本文主要是介绍java每日一记 —— MySQL窗口函数的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MySQL窗口函数
- 1.什么时窗口函数
- 2.窗口函数的基本应用
- 2.1.排序函数
- 2.2.分布函数
- 2.3.前后函数
- 2.4.头尾函数
- 2.5.聚合函数
- 2.6.其他函数
窗口函数时MySQL8.0中的
注意:窗口函数也有人称为“开窗函数”
1.什么时窗口函数
引入问题:让我们从一个实际的问题开始。假设我们有一个销售数据表,我们需要计算每个销售人员每个月的销售额,并且还要知道他们的总销售额在整个团队中的排名
1.简单来说,它是一种可以在一列或多列上进行计算,并为每一行返回一个结果的函数。
2.举个例子:
假设我们有一个销售表,包含每个销售人员每个月的销售额。如果我们想要知道每个销售人员每个月的销售额在整个团队中的排名,就可以使用窗口函数ROW_NUMBER()。这个函数会为每行生成一个唯一的数字,表示它的位置。我们可以按照月份和销售额降序排序,这样就可以得到每个销售人员每个月的销售额排名
3.窗口函数还可以用于计算平均值、总和、最大值、最小值等统计信息,以及百分位数、移动平均值等高级统计信息。这些功能对于数据分析来说都是非常有用的
4.窗口函数的语法
[窗口函数](参数)
OVER ([PARTITION BY 列名][ORDER BY 列名 ASC|DESC][ROWS BETWEEN x AND y]
)
5.解释:
- 窗口函数:这是一项标准的函数,例如COUNT(), SUM(), AVG(), MIN(), MAX()等
- 参数:这是传递给窗口函数的参数,具体取决于您正在使用的窗口函数类型
- PARTITION BY:这是用来将结果集分为多个逻辑分区的关键字。它会将行分成多组,然后对每一组独立地应用窗口函数
- ORDER BY:这是用来指定结果集中行的顺序的关键字。你可以将列名放在括号中,并使用ASC或DESC关键字来指定升序或降序排序
- ROWS BETWEEN x AND y:这是用来指定应用于哪一行范围的关键字
2.窗口函数的基本应用
MySQL中窗口函数共分为5类:
- 排序函数:用于为窗口内的每一行生成一个序号。例如 ROW_NUMBER(),RANK(),DENSE_RANK() 等
- 分布函数:用于计算窗口内的每一行在整个分区中的相对位置。例如 PERCENT_RANK(),CUME_DIST() 等
- 前后函数:用于获取窗口内的当前行的前后某一行的值。例如 LAG(),LEAD() 等
- 头尾函数:用于获取窗口内的第一行或最后一行的值。例如 FIRST_VALUE(),LAST_VALUE() 等
- 聚合函数:用于计算窗口内的某个字段的聚合值。例如 SUM(),AVG(),MIN(),MAX() 等。
准备SQL
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (`id` bigint NOT NULL,`ename` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,`age` int NULL DEFAULT NULL,`dept_id` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = DYNAMIC;INSERT INTO `emp` VALUES (1, '乔峰', 10, '1001');
INSERT INTO `emp` VALUES (2, '段誉', 21, '1001');
INSERT INTO `emp` VALUES (3, '虚竹', 23, '1001');
INSERT INTO `emp` VALUES (4, '阿紫', 18, '1001');
INSERT INTO `emp` VALUES (5, '扫地僧', 85, '1002');
INSERT INTO `emp` VALUES (6, '李秋水', 33, '1002');
INSERT INTO `emp` VALUES (7, '鸠摩智', 50, '1002');
