本文主要是介绍MySql安装与使用(简明扼要),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、安装mysql前准备工作
1.1解压安装包
在此之前如需配置jdk和tomcat服务器点击进入查看目录第二章web环境搭建🫰
1.找到MySql压缩包解压即可
2.将my.ini文件复制到解压后的MySql文件夹中

1.2修改
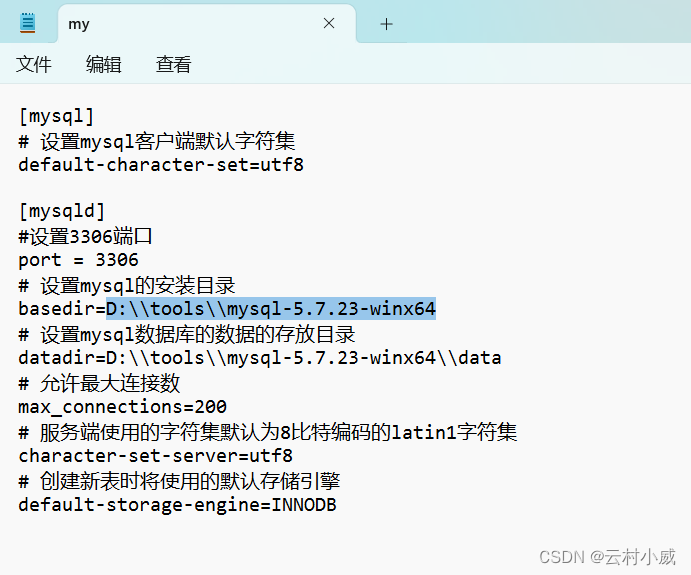
1.找到解压后MySql文件赋值其路径到my.ini文件中

2.设置mysql数据库的数据的存放目录(如图在其路径后面添加/data)
是不是很简单,一气呵成👍
二、安装服务器与初始化配置
然后在bin目录文件中打开cmd
👉👉👉注意!!! 一定要在bin文件中启动dos命令
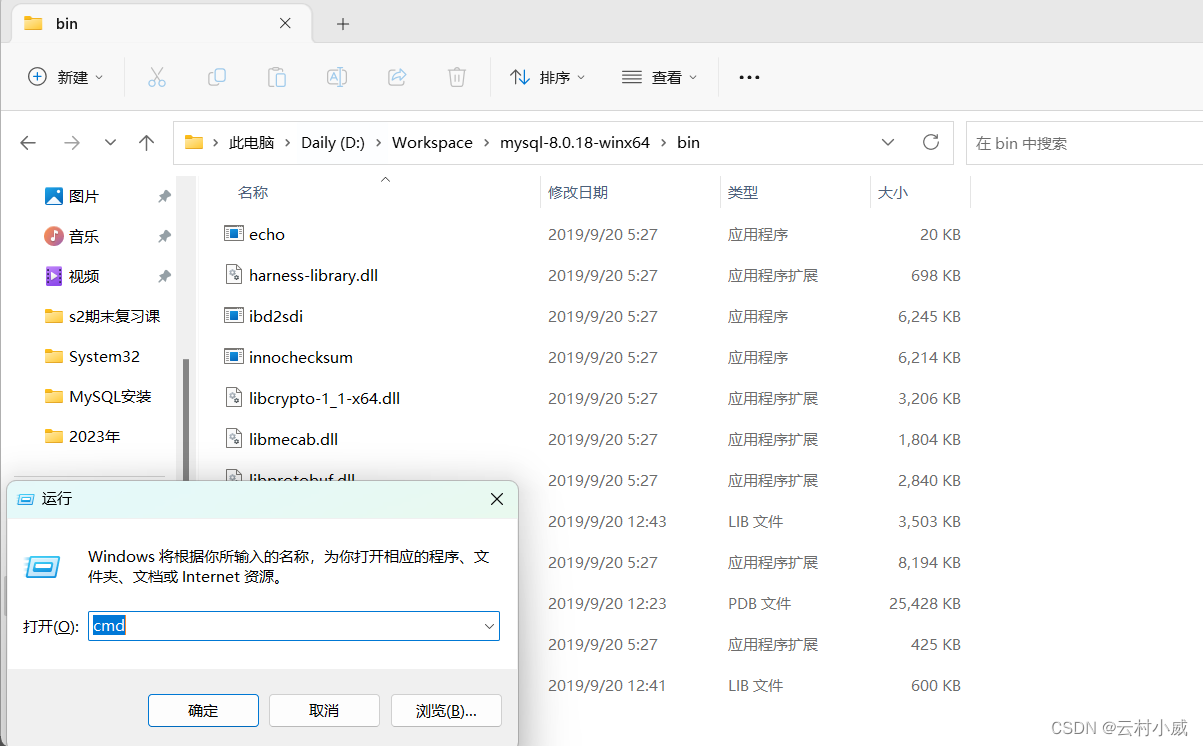 👋直接win+r错误,在后面的操作中会找不到处理文件
👋直接win+r错误,在后面的操作中会找不到处理文件

✌️在目录栏中输入cmd回车即可 !
