本文主要是介绍学习Redis好一阵了,我对它有了一些新的看法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
本篇文章不是一篇具体的教程,我打算记录一下自己对Redis的一些思考。说来惭愧,我刚接触Redis的时候只是简单地使用了一下,背了一些面试题,就在简历上写下了Redis这个技能点。
我们能在网络上轻易地找到关于Redis具体知识点的讲解,但很少有文字说明为什么会有这项技术,我希望通过本文总结一下个人目前对Redis的理解。
1. 初识Redis
最开始的时候,我是通过网络上面的一些项目教程了解到Redis的,当时教程里说把首页数据放到Redis里,能够加快首页数据的访问速度,于是我就照做了。代码跑起来后,发现好像确实加载得蛮快的,就当完成了。
项目做完后,写到了简历里,顺便在技能里写上熟练使用Redis,再背了几道关于Redis的数据类型,持久化机制的面试题,便去找实习了。
当时面试的时候面试官问我:你为什么使用Redis呀?
我按照项目教程里说的复述了一遍:因为能让首页更快地加载数据,咱们的产品首页是很重要,越快加载出数据,用户越满意......
现在回想起来真是哭笑不得,你也不能说这个回答有问题,Redis用作缓存的一大亮点就是能够加快数据查询效率,但是如果从技术面试的角度看,这个回答其实更应该从技术的角度去答,这也是促使我写这篇文章的冲动之一。
2. 为什么要有Redis这项技术?(你为什么用Redis)
如果现在再被问到为什么要用Redis,我打算从计算机的存储结构开始聊。
计算机界有一本名书《深入理解计算机系统》,里面有一幅关于计算机存储结构的图,非常经典:
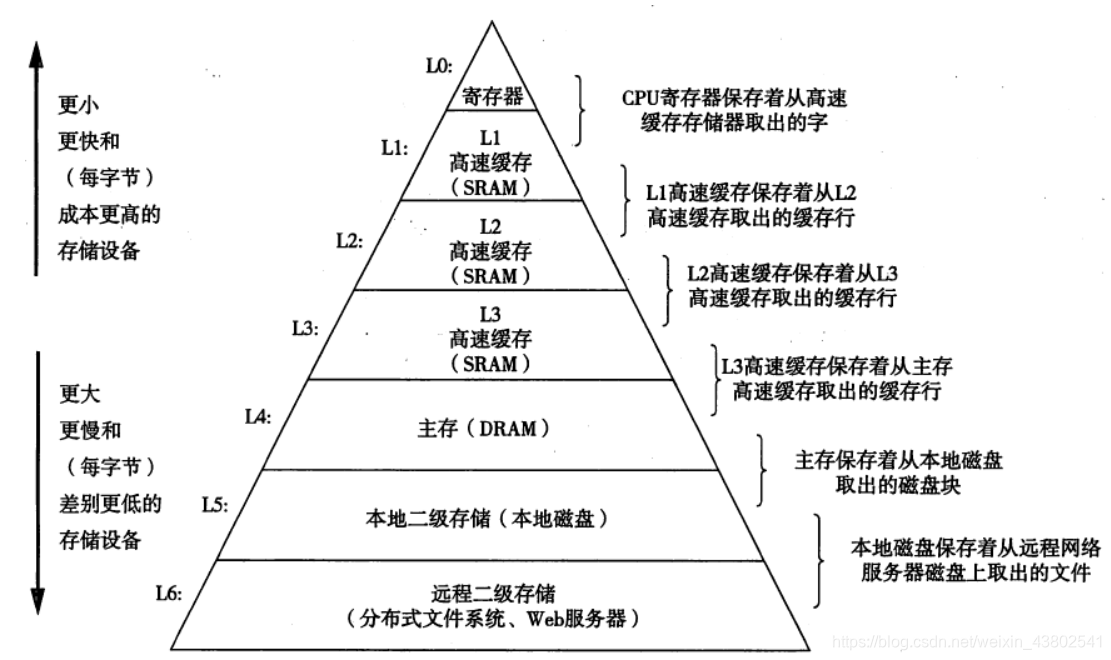
由图可见计算机的存储器是一个金字塔结构,越上层的存储器存储效率越高,越下层的存储效率越低。而计算机中内存的层级位于磁盘之上,内存的存储效率要比磁盘快得多。
正常情况下,我们会把应用的数据存放在数据库中,数据库把数据存放在磁盘;而Redis是一款基于内存的存储系统,数据都存在内存里,这就是从Redis读取数据比从数据库读取数据要快的根本原因了。
看到这里你可能会说,把数据存在内存有啥了不起的,我可以用谷歌的guava呀!再不济,我可以直接new一个HashMap存数据呀,这不都是基于内存的吗?
这个问题让我联想起了我在网上看面经的时候看到的一道题:如果让你设计一个缓存,你会怎么设计?
大家可以想一下guava和Map集合使用时的缺点是什么?
很明显一点就是这两者虽然基于内存,但他们使用的是jvm的内存,如果jvm挂掉或者重启了,数据也就丢失了。这就能方便我们联想到Redis的持久化机制,Redis的持久化机制使得内存中的数据能够持久化到磁盘上,解决内存数据掉电易失的问题,而且Redis是一款中间件,无需依赖于jvm。
(当初我只是死背Redis的持久化机制,并没有想过为什么。我想搞清楚了这背后的关系后再去学习,能够学得更扎实一些吧)
再换一个角度:既然数据库是因为磁盘才慢,那为啥不再内存里实现数据库呢?
