本文主要是介绍Flink 双流Join,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
支持的join类型
Apache Flink目前支持INNER JOIN和LEFT OUTER JOIN(SELF 可以转换为普通的INNER和OUTER)。在语义上面Apache Flink严格遵守标准SQL的语义
| CROSS | INNER | OUTER | SELF | ON | WHERE | |
|---|---|---|---|---|---|---|
| Apache Flink | N | Y | Y | Y | 必选 | 可选 |
双流Join的分类:
- Join大体分类只有两种:Window Join和Interval Join。Window Join又可以根据Window的类型细分出3种:
- Tumbling Window Join、Sliding Window Join、Session Widnow Join。
- Windows类型的join都是利用window的机制,先将数据缓存在Window State中,当窗口触发计算时,执行join操作;
- interval join也是利用state存储数据再处理,区别在于state中的数据有失效机制,依靠数据触发数据清理;
双流JOIN操作注意事项
想要实现流的join我们要考虑数据的延迟,也就是不同流数据到达算子时间不一致的问题。这时候需要用到flink的水印,窗口,EventTime等概念,同时 flink提供了两种流join的算子,Join和coGroup。具体区别参考上篇博客:https://blog.csdn.net/aA518189/article/details/84032660,这篇博客中详细介绍了Join和coGroup的区别,以实现双流Join的案例。
双流JOIN与传统数据库表JOIN的区别
传统数据库表的JOIN是两张静态表的数据联接,在流上面是动态表,双流JOIN的数据不断流入与传统数据库表的JOIN有如下3个核心区别:
- 左右两边的数据集合无穷 - 传统数据库左右两个表的数据集合是有限的,双流JOIN的数据会源源不断的流入。
- JOIN的结果不断产生/更新 - 传统数据库表JOIN是一次执行产生最终结果后退出,双流JOIN会持续不断的产生新的结果。
- 查询计算的双边驱动 - 双流JOIN由于左右两边的流的速度不一样,会导致左边数据到来的时候右边数据还没有到来,或者右边数据到来的时候左边数据没有到来,所以在实现中要将左右两边的流数据进行保存,以保证JOIN的语义。
数据Shuffle
分布式流计算所有数据会进行Shuffle,怎么才能保障左右两边流的要JOIN的数据会在相同的节点进行处理呢?在双流JOIN的场景,我们会利用JOIN中ON的联接key进行partition,确保两个流相同的联接key会在同一个节点处理,这个在flink的源码中有说明。

数据的保存
不论是INNER JOIN还是OUTER JOIN 都需要对左右两边的流的数据进行保存,JOIN算子会开辟左右两个State进行数据存储,左右两边的数据到来时候,进行如下操作:
- LeftEvent到来存储到LState,RightEvent到来的时候存储到RState;
- LeftEvent会去RightState进行JOIN,并发出所有JOIN之后的Event到下游;
- RightEvent会去LeftState进行JOIN,并发出所有JOIN之后的Event到下游。