或者通过按住shift+鼠标右击后再点击在终端打开
MySql配置流程
- 安装MySQL服务 mysqld -install
- 初始化MySQL mysqld --initialize --console
- 启动MySQL服务 net start mysql
- 记录初始密码,利用初始密码登录 mysql -P 3306 -u root -p
- 改变MySQL链接密码 ALTER USER ‘root’@‘localhost’ IDENTIFIED WITH mysql_native_password BY ‘123456’;
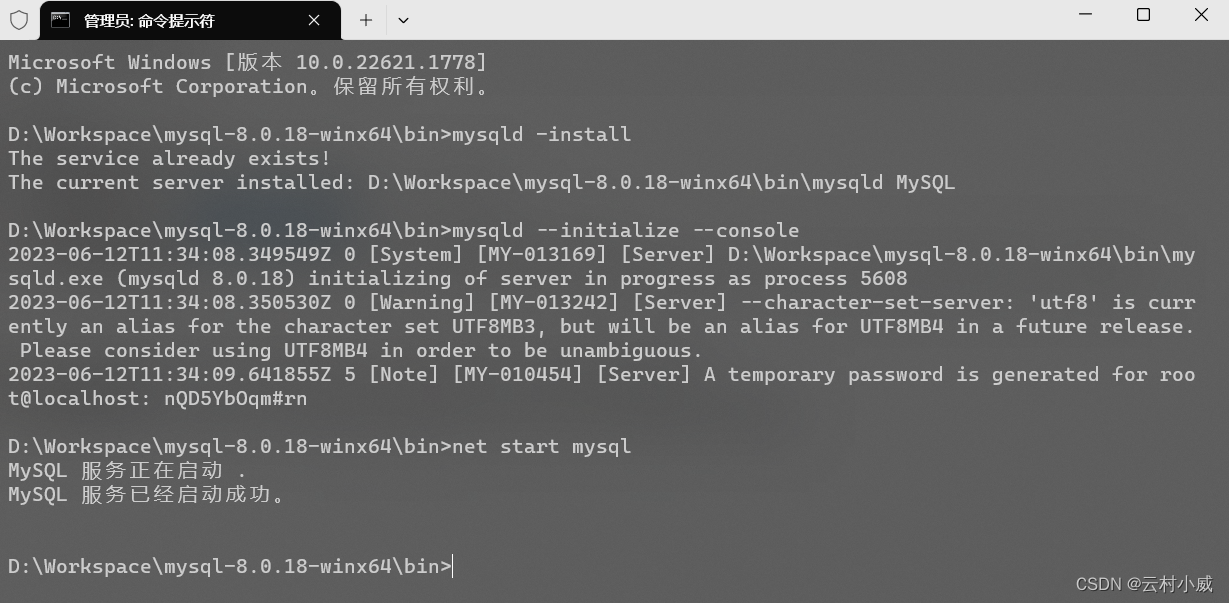
ok,到这里已经完成了三个步骤了;这里看到图中第二个步骤结束有个 @localhost: nQD5YbOqm#rn 记住这个是初始密码 nQD5YbOqm#rn
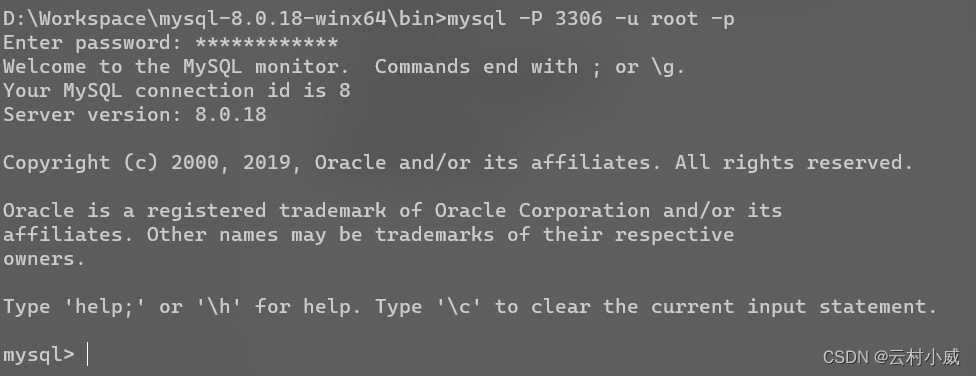
复制第四个指令,输入刚才初始密码。如图所示就已经登入成功了!

