( ´◔ ‸◔`),但是用过国内那些网站的免费代理的都知道,免费的真没啥好东西,质量堪忧。那么问题就来了,海外代理 ip 还更值钱一些,哪里能找到能用且好用的免费海外代理 ip 呢?K哥还真找到一个,本文将手把手教你如何采集该网站的免费海外代理 ip,并给出源代码,一起来给这年轻的网站“上上课”。
采集目标
- 网站:https://www.iphaiwai.com/free
采集过程
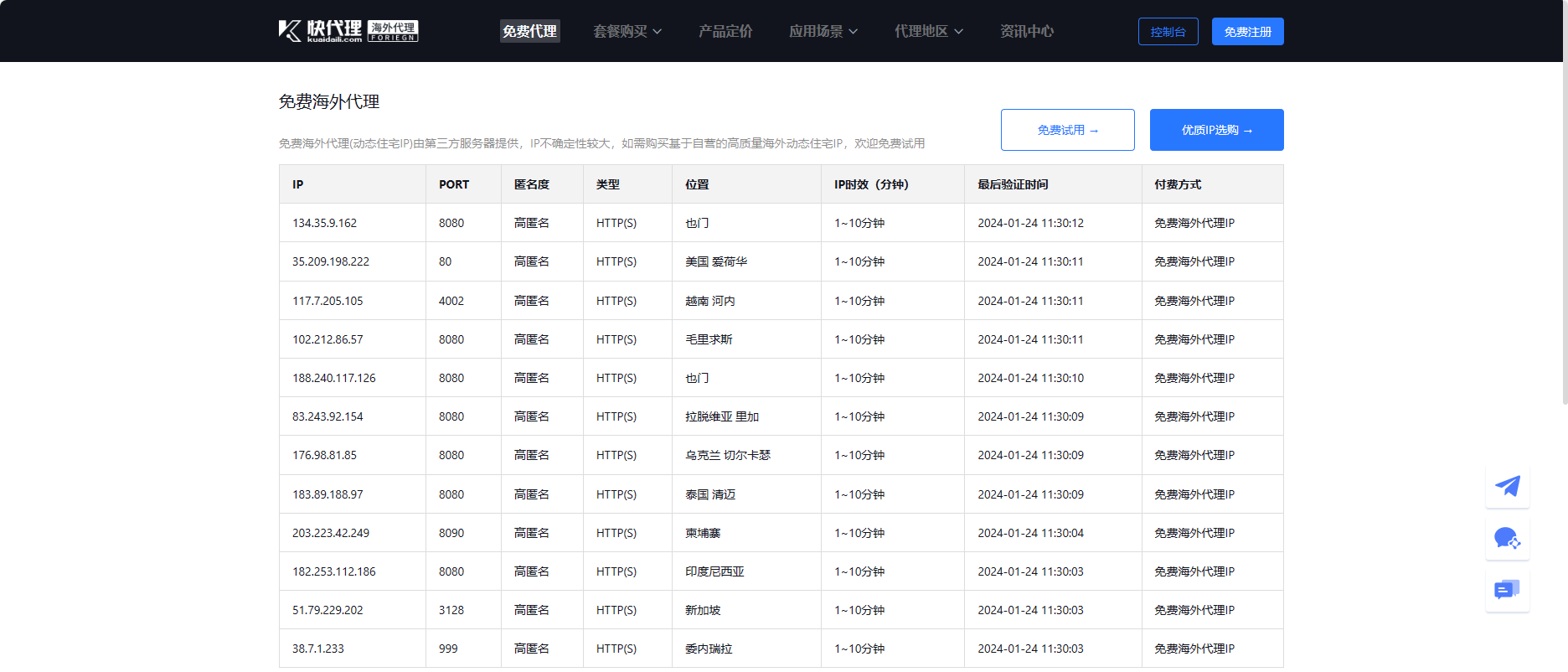
该网站为快代理的海外独立站,首先进入到网页,可以看到有很多地区的海外代理 ip,美国、新加坡、泰国等等,全球各地的都有,而且都是高匿名的。这些 ip 时效都显示的 1-10 分钟,但是根据实际测试,部分 ip 半小时之后仍然可用。并且半小时刷新一次,也就是每隔半小时能获取到 12 个新的可用 ip,结合一些合理的调度策略,每天都能够不间断地“白嫖”~
当然,没必要整啥并发之类的,每半小时获取一次就可以了,不间断请求也不会给你一批新货,还会被封哦:
现在,咱们分析下如何采集这些海外代理 ip。
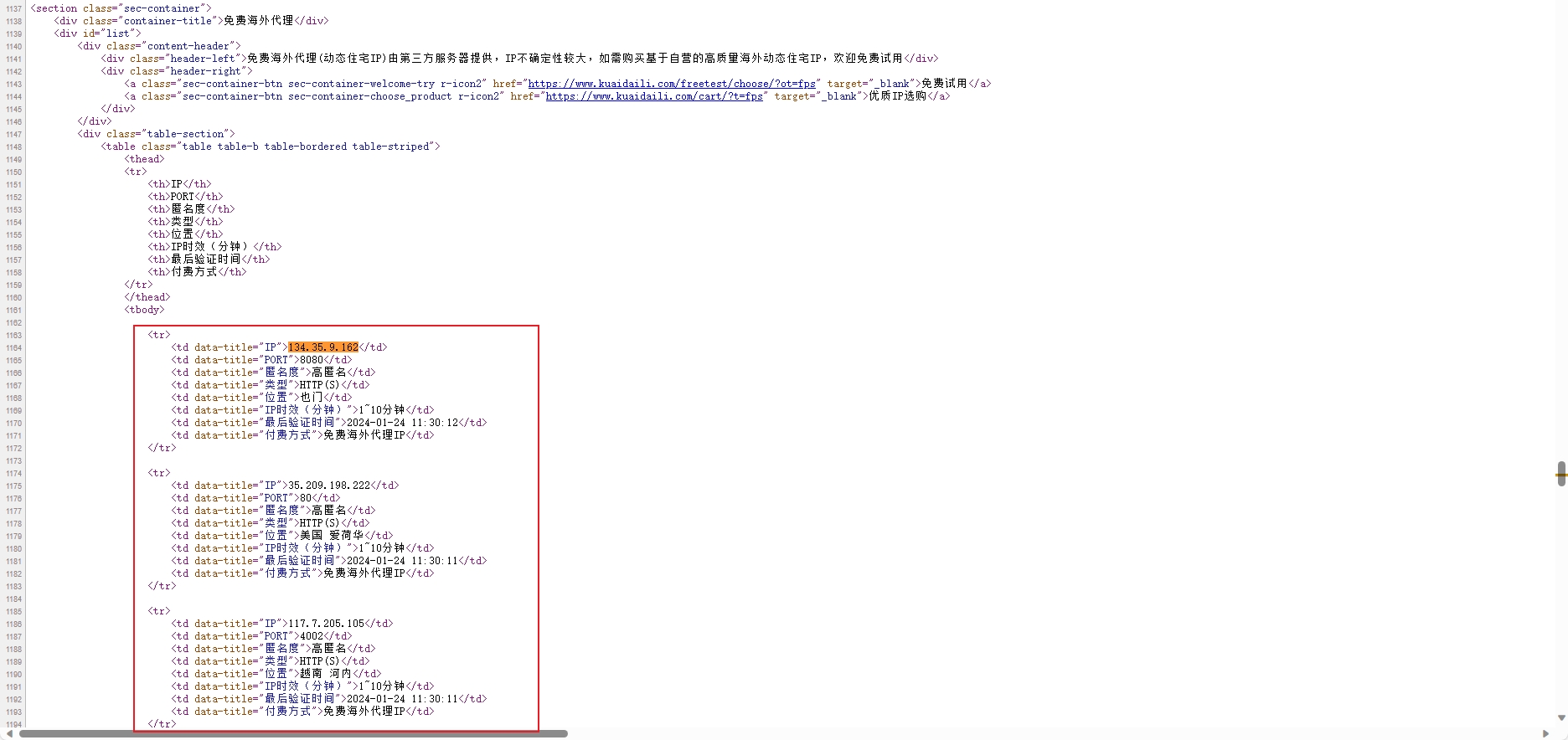
鼠标移动到网页上,右键查看页面源代码(ctrl+u),搜索一下目标 ip,会发现能直接搜索到,且其他 ip 相关数据也都在其中。证明这些数据不是通过接口传输的,可以直接使用一些常用的 Python 解析库,例如 XPath、pyquery 或者正则表达式等方法匹配到想要的数据,而且该页面大概率也是没啥反爬的:
那么,还是老样子,F12,先打开开发者人员工具进行抓包,刷新网页,可以看到,https://www.iphaiwai.com/free/ 请求的响应内容包含我们所需要的 html 源代码:
先点击开发者人员工具左上角的按钮,检查网页元素,再随便点击一个 ip,即可跳转到其在 html 代码中的位置,页面是个表格样式,这里自然就是一些 tr、td 标签,tr 包裹了每行的内容,td 则对应该行中每个单元格的值,如下图所示:
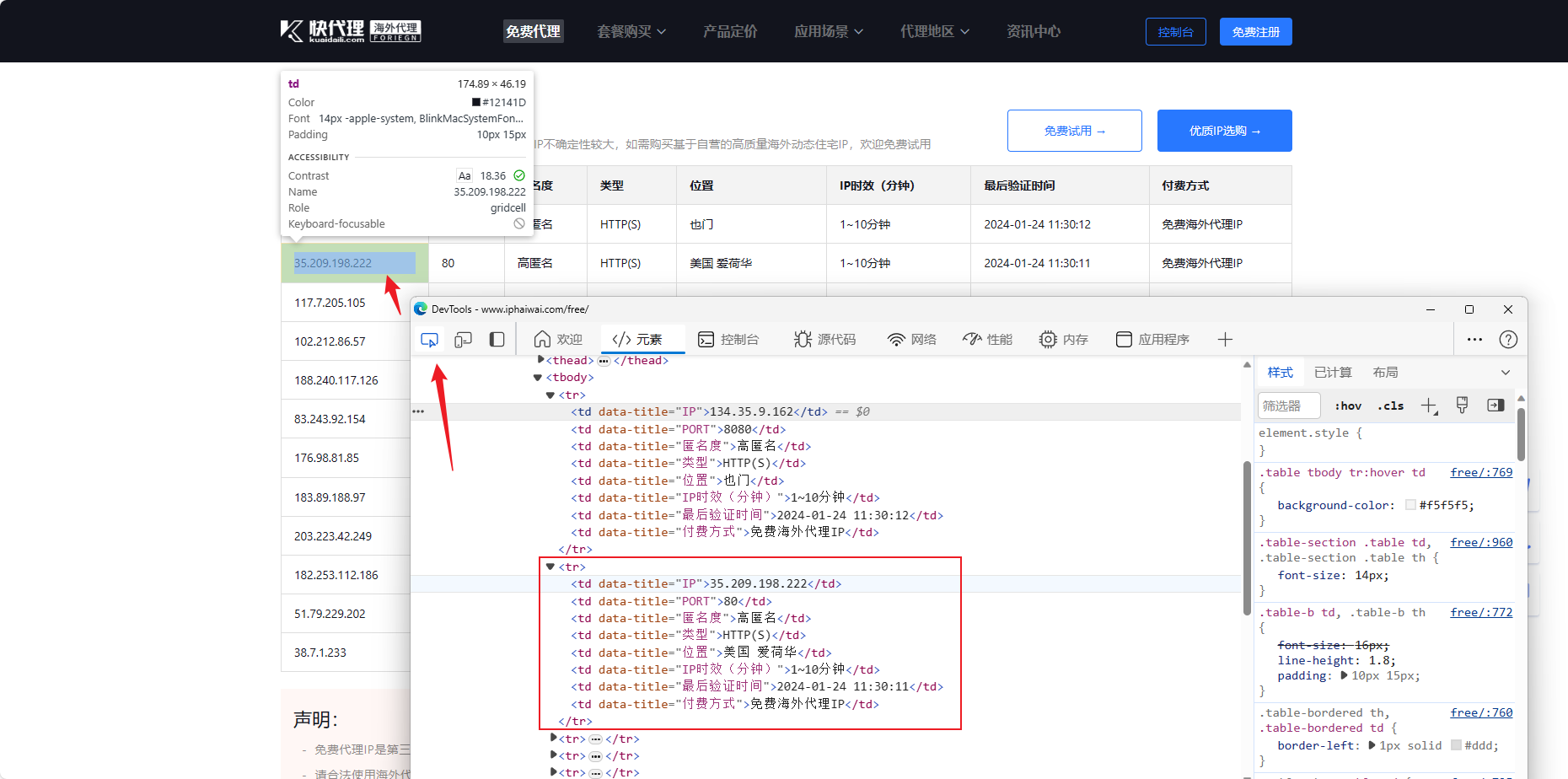
这里我们使用 lxml 解析库中的 Xpath 方法来匹配这部分内容,先简单介绍一下,XPath(XML Path Language)是一种用于在 XML 文档中查找信息的语言,通过特定的路径表达式来匹配在 XML 文档结构中的位置。使用前,需要先安装一下 lxml 解析库:
# 直接安装
pip install lxml
# 镜像安装
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
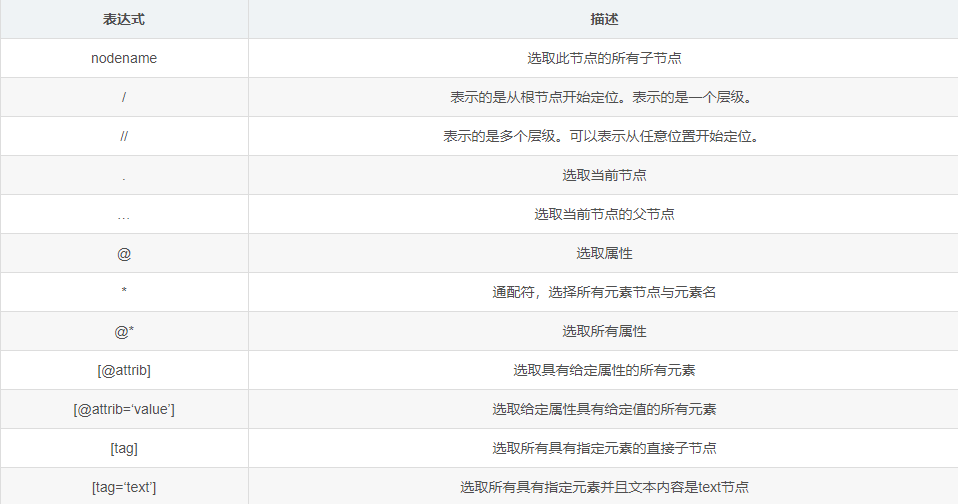
下面是 Xpath 的一些基本表达式,更详细的可以阅读 K 哥往期文章 【0基础学爬虫】爬虫基础之网页解析库的使用:
我们需要获取 <td data-title="IP">134.35.9.162</td> 中的 ip 值,只用匹配 td 标签的属性 data-title 值为 IP 的即可,基本写法如下:
import requests
from lxml import etree
from loguru import loggerheaders = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"
}
url = "https://www.iphaiwai.com/free/"
response = requests.get(url, headers=headers, timeout=5)# 获取 ip
# xpath 匹配 ip 值
html = etree.HTML(response.text)
ip_list = html.xpath("//td[@data-title='IP']/text()")
logger.info(ip_list)
如果还想要别的数据,例如时效、位置等等,方法也都一样,依此类推。这里的样式较为简单,比较容易就能够匹配到值,一般复杂些的,我们可以用些工具先校验一下 xpath 表达式是否正确,比如浏览器插件 XPath Helper,能够显示出输入的 xpath 表达式匹配出来的结果。该插件可以去K哥公众号回复关键字 XPath Helper 获取。