INSERT INTO `emp` VALUES (8, '天山童姥', 60, '1003');
INSERT INTO `emp` VALUES (9, '慕容博', 58, '1003');
INSERT INTO `emp` VALUES (10, '丁春秋', 71, '1005');
SET FOREIGN_KEY_CHECKS = 1;
2.1.排序函数
序号函数是按照一定的分组规则对每一组的数据排序并创建一个序号列
- row_number()
- rank()
- dense_rank()
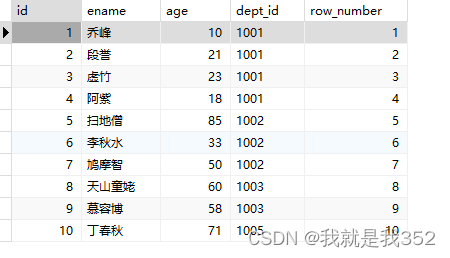
1.row_number()
row_number():为表中的每一行分配一个序号,可以指定分组(也可以不指定)及排序字段(连续且不重复),例如:1、2、3、4、5
测试SQL
SELECT id, ename, age, dept_id, row_number() OVER() as 'row_number' FROM emp;
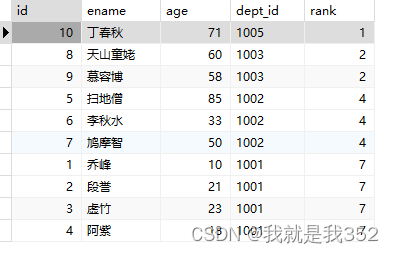
2.rank()
rank():根据排序字段为每个分组中的每一行分配一个序号。排名值相同时,序号相同,但序号中存在间隙,例如:1、1、1、4、5
测试SQL
SELECT id, ename, age, dept_id, rank() over(ORDER BY dept_id DESC) FROM emp;
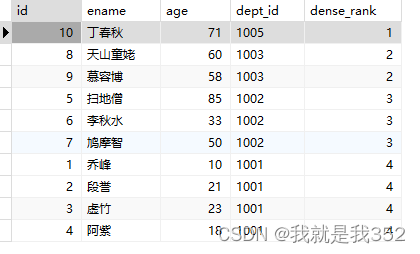
3.dense_rank()
dense_rank():根据排序字段为每个分组中的每一行分配一个序号。排名值相同时,序号相同,序号中没有间隙,例如:1、1、1、2、3
测试SQL
SELECT id, ename, age, dept_id, dense_rank() over(ORDER BY dept_id DESC) FROM emp;
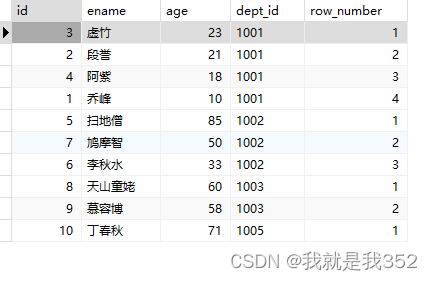
4.小练习:将每个部门下的员工按照年龄进行倒序排列
SELECT id, ename, age, dept_id, row_number() OVER(PARTITION BY dept_id ORDER BY age DESC) as 'row_number' FROM emp;
2.2.分布函数
分组内小于、等于当前rank值的行数 / 分组内总行数
- percent_rank()
- cume_dist()
1.percent_rank()
percent_rank():计算查询字段按照百分比排名
测试SQL
SELECT id, ename, age, dept_id, percent_rank() over(ORDER BY dept_id DESC) as 'percent_rank' FROM emp;
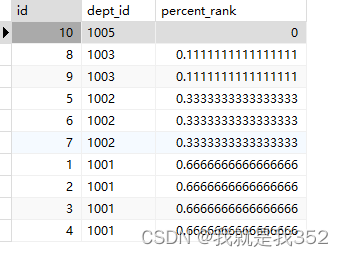
解释:根据上面的查询结果可以得出规律:
- 比
dept_id = 1005还要大的占0 - 比
dept_id = 1003还要大的占0.11 - 比
dept_id = 1002还要大的占0.33 - 比
dept_id = 1001还要大的占0.66
2.cume_dist()
cume_dist():它常用来表示一个值在一组值中的相对排名或者累积频率
测试SQL:
SELECT id, ename, age, dept_id, cume_dist() over(ORDER BY dept_id DESC) as 'cume_dist' FROM emp;

2.3.前后函数
前后函数是指用于查询当前行与其前几行或后几行数据之间关系的函数
- lag()
- lead()
lag():用于访问当前行之前(按照排序顺序)的某一行数据
1.lag()详解
语法:
LAG(expression, [offset], [default])
OVER ([PARTITION BY partition_expression]ORDER BY sort_expression