最后修改初始密码为123456,有没有不修改密码的大佬,来我公司当CTO🙂
三、安装MySql连接工具
1.直接解压这个工具包,解压即食
2.在文件夹找到这个东东,双击运行!
3.这就是打开后的界面,直接触碰连接点击MySql好吧
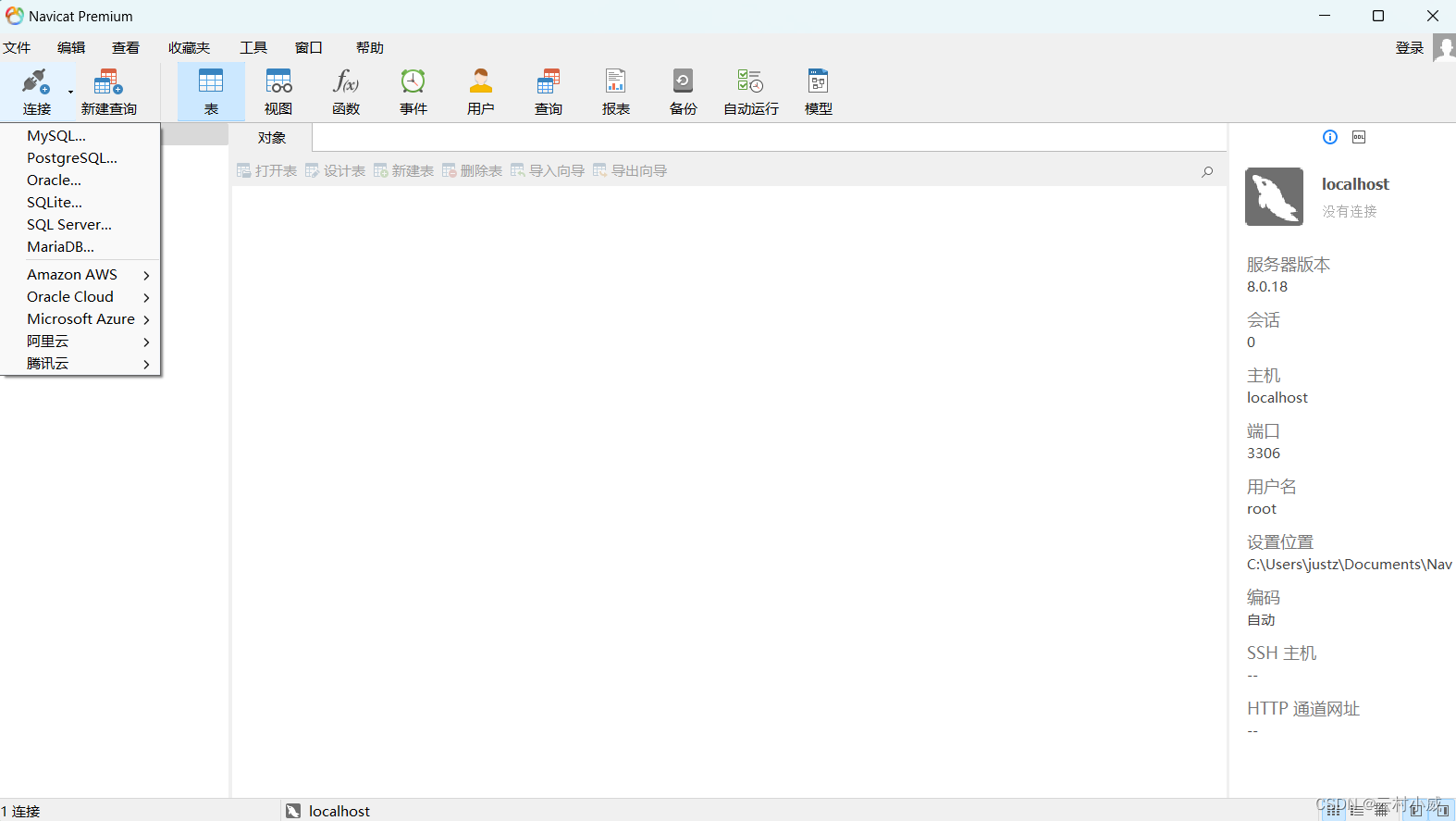
