本文主要是介绍Python的新式类和旧式类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 概述:
Python中支持多继承,也就是一个子类可以继承多个父类/基类。当一个调用一个自身没有定义的属性时,它是按照何种顺序去父类中寻找的呢?尤其是当众多父类中都包含有同名的属性,这就涉及到新式类 和 经典类的区别。
- 多继承:
class Food(object):2 3 def __init__(self, name, color):4 self.name = name5 self.color = color6 7 def eatable(self):8 print("%s can be eaten." % self.name)9
10 def appearance(self):
11 print('The color of the %s is %s.' % (self.name, self.color))
12
13
14 class Fruits(object):
15
16 def __init__(self, name, nutrition):
17 self.name = name
18 self.nutrition = nutrition
19
20 def info(self):
21 print("%s can supply much %s." % (self.name, self.nutrition))
22
23
24 class Salad(Fruits, Food): # 继承多个父类
25
26 def __init__(self, name, nutrition, color, tasty):
27 super(Salad, self).__init__(name, nutrition)
28 Food.__init__(self, name, color)
29 self.tasty = tasty
30
31 def taste(self):
32 print("%s is a little %s." % (self.name, self.tasty))
33
34
35 obj = Salad('orange', 'VC', 'orange', 'sour')
36
37 obj.eatable()
38 obj.appearance()
39 obj.info()
40 obj.taste()
上例中的Salad(Fruits,Food)继承了Fruits和Food两个父类。
supper()函数为新式类的方法,采用新式类要求最顶层的父类一定要继承于object,这样就可以用super()函数来调用父类的init()等函数。每个父类都执行且执行一次,并不会出现重复调用的情况。采用super()方法时,会自动找到第一个多继承中的第一父类。
但是如果想要继续调用其它父类init()函数或两个父类的同名函数时,就要用经典类的调用方法了,即 父类名.init(self,参数),如上例。
- 经典类vs新式类的继承顺序:
新式类
1、新式类定义时必须继承object类,继承了object类的就叫做 新式类
class Fruits(object):'新式类'pass
2、采用super()函数类调用父类的 init()等函数:
super(子类名,self).__init__(参数1,参数2,..)
3、调用父类中相同属性或者方法的顺序
新式类的调用顺序为: 广度优先查询
子类先在自己的所有父类中从左至右查询,如果没有需要的方法或属性,再到本身父类的父类中去查询。
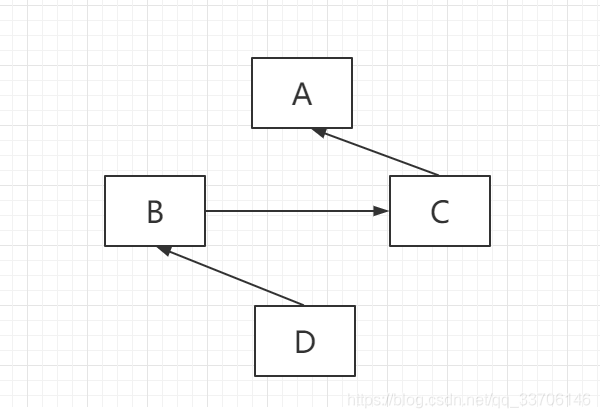
广度优先遍历是先把自己的所有属性遍历,再把所有父类遍历一遍,如果没有找到需要的属性,则在对父类的父类进行遍历,以此类推。
示例如下:
1、调用本身属性
class A(object):2 def __init__(self):3 self.n = "A"4 5 6 class B(A):7 8 def __init__(self):9 super(B, self).__init__()
10 self.n = "B"
11
12
13 class C(A):
14
15 def __init__(self):
16 super(C, self).__init__()
17 self.n = "C"
18
19
20 class D(B, C):
21
22 def __init__(self):
23 super(D, self).__init__()
24 self.n = "D"
25
26
27 d = D()
28 print(d.n)
29
30 #输出
31 D
2.注释D中的代码,获得B
class A(object):2 def __init__(self):3 self.n = "A"4 5 6 class B(A):7 8 def __init__(self):9 super(B, self).__init__()
10 self.n = "B"
11
12
13 class C(A):
14
15 def __init__(self):
16 super(C, self).__init__()
17 self.n = "C"
18
19
20 class D(B, C):
21
22 # def __init__(self):
