本文主要是介绍redis主从复制薪火相传,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.主从复制
1、是什么
主机数据更新后根据配置和策略, 自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
2、能干嘛
读写分离,性能扩展(主 写 从 读)
容灾快速恢复
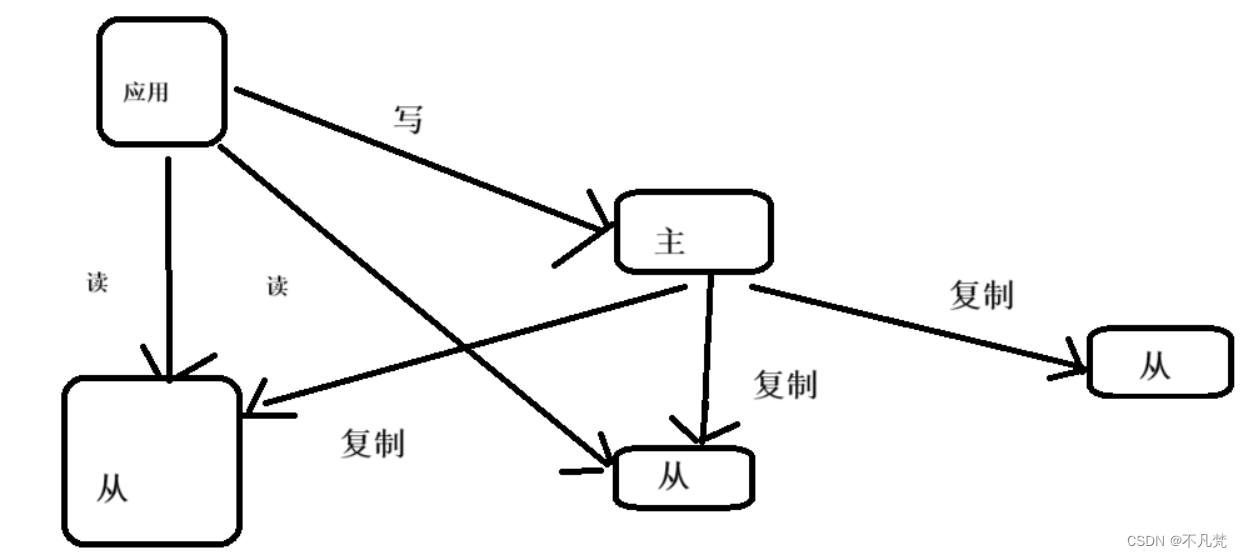
3、 主从复制
一主二仆
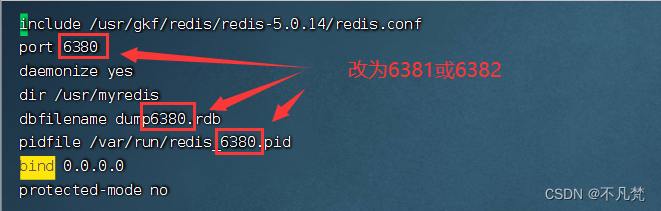
更改端口号
6379
6380 zh 6381 6382
拷贝多个redis.conf文件include(写绝对路径)
开启daemonize yes
Pid文件名字pidfile
指定端口port
Log文件名字
dump.rdb名字dbfilename
Appendonly 改为no
注意:不能设置密码
创建文件

移动到这个目录下

修改这个文件

redis6380.conf需要配置的东西
include /usr/gkf/redis-5.0.14/redis.conf
port 6380
daemonize yes
dir /usr/myredis
dbfilename dump6380.rdb
pidfile /var/run/redis_6380.pid
bind 0.0.0.0
protected-mode no 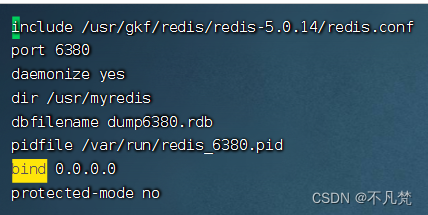
启动命令 /usr/redis/bin/redis-server /usr/myredis/redis6380.conf

