本文主要是介绍用TeXStudio打开WinEdt Latex中文乱码的解决办法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题导读:
在一开始学习LaTeX的时候,网上找了一套讲解视频,老师用的是WinEdt进行讲解。所以我是用WinEdt进入到LaTeX的世界。然而身边很多同事都是在使用TeXStudio编辑论文。受同事的影响,后来我也开始使用TeXStudio。
由于TeXStudio论文编写页面 和 编译后的显示页面可以一分为二在一个屏中,非常方便修改论文和查看编译后的效果,而WinEdt是分为两个单独的页面的。此外,TexStudio编译速度很快,没有WinEdt的那个一闪一顿的感觉,于是很快放弃使用WinEdt,转而喜欢用TeXStudio。
问题描述:不过最近发现如果直接用TeXStudio打开原来的WinEdt编辑的文档,如果包括中文的,打开后的中文是乱码,由于编译前是乱码,没有办法进行修改。
经过试验后,用如下办法解决:
1、把用WinEdt编辑的tex格式的文档,用记事本打开,把文档的编码格式转成UTF-8格式。如图:
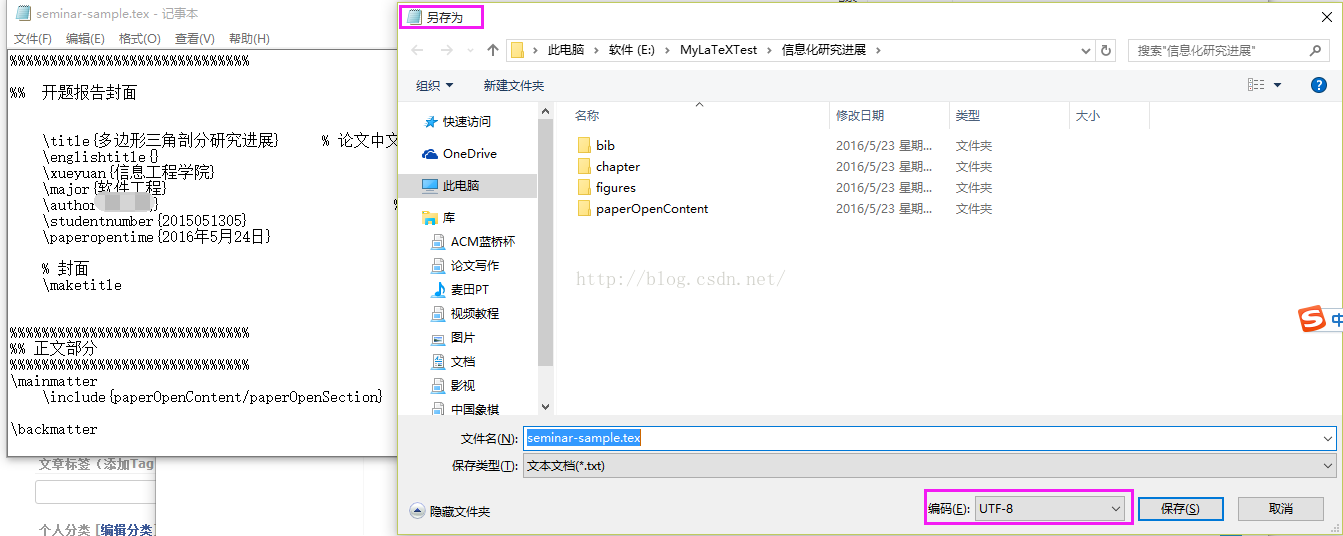
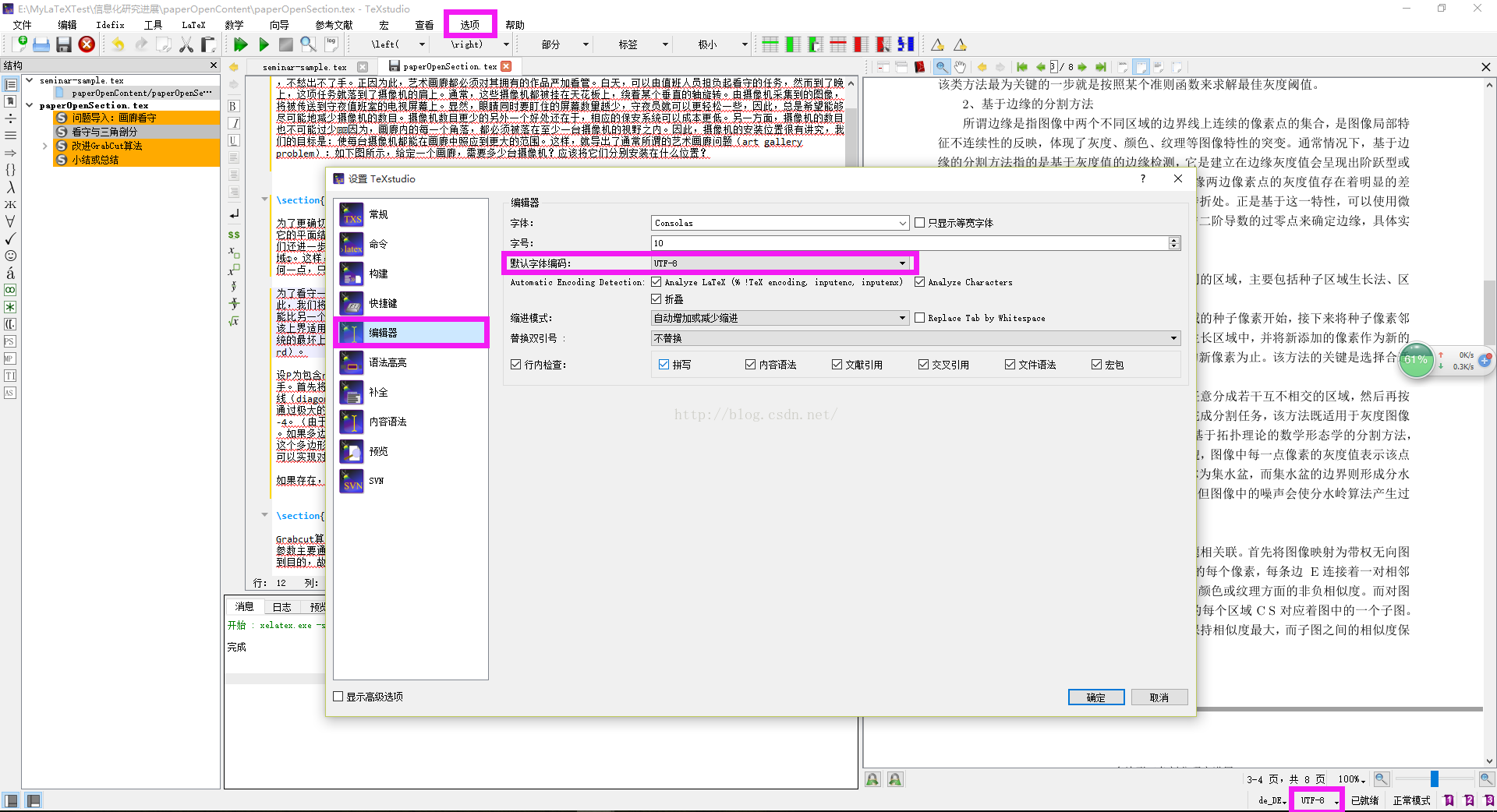
2、把TeXstudio软件打开。选项---设置TeXStudio---编辑器---默认字体编码---UTF-8.
然后在TeXstudio软件右下角的编码栏中选择UTF-8格式。
3、用TeXStudio打开转码后的tex格式的文档。已经可以正常显示中文信息。
这篇关于用TeXStudio打开WinEdt Latex中文乱码的解决办法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