23 # super(D, self).__init__()
24 # self.n = "D"
25 pass
26
27 d = D()
28 print(d.n)
29
30 #输出
31 B
3.注释B中的代码,获得C
class A(object):2 def __init__(self):3 self.n = "A"4 5 6 class B(A):7 8 # def __init__(self):9 # super(B, self).__init__()
10 # self.n = "B"
11 pass
12
13
14 class C(A):
15
16 def __init__(self):
17 super(C, self).__init__()
18 self.n = "C"
19
20
21 class D(B, C):
22
23 # def __init__(self):
24 # super(D, self).__init__()
25 # self.n = "D"
26 pass
27
28 d = D()
29 print(d.n)
30
31 #输出
32 C
4.注释C中的代码,获得A
class A(object):2 def __init__(self):3 self.n = "A"4 5 6 class B(A):7 8 # def __init__(self):9 # super(B, self).__init__()
10 # self.n = "B"
11 pass
12
13
14 class C(A):
15 #
16 # def __init__(self):
17 # super(C, self).__init__()
18 # self.n = "C"
19 pass
20
21
22 class D(B, C):
23
24 # def __init__(self):
25 # super(D, self).__init__()
26 # self.n = "D"
27 pass
28
29 d = D()
30 print(d.n)
31
32 #输出
33 A
经典类
1、经典类定义,什么都不继承
class Fruit:'经典类'pass
2、继承父类的init()等函数或属性
父类名.__init__(self, 参数1,参数2,....)
3、调用父类中相同属性或者方法的顺序
在 Python3 中,多继承的查询顺序都是 广度优先查询
经典类的调用顺序为: 深度优先查询
子类会沿着父类的父类这样的顺序查询,如果都没有,会返回查找另一个父类。
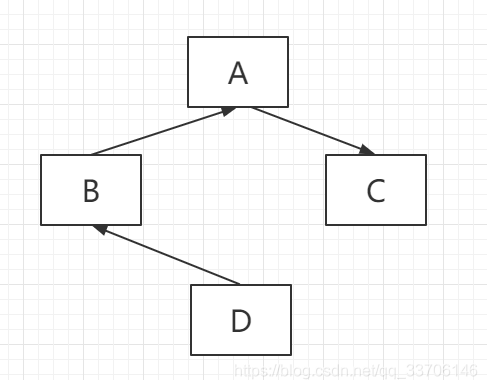
示例如下:
1.调用本身的属性
class A:#经典类2 def __init__(self):3 self.n = "A"4 5 class B(A):6 pass7 def __init__(self):8 self.n = "B"9
10 class C(A):
11 def __init__(self):
12 self.n = "C"
13
14 class D(B,C):
15 def __init__(self):
16 self.n = "D"
17
18 d = D()
19 print(d.n)
20
21 #输出
22 D
23
24 全部代码
- 注释D中的代码,获得B
class A:2 def __init__(self):3 self.n = "A"4 5 class B(A):6 def __init__(self):7 self.n = "B"8 9 class C(A):
10 def __init__(self):
11 self.n = "C"
12
13 class D(B,C):
14 pass
15
16 d = D()
17 print(d.n)
18
19 #输出
20 B
3.注释B中的代码,获得A
class A:2 def __init__(self):3 self.n = "A"4 5 class B(A):6 pass7 8 class C(A):9 def __init__(self):
10 self.n = "C"
11
12 class D(B,C):
13 pass
14
15 d = D()
16 print(d.n)
17
18 #输出
19 A
4.注释A中的代码,获得C
class A:2 pass3 4 class B(A):5 pass6 7 class C(A):8 def __init__(self):9 self.n = "C"
10
11 class D(B,C):
12 pass
13
14 d = D()
15 print(d.n)
16
17 #输出
18 C
- 总结:
1、新式类继承object类,经典类不继承任何类
2、新式类用super关键字继承构造方法,经典类用 父类.init(self)来继承
3、新式类:广度优先查询,经典类:深度优先查询(因为新式类讲究的是新,所以要找最近的,最新的;然后经典的讲究古老,所以更远更深的)
4、值得注意的是,我们上面是在python2中做的,在python3中不管是经典类还是新式类,都是采用的是广度优先查询,已经废弃2中的深度查询了
这篇关于Python的新式类和旧式类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