简单场景介绍实现原理
INNER JOIN 实现
JOIN有很多复杂的场景,我们先以最简单的场景进行实现原理的介绍,比如:最直接的两个进行INNER JOIN,比如查询产品库存和订单数量,库存变化事件流和订单事件流进行INNER JOIN,JION条件是产品ID,具体如下: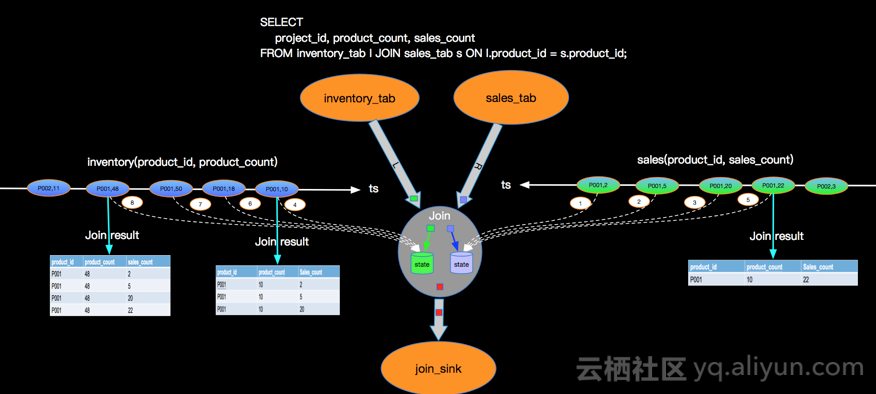
双流JOIN两边事件都会存储到State里面,如上,事件流按照标号先后流入到join节点,我们假设右边流比较快,先流入了3个事件,3个事件会存储到state中,但因为左边还没有数据,所有右边前3个事件流入时候,没有join结果流出,当左边第一个事件序号为4的流入时候,先存储左边state,再与右边已经流入的3个事件进行join,join的结果如图 三行结果会流入到下游节点sink。当第5号事件流入时候,也会和左边第4号事件进行join,流出一条jion结果到下游节点。这里关于INNER JOIN的语义和大家强调两点:
- INNER JOIN只有符合JOIN条件时候才会有JOIN结果流出到下游,比如右边最先来的1,2,3个事件,流入时候没有任何输出,因为左边还没有可以JOIN的事件;
- INNER JOIN两边的数据不论如何乱序,都能够保证和传统数据库语义一致,因为我们保存了左右两个流的所有事件到state中。
LEFT OUTER JOIN 实现
LEFT OUTER JOIN 可以简写 LEFT JOIN,语义上和INNER JOIN的区别是不论右流是否有JOIN的事件,左流的事件都需要流入下游节点,但右流没有可以JION的事件时候,右边的事件补NULL。同样我们以最简单的场景说明LEFT JOIN的实现,比如查询产品库存和订单数量,库存变化事件流和订单事件流进行LEFT JOIN,JION条件是产品ID,具体如下:
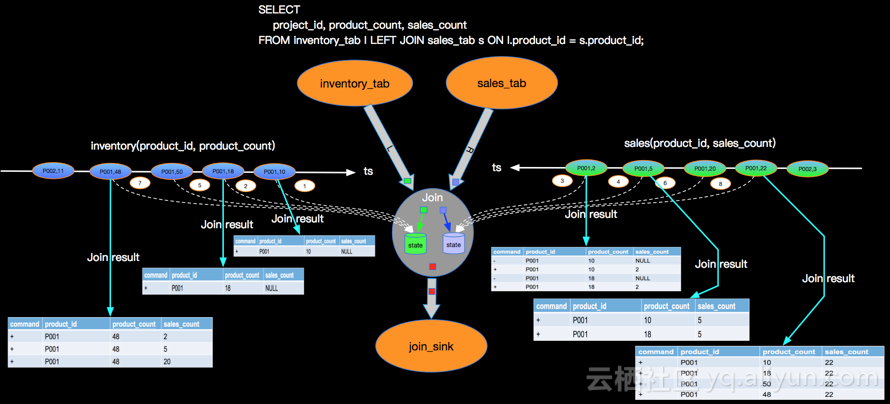
下图也是表达LEFT JOIN的语义,只是展现方式不同:

上图主要关注点是当左边先流入1,2事件时候,右边没有可以join的事件时候会向下游发送左边事件并补NULL向下游发出,当右边第一个相同的Join key到来的时候会将左边先来的事件发出的带有NULL的事件撤回(对应上面command的-记录,+代表正向记录,-代表撤回记录)。这里强调三点:
- 左流的事件当右边没有JOIN的事件时候,将右边事件列补NULL后流向下游;* 当右边事件流入发现左边已经有可以JOIN的key的时候,并且是第一个可以JOIN上的右边事件(比如上面的3事件是第一个可以和左边JOIN key P001进行JOIN的事件)需要撤回左边下发的NULL记录,并下发JOIN完整(带有右边事件列)的事件到下游。后续来的4,5,6,8等待后续P001的事件是不会产生撤回记录的。
- 在Apache Flink系统内部事件类型分为正向事件标记为“+”和撤回事件标记为“-”。
RIGHT OUTER JOIN 和 FULL OUTER JOIN
RIGHT JOIN内部实现与LEFT JOIN类似, FULL JOIN和LEFT JOIN的区别是左右两边都会产生补NULL和撤回的操作。对于State的使用都是相似的,这里不再重复说明了。
这篇关于Flink 双流Join的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