4.输入连接名就是主机名,密码…
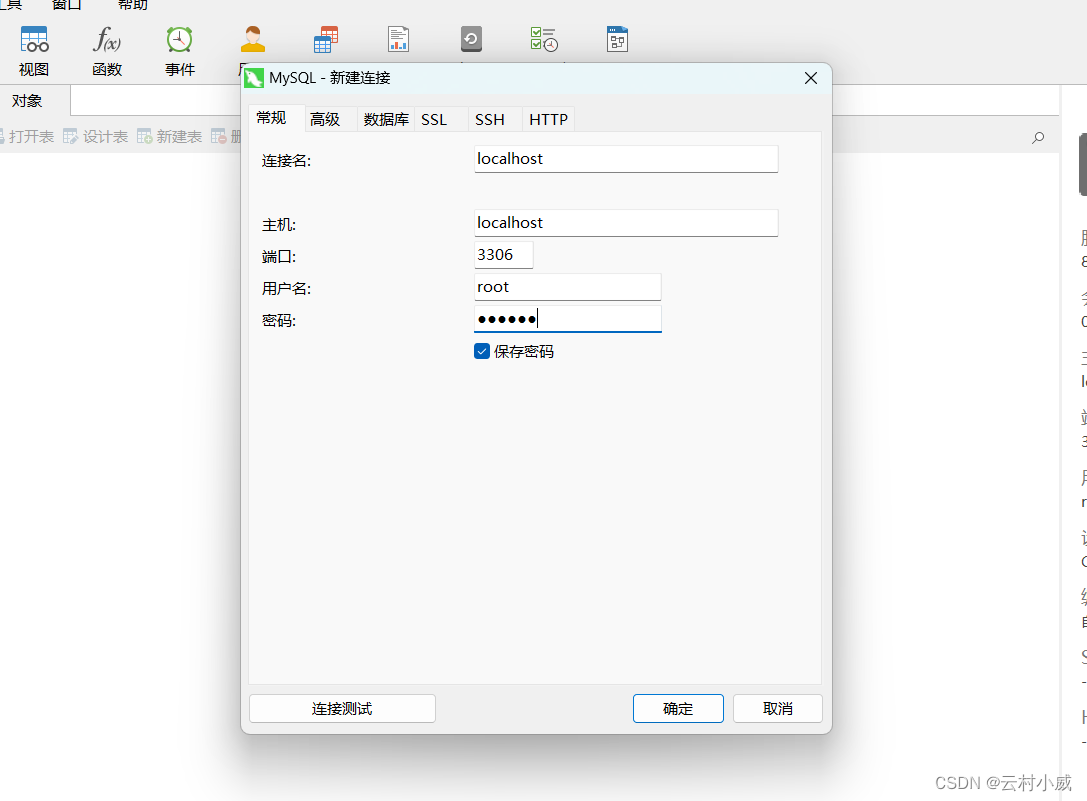
6.确认后右击localhost打开连接
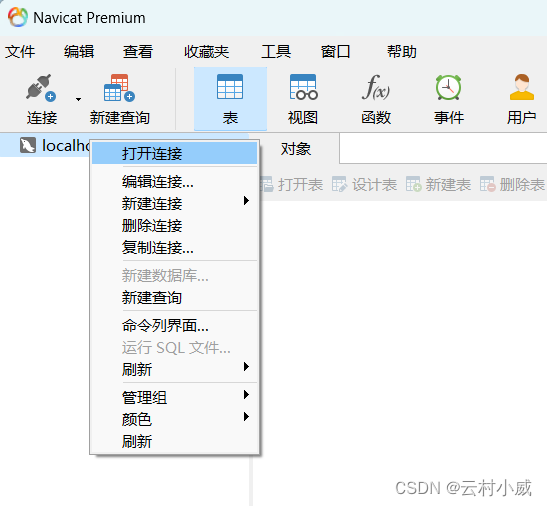
7.最后这样就成功啦!这四个都是默认数据库不用管啦!