链接成功 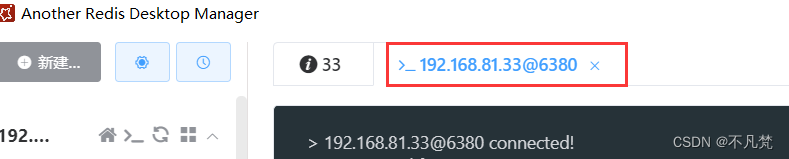
因为没有设置密码,可以直接链接

其余里面的内容的信息是一样的,不过把6380替代对应的

启动三台redis服器
/usr/java/redis/bin/redis-server /usr/java/myredis/redis6379.conf
/usr/java/redis/bin/redis-server /usr/java/myredis/redis6380.conf
/usr/java/redis/bin/redis-server /usr/java/myredis/redis6381.conf

新开一个虚拟机连接6381和6382


redis_6381.conf
include /usr/java/myredis/redis.conf
pidfile /var/run/redis_6381.pid
port 6381
dbfilename dump6381.rdb
查看三台服务器的运行情况
连接客户端 :./redis-cli -p 6379
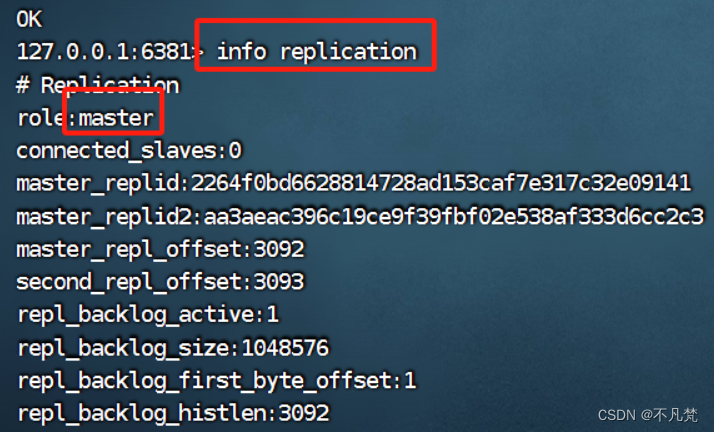
查看运行 状态:info replication
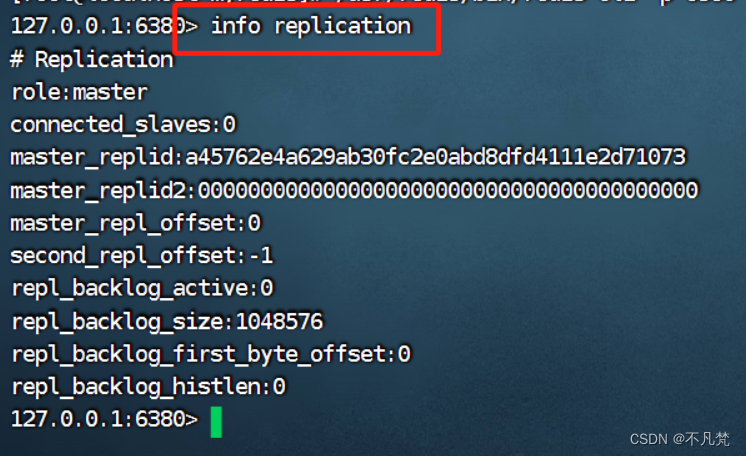
三台都是主机
配置从机
6379 主 80 81从
slaveof
成为某个实例的从服务器
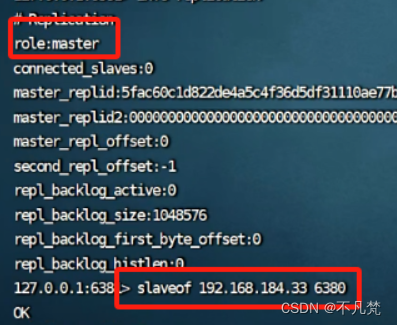
1.在6380和6381上执行: slaveof 127.0.0.1 6379

