本文主要是介绍传统词嵌入方法的千层套路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
诸神缄默不语-个人CSDN博文目录
在自然语言处理(NLP)领域,词嵌入是一种将词语转换为数值形式的方法,使计算机能够理解和处理语言数据。
词嵌入word embedding也叫文本向量化/文本表征。
本文将介绍几种流行的传统词嵌入方法。
文章目录
- 0. 独热编码
- 1. 词袋模型
- 2. TF-IDF
- 3. word2vec
- 1. skip-gram
- 2. CBOW
- 4. LSA
- 5. GloVe
- 6. CoVe
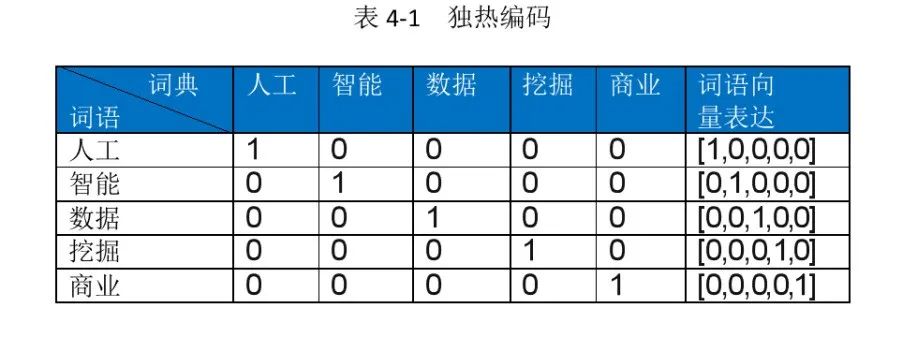
0. 独热编码
one-hot encoding
将每个词表示为一维向量
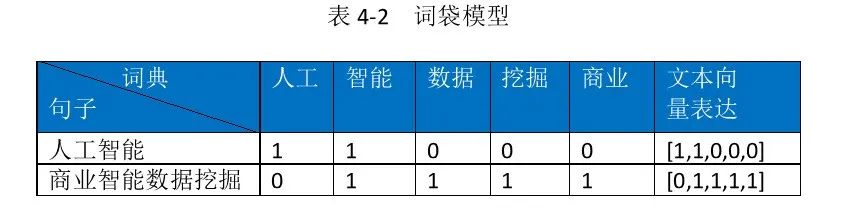
1. 词袋模型
bag of word (BoW)
词袋模型是最简单的文本表示法之一。它将文本转换为一个长向量,这个向量的每一个元素代表词汇表中的一个词,并记录该词在文本中出现的次数。
- 优点:简单易懂,易于实现。
- 缺点:忽略了词语的顺序和上下文信息,无法捕捉词与词之间的关系。
sklearn的实现:
from sklearn.feature_extraction.text import CountVectorizercorpus #由字符串组成的列表
vector = CountVectorizer().fit(corpus)
train_vector = vector.transform(corpus)
2. TF-IDF
term frequency-inverse document frequency
TF-IDF是一种用于信息检索和文本挖掘的常用加权技术。它评估一个词对于一个文档集或一个语料库中的其中一份文档的重要程度。
TF (Term Frequency)中文含义是词频,IDF (Inverse Document Frequency)中文含义是逆文本频率指数。
TF统计的是词语在特定文档中出现的频率,而IDF统计的是词语在其他文章中出现的频率,其处理基本逻辑是词语的重要性随着其在特定文档中出现的次数呈现递增趋势,但同时会随着其在语料库中其他文档中出现的频率递减下降(考虑到有些常用词在所有文档里面都很常见)。
数学表达式如下:
TF-IDF ( w , d ) = TF ( w , d ) × IDF ( w ) \text{TF-IDF}(w,d)=\text{TF}(w,d)\times \text{IDF}(w) TF-IDF(w,d)=TF(w,d)×IDF(w)
- 优点:能够减少常见词的影响,突出重要词汇。
- 缺点:与BoW一样,忽略了词序和上下文信息。
sklearn的实现:
from sklearn.feature_extraction.text import TfidfVectorizertfidf=TfidfVectorizer(max_features=500)
corpus #由字符串组成的列表
sp_tfidf=tfidf.fit_transform(corpus) #返回稀疏矩阵,每一行是语料中对应文档的表示向量
3. word2vec
Word2Vec是一种预测模型,用于产生词嵌入。它有两种结构:连续词袋(CBOW)和跳字模型(Skip-Gram)。
- 优点:能够捕捉一定程度的词序和上下文信息。
- 缺点:对于每个词仅有一个嵌入表示,忽略了多义性。
原始论文:
Distributed Representations of Sentences and Documents:提出word2vec框架