插件安装后,按快捷键 ctrl + shift + x 即可启动。以下为结果验证,可以看到,该表达式正确匹配到了 12 个 ip 值:

完整代码
以下代码只是简单实现了一些基本的功能,可以根据自己的需求进行相应的调整,经过K哥测试,这些 ip 好像不区分使用环境,大家可以自行测试一下:
# ======================
# -*-coding: Utf-8 -*-
# author: K哥爬虫
# ======================
import requests
from lxml import etree
from loguru import logger
from concurrent.futures import ThreadPoolExecutor, as_completed# 免费海外代理 ip 页
FREE_IP_URL = 'https://www.iphaiwai.com/free'
# 验证网站
VERIFY_URL = 'https://web.whatsapp.com'class OverseasFree:def __init__(self):self.headers = {"Accept-Encoding": "gzip","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0"}self.effective_ip_list = []@staticmethoddef get_proxies(proxy: str) -> dict:proxies = {"http": "http://%(proxy)s/" % {"proxy": proxy},"https": "http://%(proxy)s/" % {"proxy": proxy}}return proxiesdef verify_ip(self, proxy_ip_data: str):"""验证 ip 可用性:param proxy_ip_data: 获取到的免费海外代理 ip"""# 获取代理 ipproxy = proxy_ip_data.split(',')[0]proxies = self.get_proxies(proxy)try:# 验证可用性, 国内环境无法访问该网站response = requests.get(url=VERIFY_URL, proxies=proxies, timeout=20)response.encoding = 'utf-8'# <title>WhatsApp Web</title>if response.status_code == 200:logger.success('ip <%s> verify success' % proxy)self.effective_ip_list.append(proxy_ip_data)else:logger.error('ip <%s> verify error, status code: %s' % (proxy, response.status_code))except Exception as e:logger.error('ip <%s> verify error: %s' % (proxy, e))def get_data(self) -> list:"""获取 ip 相关信息"""try:response = requests.get(url=FREE_IP_URL, headers=self.headers, timeout=5)html = etree.HTML(response.text)# 获取 ipip_list = html.xpath("//td[@data-title='IP']/text()")port_list = html.xpath("//td[@data-title='PORT']/text()")# 获取 ip 位置area_list = html.xpath("//td[@data-title='位置']/text()")# 