)
- expression:这是你想要从前面行获取的字段名或表达式
- offset(可选):这是一个整数,表示向前移动的行数,默认为1,即前一行。如果你想取前两行的数据,则设置为2
- default(可选):如果指定的偏移位置超出了有效的行范围(例如,对于分区中的第一行),则返回此默认值。如果不指定,默认值可能是NULL
测试SQL
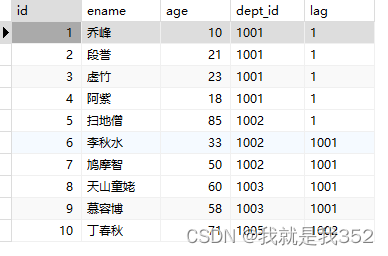
SELECT id, ename, age, dept_id, lag(dept_id, 5,1) over() as 'lag' FROM emp;
2.lead()详解:
lead():而是获取当前行之后的数据
语法
LEAD(expression, [offset], [default])
OVER ([PARTITION BY partition_expression]ORDER BY sort_expression
)
- expression:这是你想要从后面行获取的字段名或表达式
- offset(可选):这是一个整数,表示向后移动的行数,默认为1,即下一行。如果你想取后两行的数据,则设置为2
- default(可选):如果指定的偏移位置超出了有效的行范围(例如,对于分区中的最后一行),则返回此默认值。如果不指定,默认值可能是NULL
测试SQL
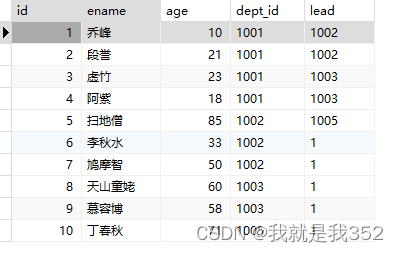
SELECT id, ename, age, dept_id, lead(dept_id, 5,1) over() as 'lead' FROM emp;
2.4.头尾函数
用于获取窗口内的首行或末行数据的函数
- first_value()
- last_value()
1.first_value()
first_value():返回指定列的第一行值
测试SQL
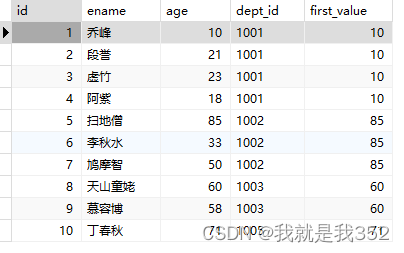
SELECT id, ename, age, dept_id, first_value(age) over(PARTITION BY dept_id) as 'first_value' FROM emp;
2.last_value()
last_value():返回指定列的最后一行
测试SQL
SELECT id, ename, age, dept_id, last_value(age) over(PARTITION BY dept_id) as 'last_value' FROM emp;
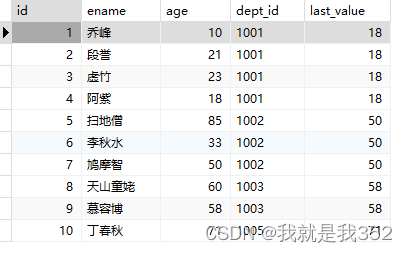
2.5.聚合函数
主要进行计算窗口函数中的数据
-
sum() over( partion by <要分列的组> order by <要排序的列> rows between <数据范围> )
-
count() over( partion by <要分列的组> order by <要排序的列> rows between <数据范围> )
-
avg() over( partion by <要分列的组> order by <要排序的列> rows between <数据范围> )
-
max() over( partion by <要分列的组> order by <要排序的列> rows between <数据范围> )
-
min() over( partion by <要分列的组> order by <要排序的列> rows between <数据范围> )
1.sum() over()
题目:统计每个部门员工的年龄
SQL
SELECT id, ename, age, dept_id, sum(age) over(PARTITION BY dept_id) as 'sum' FROM emp;
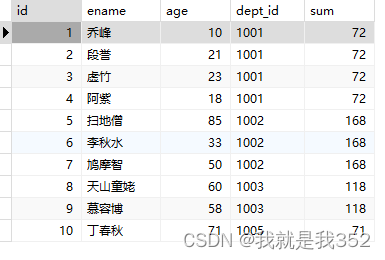
2.count() over()
题目:统计每个部门员工个数
SQL
SELECT id, ename, age, dept_id, count(age) over(PARTITION BY dept_id) as 'count' FROM emp;
