本文主要是介绍MySQL连表操作之一对多,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MySQL连表操作之一对多
目录
- 引入
- 外键
- Navicat创建外键
- 使用外键
- SQL命令创建外键
- 代码删除外键
- 代码增加外键
- 通过外键进行数据操作
正文
引入
当我们在数据库中创建表的时候,有可能某些列中值内容量很大,而且重复。
例子:创建一个学生表,按学校年纪班级分,表的内容大致如下:
| id | name | partment |
| 1 | xxx | x学校x年级x班级 |
| 2 | ooo | x学校x年级x班级 |
| 3 | zzz | z学校x年级x班级 |
| 4 | ddd | y学校x年级x班级 |
我们看出来对应的partment对应的值很长,而且重复量很大,这样就很不合适。
因此我们考虑将复杂重复的部分单独拿出来分成2个表:
第一张表:
| id | caption |
| 1 | x学校x年级x班级 |
| 2 | y学校x年级x班级 |
| 3 | z学校x年级x班级 |
第二张表在之前的基础上修改的:
| id | name | partment |
| 1 | xxx | 1 |
| 2 | ooo | 2 |
| 3 | zzz | 3 |
| 4 | ddd | 1 |
这样看起来就很简洁了,我们将很长的且重复的部分拿出来,然后规定编号,创建学生表的时候,学生对应的partment只需要取学校对应的id便可,这样同时这2张表也就会关联起来。
说明:
1、他们的关联关系;表2中的partment和表1的id联系再一起。
2、表一的数据会对应表2中的多条数据,这就叫一对多。
问题:此时,两张表是相对独立的,都可以各自插入自己的数据,这样做很合适的,并没实质行的关联?
因此,必须要将其限制。表二的partment数据必须是表一中有的,不然,就不让其增加。
这里(partment)就引入了一个名词 —- 外键
外键
说明:
1、外键:一个表接收另一个表的主键。
2、partment外键的是表一中的nid。
3、当我们创建了外键,则系统变默认会为我们添加,相应的约束,如:表二中的partment数据必须是表一中nid有的;表二和表一就关联起来了。
Navicat创建外键
创建part表:
创建person表:

外键的创建注意点:
创建外键时,互相对应的表中的数据类型必须一样。
创建外键
1、首先在要创建外键的表上右键,选设计表。
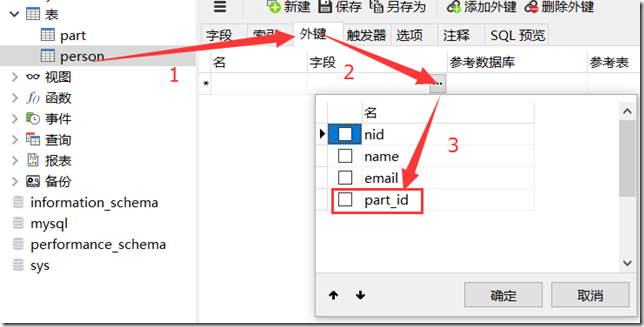
2、进入设计表,在右边显示表行信息,然后点击外键:

3、选择字段,会出现一个选择框,选择你要设置外键的列;
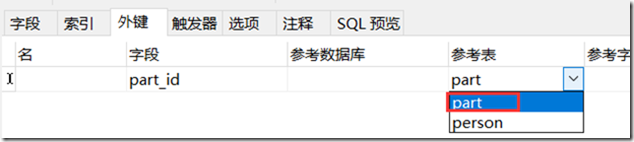
4、选择参考表,选择要外键要关联的表,
说明:
参数数据库:因为两个数据库在同意目录下,所以这里可以不用选择;默认是同目录下的。
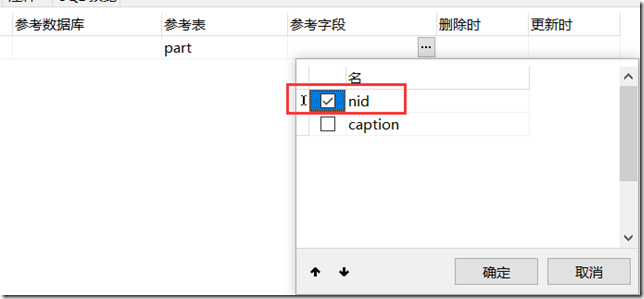
5、选择参考字段;选择参考表中要设为外键的列;
注意:
外键的创建,连个表中关联的列的数据类型必须一样,不然不能成功。
6、保存CTRL + S
使用外键
此时part中没有数据,如果此时你在person中添加数据,结果:
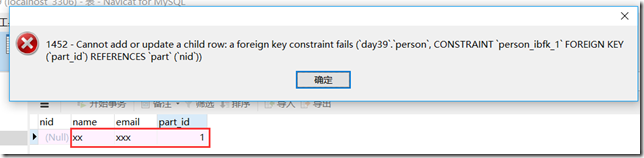
在part中添加数据,结果:
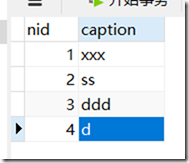
此时再在,person中添加数据:
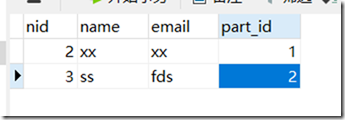
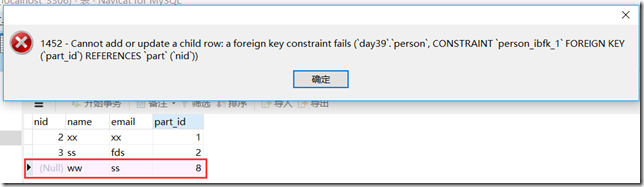
注意:
这里不能输入part中nid没有的值,不然也会报错。
SQL命令创建外键
创建part:
create table part(nid int not null auto_increment primary key,caption varchar(32) not null
)part
创建person:
create table person(nid int not null auto_increment,name varchar(32) default null,email varchar(32) default null,part_nid int,primary key(nid),constraint fk_person_part foreign key (part_nid) references part(nid)
)person
创建完之后外键对应代码的关系:

分析:
1、从名字可以看出代码对应的是什么位置的。
2、图中名(C对应代码中的CONSTRAINT)这行可以不用设,系统会默认帮我设置,但是最好设置,如果要删除外键的时候,就可以通过这个名字进行相应的操作。
代码删除外键
| 01 |
|
代码增加外键
| 01 |
|
通过外键进行数据操作
part表:
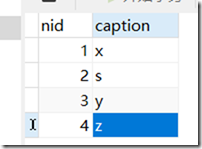
person表:
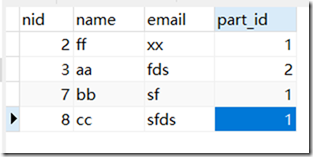
需求:要找出person表中属于x学校的人?
1、之前学的办法:
- 1、先去part中获取x对应的nid
- 2、然后再通过这个nid与parson中part_id对用的关系,查找出对应的name
| 01 |
|
2、链表方法 left join
left join
使用连表提供的方法,left join操作代码:
| 01 |
|
结果显示:
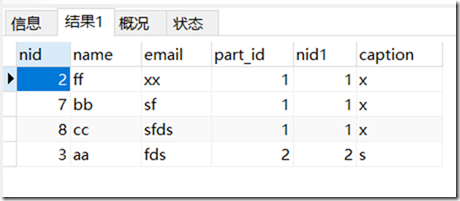
分析:
left join:相当于将part表匹配的部分直接移动到person的列后面,组合起来显示。
 既然内容都合并了,那么此时我们再加上判断,就可以将要的数据获取了。
既然内容都合并了,那么此时我们再加上判断,就可以将要的数据获取了。
代码1:
| 01 |
|
结果:
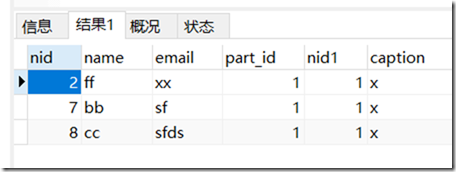
说明:
之前我们用的
*获取的是全部的信息,如果我们获取指定的信息,可以将其修改。如:只获取person的name代码:
01
selectperson.namefrompersonleftjoinpartonperson.part_id = part.nidwherepart.caption ="x"
结果:
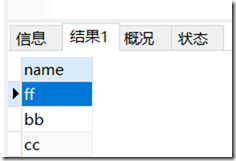
注意:
join连接的条件,使用 on 进行对接的,条件写在on后面。
| 01 |
|
left join的特点:
1、以A为主
2、将A中的所有数据罗列
3、B则只显示与A相对应的数据
问题:验证我们说的谁在前就谁为主,谁的数据就全部显示,我们将person和part换个位置?
| 01 |
|
结果:
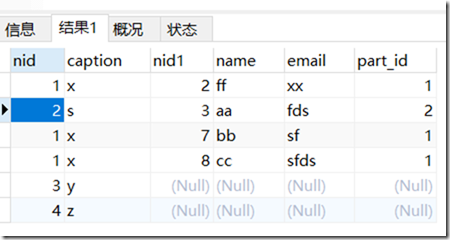
right join
在谁显示所有数据的上来看,他和left join刚好相反,以后面的表为主,显示其所有的数据。
inner join
会将没有建立关系的数据忽略掉。不管谁在前,结果都是一样。
| 01 |
|
结果:
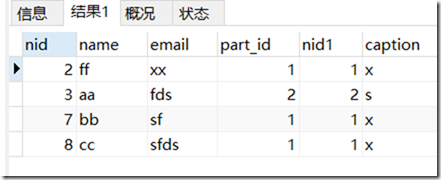
总结:
1、这几个join可以写多个的,意思就是一个表可以同时有多个外键。2、当选择的列名,是所有表中唯一的话,可以不用写前缀的表名。如:person.part_id就可以直接写成part_id.
3、上面的part表,有个别名叫,字典表
这篇关于MySQL连表操作之一对多的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