在80里面查看
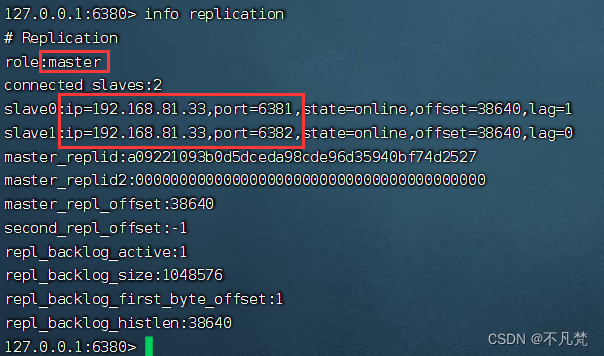
2.在主机上写,在从机上可以读取数据
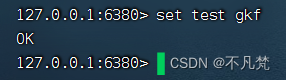
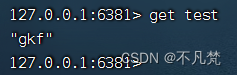
3.主机挂掉,重启就行,一切如初
从机宕机需要重新启动
4.从机重启需重设:slaveof 127.0.0.1 6380
4、复制原理
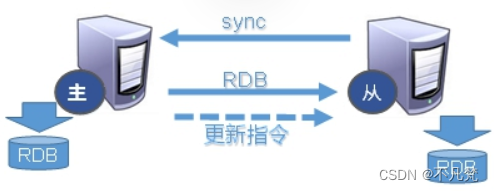
Slave启动成功连接到master后会发送一个sync命令
Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令, 在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
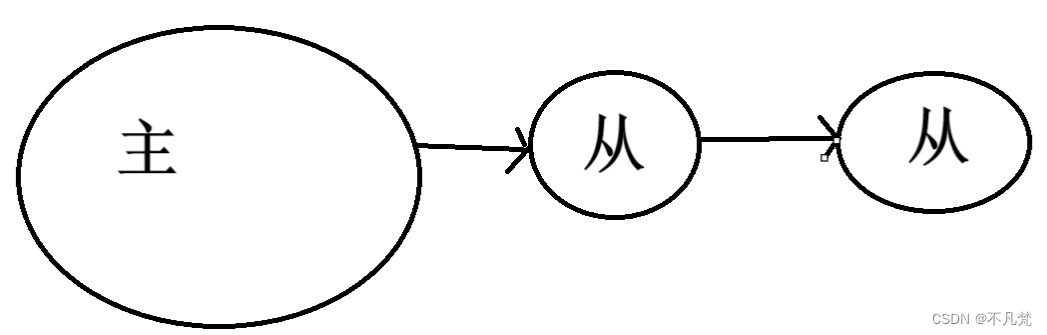
5、 薪火相传
上一个Slave可以是下一个slave的Master,Slave同样可以接收其他 slaves的连接和同步请求,那么该slave作为了链条中下一个的master, 可以有效减轻master的写压力,去中心化降低风险。
用 slaveof
中途变更转向:会清除之前的数据,重新建立拷贝最新的
风险是一旦某个slave宕机,后面的slave都没法备份
主机挂了,从机还是从机,无法写数据了
80 1
81 2
82 3
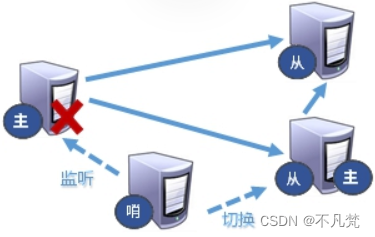
反客为主
当一个master宕机后,后面的slave可以立刻升为master,其后面的slave不用做任何修改。
用 slaveof no one 将从机变为主机。
6、 哨兵模式(sentinel)
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
调整为一主二仆模式,6380带着6381、6382
自定义的/myredis目录下新建sentinel.conf文件,名字绝不能错
80
配置哨兵,填写内容
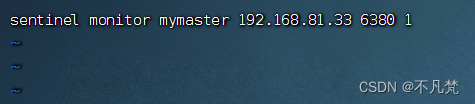
sentinel monitor mymaster 192.168.81.33 6380 1
其中mymaster为监控对象起的服务器名称, 1 为至少有多少个哨兵同意迁移的数量。

启动哨兵
/usr/local/bin/redis-sentinel /usr/myredis/sentinel.conf

宕机6380

当主机挂掉,从机选举中产生新的主机
(大概10秒左右可以看到哨兵窗口日志,切换了新的主机)
哪个从机会被选举为主机呢?根据优先级别:replica-priority
原主机重启后会变为从机。
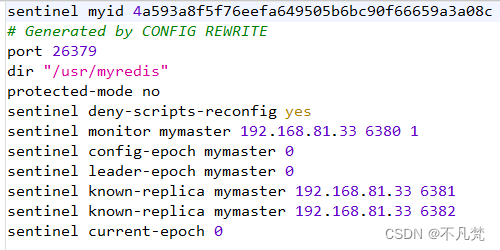
宕机之后刚才写的sentinel.conf会自动生成一些东西
这篇关于redis主从复制薪火相传的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