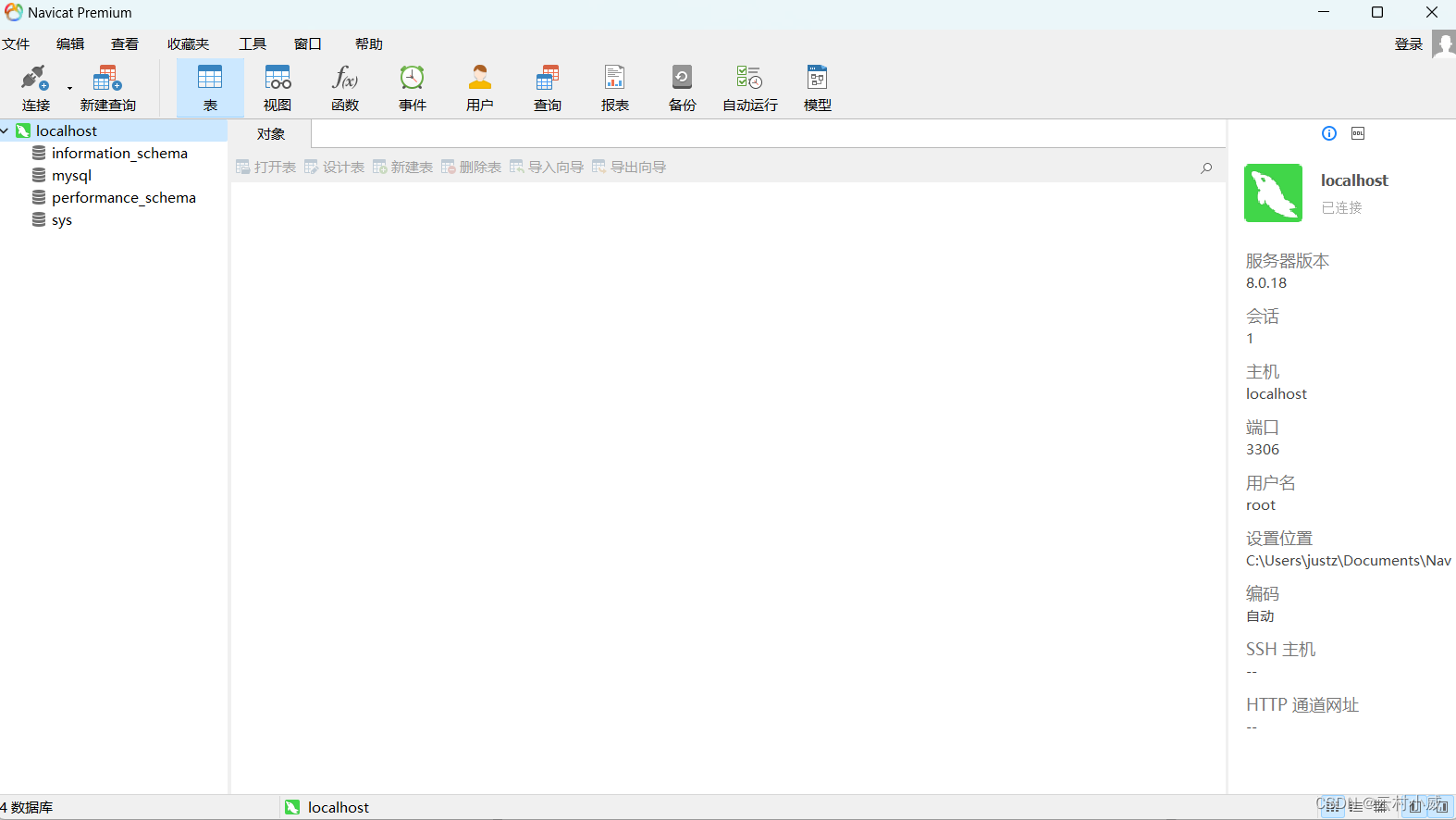
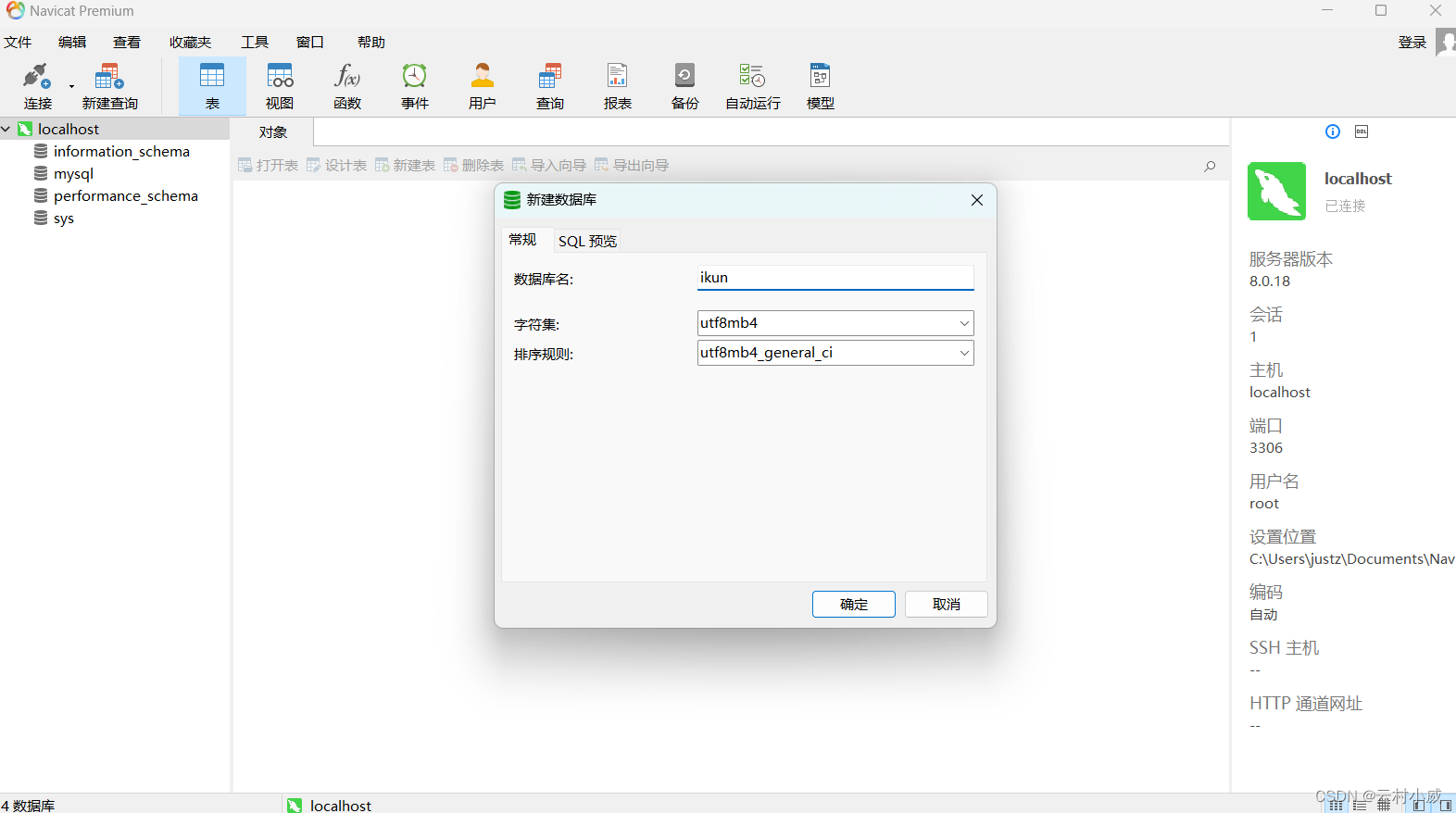
3.1新建数据库及表
