本文主要是介绍图数据库Gremlin语法(2)| 边的操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
图数据库Gremlin语法(2)| 边的操作
文章目录
- 图数据库Gremlin语法(2)| 边的操作
- @[TOC]
- 前言
- 一、本章学习重点
- 二、边遍历概念
- 三、边基本操作
- 四、边混合操作
- 总结
文章目录
- 图数据库Gremlin语法(2)| 边的操作
- @[TOC]
- 前言
- 一、本章学习重点
- 二、边遍历概念
- 三、边基本操作
- 四、边混合操作
- 总结
前言
Gremlin语言是图数据库最主流的查询语言,是Apache TinkerPop框架下规范的图语言,相当于SQL之于关系型数据库。为了图数据库使用者更好的掌握Gremlin这门图语言,我们对Gremlin Steps进行了分类与总结,接下来将会出一个Gremlin系列文章(分25期来完成这个计划),每一期会针对一类Step进行语法讲解与实例分析。
一、本章学习重点
out()、in()、both()、outE()、inE()、bothE()、outV()、inV()、bothV()、otherV()
二、边遍历概念
边遍历是指通过顶点来访问与其有关联边的邻接顶点(或者仅访问邻接边),边遍历是图数据库与图计算的核心。我们先以TinkerPop官网的例子来解释一下边遍历的相关Steps:
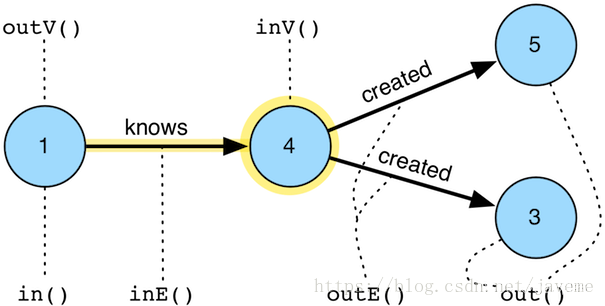
顶点为基准的Steps(如上图中的顶点“4”):
- out(label): 根据指定的EdgeLabel来访问顶点的OUT方向邻接点(可以是零个EdgeLabel,代表所有类型边;也可以一个或多个EdgeLabel,代表任意给定EdgeLabel的边,下同)
- in(label): 根据指定的EdgeLabel来访问顶点的IN方向邻接点
- both(label): 根据指定的EdgeLabel来访问顶点的双向邻接点
- outE(label): 根据指定的EdgeLabel来访问顶点的OUT方向邻接边
- inE(label): 根据指定的EdgeLabel来访问顶点的IN方向邻接边
- bothE(label): 根据指定的EdgeLabel来访问顶点的双向邻接边
边为基准的Steps(如上图中的边“knows”):
- outV(): 访问边的出顶点(注意:这里是以边为基准,上述Step均以顶点为基准),出顶点是指边的起始顶点
- inV(): 访问边的入顶点,入顶点是指边的目标顶点,也就是箭头指向的顶点
- bothV(): 访问边的双向顶点
- otherV(): 访问边的伙伴顶点,即相对于基准顶点而言的另一端的顶点
三、边基本操作
out()、in()、both()、outE()、inE()、bothE()、inV()、outV()、bothV()、otherV()
1、out():访问顶点的OUT方向邻接点
// 先查询图中所有的顶点
// 然后访问顶点的OUT方向邻接点
// 注意:out()的基准必须是顶点
g.V().out()
// 访问某个顶点的OUT方向邻接点
// 注意'id1'是顶点的id
// 该id是插入顶点时自动生成的
g.V('id1').out()
// 访问某个顶点的OUT方向邻接点
// 且限制仅“define”类型的边相连的顶点
g.V('id1').out('define')
g.V('id1').out()
g.V('id1').out('define', 'contains')
2、in():访问顶点的IN方向邻接点
示例:
// 访问某个顶点的IN方向邻接点
g.V('id1').in()
// 访问某个顶点的IN方向邻接点
// 且限制了关联边的类型
g.V('id1').in('implements')3、both():访问顶点的双向邻接点
示例:
// 访问某个顶点的双向邻接点
g.V('id1').both()
// 访问某个顶点的双向邻接点
// 且限制了关联边的类型
g.V('id1').both('implements', 'define')4、outE():访问顶点的OUT方向邻接边
示例:
// 访问某个顶点的OUT方向邻接边
g.V('id1').outE()// 访问某个顶点的OUT方向邻接边
// 且限制了关联边的类型
g.V('id1').outE('define')5、inE(): 访问顶点的IN方向邻接边
示例:
// 访问某个顶点的IN方向邻接边
g.V('id1').inE()// 访问某个顶点的IN方向邻接边
// 且限制了关联边的类型
g.V('id1').inE('implements')6、bothE(): 访问顶点的双向邻接边
示例:
// 访问某个顶点的双向邻接边
g.V('id1').bothE()// 访问某个顶点的双向邻接边
// 且限制了关联边的类型
g.V('id1').bothE('define', 'implements')7、outV(): 访问边的出顶点
示例:
// 访问某个顶点的IN邻接边
// 然后获取边的出顶点
g.V('id1').inE().outV()//一般情况下,inE().outV()等价于in()
g.V('id1').outE().outV()8、inV(): 访问边的入顶点
示例:
// 访问某个顶点的OUT邻接边
// 然后获取边的入顶点
g.V('id1').outE().inV()//一般情况下,outE().inV()等价于out()
g.V('3:TinkerPop').inE().inV()9、bothV(): 访问边的双向顶点
注意:bothV()会把源顶点也一起返回,因此只要源顶点有多少条出边,结果集中就会出现多少次源顶点
示例:
// 访问某个顶点的OUT邻接边
// 然后获取边的双向顶点
g.V('id1').outE().bothV()10、otherV(): 访问边的伙伴顶点
示例:
// 访问某个顶点的OUT邻接边
// 然后获取边的伙伴顶点
g.V('id1').outE().otherV()
//一般情况下,outE().otherV()等价于out(),inE().otherV()等价于in()
// 访问某个顶点的双向邻接边
// 然后获取边的伙伴顶点
g.V('id1').bothE().otherV()
//一般情况下,bothE().otherV()等价于both()四、边混合操作
1、多度查询
// 4度out()查询
// 通过id找到“javeme”作者顶点
// 通过out()访问其创建的软件
// 继续通过out()访问软件实现的框架
// 继续通过out()访问框架包含的软件
// 继续通过out()访问软件支持的语言
g.V('id1').out('created').out('implements').out('contains').out('supports')2、查询支持Gremlin语言的软件的作者
// 通过id找到“Gremlin”语言顶点
// 通过in()访问支持Gremlin的软件
// 继续通过in()访问软件的作者
g.V('id1').in('supports').in('created')2、查询某个作者的共同作者
// 通过id找到“javeme”作者顶点
// 通过out()访问其创建的软件
// 通过in()访问软件的所有作者
g.V('id1').out('created').in('created')总结
深入学习Gremlin 系列文章链接汇总连接:https://blog.csdn.net/javeme/article/details/82631834s
这篇关于图数据库Gremlin语法(2)| 边的操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