获取 ip 有效期period_of_validity_list = html.xpath("//td[@data-title='IP时效(分钟)']/text()")# 获取到的所有 ip 的相关数据proxy_list = [f"{ip}:{port}, {area}, {period}" for ip, port, area, period in zip(ip_list, port_list, area_list, period_of_validity_list)]return proxy_listexcept Exception as e:logger.error('get ip error: %s' % e)def main(self):# 获取所有的免费代理 ipproxy_data_list = self.get_data()# 验证 ip 可用性with ThreadPoolExecutor(max_workers=12) as executor:futures = [executor.submit(self.verify_ip, proxy) for proxy in proxy_data_list]verify_result = [future.result() for future in as_completed(futures)]if verify_result:# 处理返回的数据pass# 打印所有的有效 iplogger.info(self.effective_ip_list)logger.info('Get IP Number: %d' % len(self.effective_ip_list))if __name__ == '__main__':OverseasFree().main()
结果验证
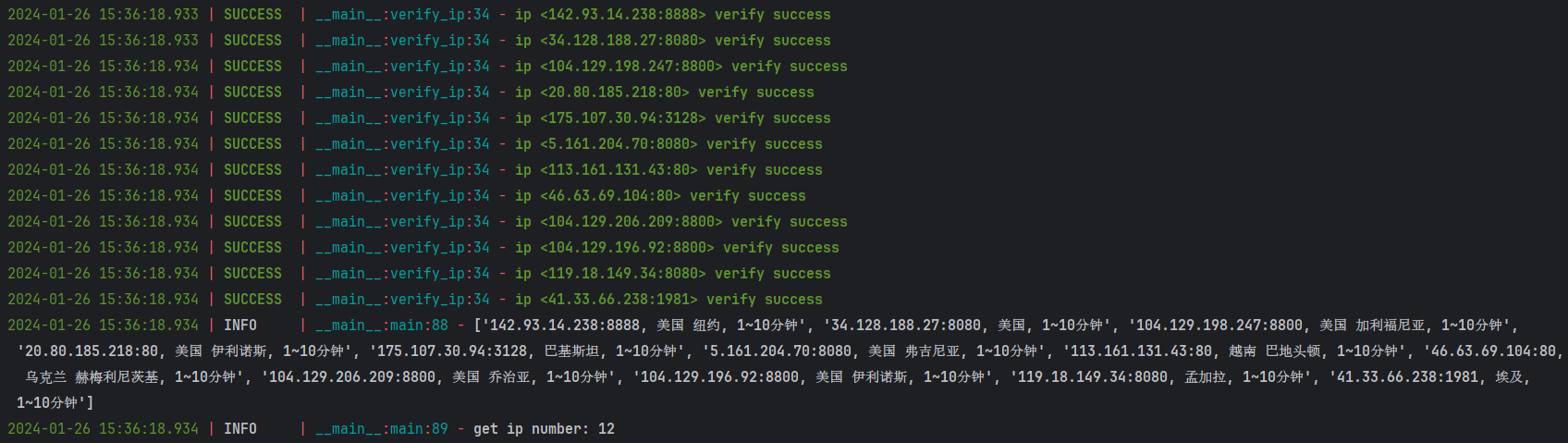
这篇关于分币不花,K哥带你白嫖海外代理 ip!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