Efficient Estimation of Word Representations in Vector Space:介绍训练trick:hierarchical softmax 和 negative sampling
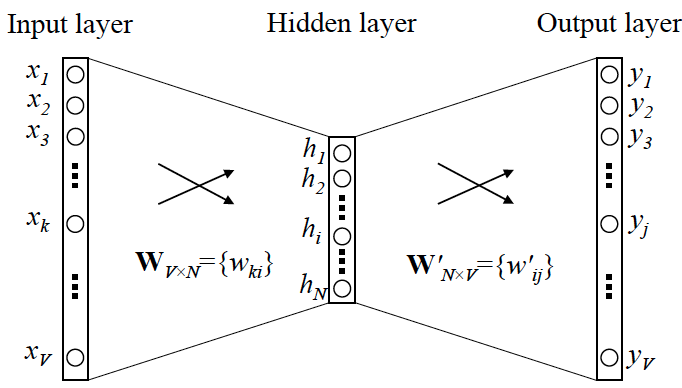
1. skip-gram
用一个词语作为输入,来预测它周围的上下文
训练思路:用独热编码表示词语。输入这个词语的独热编码,转换为隐藏层编码,输出上下文的独热编码
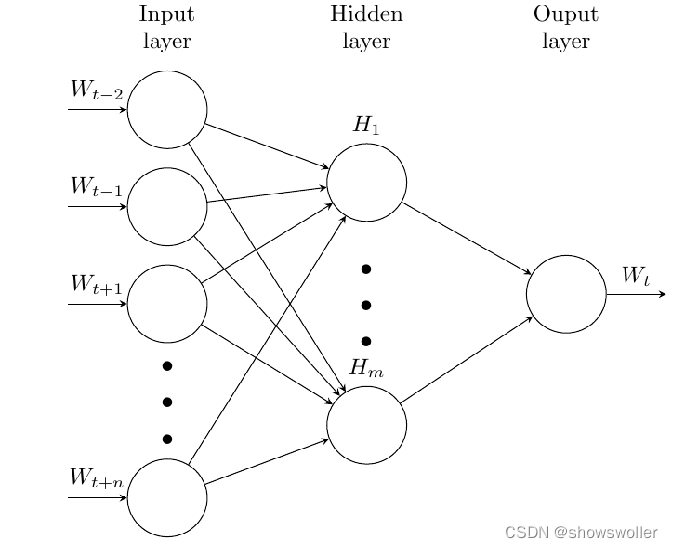
2. CBOW
Continues Bag of Words
拿一个词语的上下文作为输入,来预测这个词语本身
4. LSA
LSA使用奇异值分解(SVD)技术来减少特征空间的维数,并捕捉词之间的隐含关系。
- 优点:能够改善稀疏性问题,捕捉词义关系。
- 缺点:计算复杂,难以处理非常大的语料库。
5. GloVe
GloVe结合了矩阵分解和局部上下文窗口的优点。它通过词与词共现的概率信息来生成词向量。
- 优点:在全局语料统计和局部上下文信息之间找到了平衡。
- 缺点:需要大量的语料数据来有效训练。
6. CoVe
原论文:(2017) Learned in Translation: Contextualized Word Vectors
早期LM的感觉
CoVe是一种基于上下文的词嵌入方法,它利用序列到序列的模型从大量翻译数据中学习词向量。
- 优点:能够捕捉上下文中的词义变化,处理多义性问题。
- 缺点:模型较为复杂,需要大量的训练数据和计算资源。
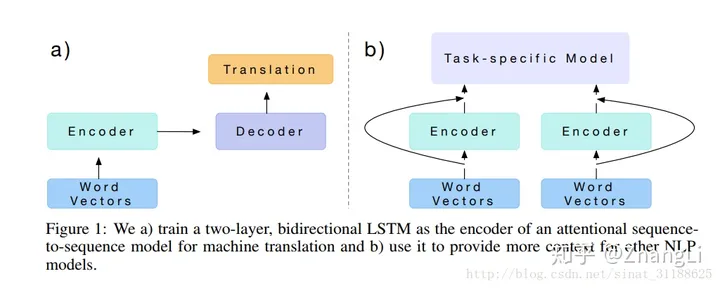
Cove: 从Word2Vec/Glove的启示 - 知乎
以上就是几种传统的词嵌入方法的简介。每种方法都有其独特之处,选择适合的词嵌入技术可以极大地提升自然语言处理任务的性能。希望这篇文章能帮助你更好地理解不同的词嵌入方法,为你的NLP项目选择合适的技术。
参考资料:
- 文本向量化的六种常见模式
- 还没看完:
- [NLP] 秒懂词向量Word2vec的本质 - 知乎(整理到“我举个例子,假设全世界所有的词语总共有 V 个,这 V 个词语有自己的先后顺序,假设『吴彦”这一行)
- 全面理解word2vec
- word2vec简介
- 词向量学习算法 Glove - 简书
- A Neural Probabilistic Language Model
- NLP方向Word2vec算法面试题6道|含解析
- (2011 PMLR) Deep Learning for Efficient Discriminative Parsing
- 深度学习word2vec笔记之基础篇-CSDN博客
- word2vec Explained: deriving Mikolov et al.'s negative-sampling word-embedding method
- word2vec Parameter Learning Explained
- word2vec 相比之前的 Word Embedding 方法好在什么地方? - 知乎
- (2016 国科大博士论文) 基于神经网络的词和文档语义向量表示方法研究
- On word embeddings - Part 2: Approximating the Softmax
这篇关于传统词嵌入方法的千层套路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