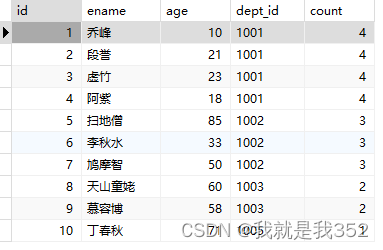
3.avg() over()
题目:统计每个部门员工年龄
SQL
SELECT id, ename, age, dept_id, avg(age) over(PARTITION BY dept_id) as 'avg' FROM emp;
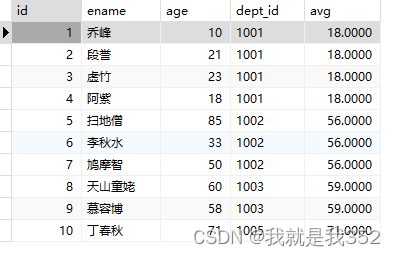
4.max() over()
题目:统计每个部门员工年龄最大的
SQL
SELECT id, ename, age, dept_id, max(age) over(PARTITION BY dept_id) as 'avg' FROM emp;
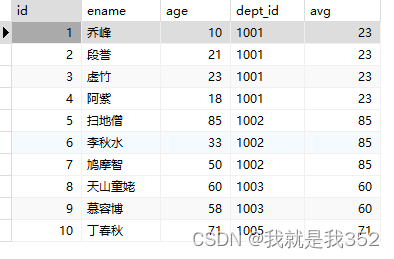
5.min() over()
题目:统计每个部门员工年龄最小的
SQL
SELECT id, ename, age, dept_id, min(age) over(PARTITION BY dept_id) as 'min' FROM emp;
2.6.其他函数
- nth_value()
- ntile()
1.nth_value()
nth_value():从一个分区内的行序列中选取第 n 个值
语法:
nth_value(expression, nth)
OVER ([PARTITION BY column1, column2, ...]ORDER BY sort_column ASC|DESC
)- expression: 要计算 nth 值的列名或表达式。
- nth: 一个正整数,表示要返回的第几个值(通常从 1 开始计数)。
- PARTITION BY: 可选参数,用于将数据集划分为多个逻辑分区,在每个分区内独立进行计算。
- ORDER BY: 必须指定的参数,用于确定在每个分区内部的行顺序。
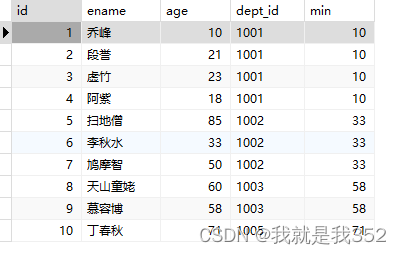
题目:获取每个部门中年龄排第二
SQL
SELECT id, ename, age, dept_id, nth_value(age, 2) over(PARTITION BY dept_id) as 'avg' FROM emp;
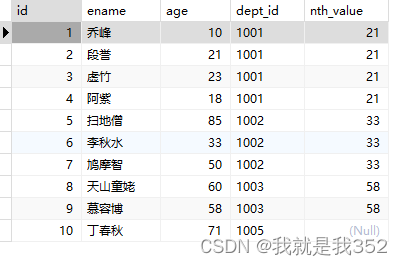
注意:如果没有就会为null
2.ntile()
ntile():用于将数据集划分为n个连续的桶
语法:
NTILE(n)
OVER ([PARTITION BY column1, column2, ...]ORDER BY sort_column ASC|DESC
)
- n: 一个正整数,表示要将数据集分成多少个桶。
- PARTITION BY: 可选参数,用于先将整个数据集按照指定列进行分区,在每个分区内独立进行分配。
- ORDER BY: 必须指定的参数,用于确定在每个分区内部如何排序行以便进行分配。
题目:将员工按照年龄分为3个等级
SQL
SELECT id, ename, age, dept_id, ntile(3) over(ORDER BY age desc) as 'ntile' FROM emp;
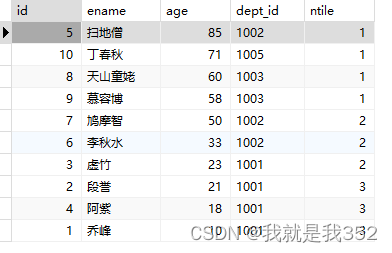
NTILE() 函数在处理数据时,如果数据行数不能被桶数整除,它会按照以下方式分配:
-
尽量均匀地将数据分配到各个桶中。
-
如果有剩余的行数无法平均分配,则这些行将会被分配到编号较小的桶里,直到所有桶都被填满。
-
也就是说,不论数据是奇数还是偶数,NTILE() 都会确保前几个桶尽可能充满,而最后一个桶可能包含比其他桶稍微多一些或少一些的数据。具体哪个桶会收到多出的数据,并不固定,而是根据排序和分区情况动态决定的。
-
例如,如果你有101条数据并使用 NTILE(5),那么前4个桶每个将包含大约20条数据(共80条),而最后一个桶将包含剩下的21条数据
这篇关于java每日一记 —— MySQL窗口函数的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