还别说,SAP公司还真有基于内存的数据库系统,但是使用内存有一个致命的缺点:那就是贵!能买得起那套软件和巨大内存机器的公司毕竟是少数,所以说为什么要使用Redis,就是因为他在低效的磁盘和昂贵的内存中取了一个折中。
补充:面试的时候还被问到一个问题:Redis的内存淘汰机制
当时直接懵圈了,后来想了一下其实这是一个再正常不过的考点了:Redis把数据存放在内存,内存的空间有限,总会有用完的一天。当内存使用完之后肯定需要有相应的内存淘汰策略来释放内存。
不过说到内存淘汰,我还想起一个高级点的知识点,由于Redis的内存是有限的,我们使用内存的时候应该更加小心。Redis内部是有许多高效使用内存的招数的,比如说我们存放用户信息的时候,把用户信息存成一个hash,要比把用户信息逐条用key-value存储占的空间小得多,这些知识你可以在Redid的官网上找到。
3. 关于Redis的主从复制,哨兵,集群
在学习Redis之前,我对分布式的知识了解得非常少。当时为了面试背Redis的面试题,背到有关主从复制,哨兵,集群等知识点的时候,我既兴奋又茫然。感觉自己背完后掌握了许多分布式的知识,但是把这些知识点都揉在一起了,根本不知道这背后的逻辑是什么。现在想通了一些,应该好好记下来:
在扩展到多机之前,我们先想一下单机的Redis有什么缺点:
- 有可能出现单点故障,这样Redis服务就不可用了
- 单一台机器的内存有限,存储不了太多的数据
- 如果访问量很大的话,单台机器压力会很大
通过第一个缺点,我们可以引出为什么需要主从复制和哨兵。大家想一想,如果我们只有一个Redis服务,要是服务挂了就没法用了,但如果我们安排多一台Redis服务器,它的数据时刻与第一台Redis的数据保持一致,这样当第一台Redis挂掉后,我们就可以把请求迁移到第二台Redis上,这样Redis服务的可用性就提高了。为了让第二台Redis的数据与第一台Redis保持一致,我们就需要用到主从复制。
有时候,可能一主一从的配置还是不够保险,这个时候我们就要为主节点配置两个或以上的从节点,那么问题来了,要是主节点挂了,该通过什么方案在从节点中选出新的主节点呢?这就用到了哨兵机制。
而且在一主多从的情况下,我们使用主从复制让多台Redis的数据保持一致,这个时候我们就可以把读请求分摊到从节点上,这样能有效缓解主节点的读压力。
但如果Redis的写请求压力也很大,而且数据量很大,这个时候为Redis增加备份机的横向扩展已经帮不上什么忙了,这个时候我们就要考虑纵向扩展,增加多台Redis分摊写请求,让不同的key落到不同的机器上。这个时候我们就要考虑使用一致性哈希等算法把不同的key分给不同的机器。
Redis自身也提供了集群机制,但内部使用的不是一致性哈希,而是哈希槽。简单来说就是在哈希槽中划分不同的区间,不同的区间对应不同的机制;当扩容或缩减的时候有相应的哈希槽调整策略。
我最初学习Redis的多机策略的时候就是搞不清楚集群,主从复制,哨兵机制之间的关系。其实集群就是一套完整的Redis多机解决方案,他有效解决了单机Redis的所有问题。当你在集群中为某个节点配置从机的时候,主从节点间同步用的就是主从复制。主节点挂掉之后,从节点的选取,内部的逻辑就和哨兵机制相似。当我们使用集群机制的时候,就可以省去自己写类似一致性哈希这样的分摊逻辑,集群机制会给节点加上相应的数据结构来完成这些功能。
如果想深入了解集群背后的实现原理,我推荐这样一个学习路线:
- 首先登录官网,按照官网的步骤学习配置主从复制,配置哨兵,搭建集群
- 然后看《Redis的设计与实现》这本书,阅读主从复制,哨兵和集群这三个章节
4. 后话
个人觉得,如果把文章中提到的Redis的点都深入了解一下,Redis基本能算入门了。
写下这篇感想主要也是想提醒自己,学一项技术的时候多问为什么,这样知识学到手后不容易忘掉。
至于为什么说只能说是入门Redis,因为Redis的用法实在太多了,你可以把它当作缓存,也可以把它当成数据库,甚至能把它当作消息队列。缓存可能大家都很熟悉了,在当数据库的方面Redis简直是潜力无限,大家一定要善用它的bitmap位图功能,简直能在面对复杂需求的时候玩出花来。比如说老板要统计所有用户一年中的登录天数,一个用户只需要365bit(46B)的空间,相比于用传统的mysql不知道也节省多少倍的空间。
而且在学习Redis的过程中,我越来越感受到计算机基础的重要性。就拿一个经典问题来说吧:
Redis为什么这么快?
虽然说答出基于内存能拿个合格的分数。但是作为一个运行在操作系统之上的软件,你有没有考虑过它是通过什么方式从操作系统的网卡读回网络请求数据的呢?操作系统不断更新迭代的IO系统调用,为Redis的快提供了基本的保障,再加上它内置的简洁精巧的数据结构,让它成为了一款优秀的基于内存的数据结构存储系统。
说不定再过半年,伴随着知识和经验的累积,我会对Redis有更进一步的看法。努力学习,共勉!
作者:炭烧生蚝
原文链接:https://www.cnblogs.com/tanshaoshenghao/p/13063886.html
这篇关于学习Redis好一阵了,我对它有了一些新的看法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