右击localhost点击新建数据库,浅浅起个名字吧,后面的跟我输入一样就行,不要问我为什么🙂
然后就可以创建自己需要的表了
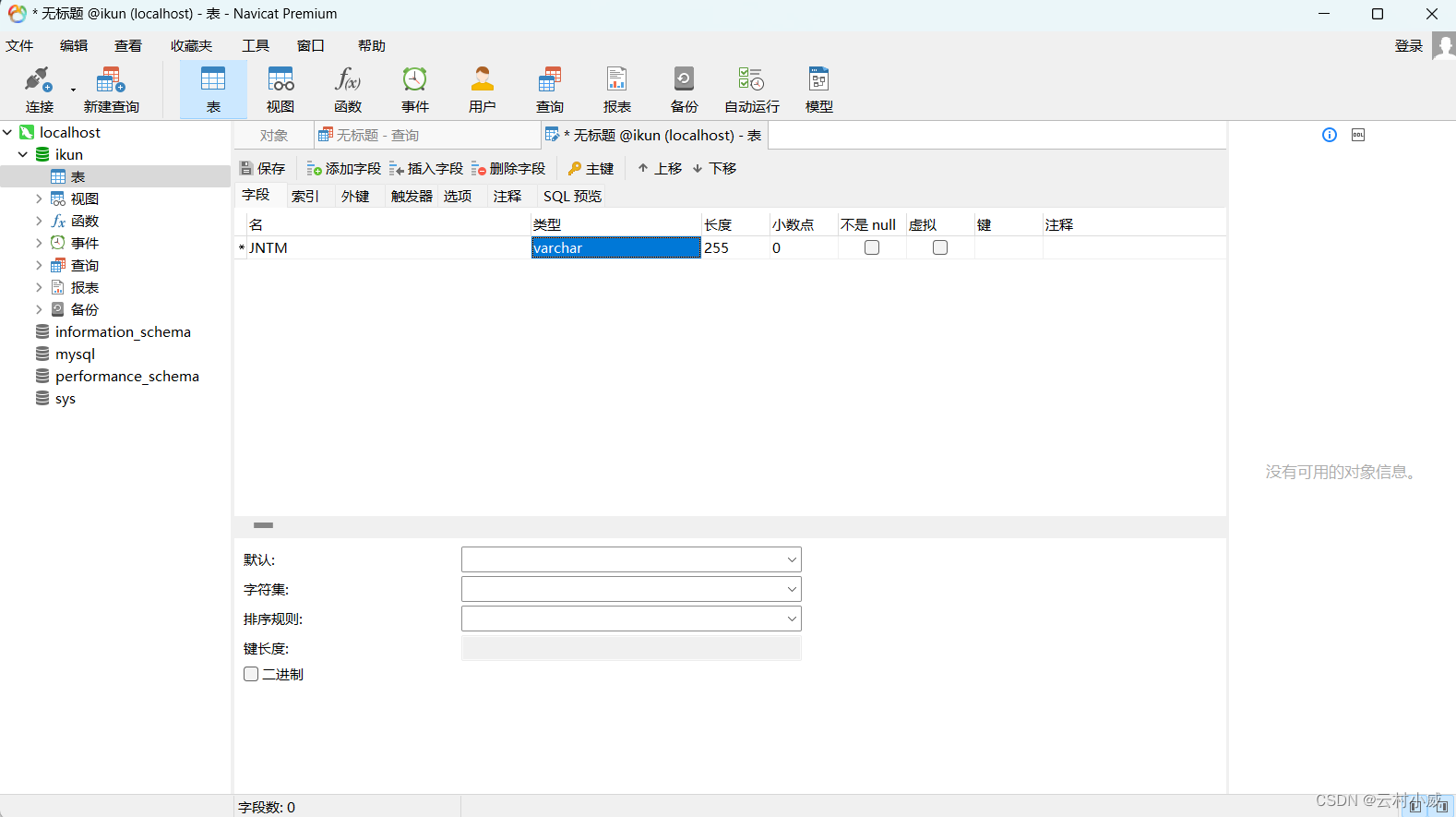
最后新建查询就可以用啦!

这篇关于MySql安装与使用(简明扼要)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





