本文主要是介绍c语言解释器1-词法分析器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
c语言解释器1-词法分析器
- 词法分析概述
- 待分析的C语言子集的词法
- 词法分析算法
- c语言实现
- 运行示例
词法分析概述
依据语言构词规则,从输入的源程序(字符串)中识别出一个
个单词(符号)。
例如,给定如下输入:
position = initial + rate * 60
词法分析器将识别出7个单词符号
position, =, initial, +, rate, *, 60
待分析的C语言子集的词法
- 关键字

- 专用符号
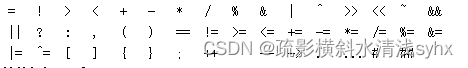
- 其他标记ID和NUM

- 空格由空白、制表符和换行符组成
空格一般用来分隔ID、NUM、专用符号和关键字,词法分析阶段通常被忽略。 - 注释
行注释 //…
块注释 /…/
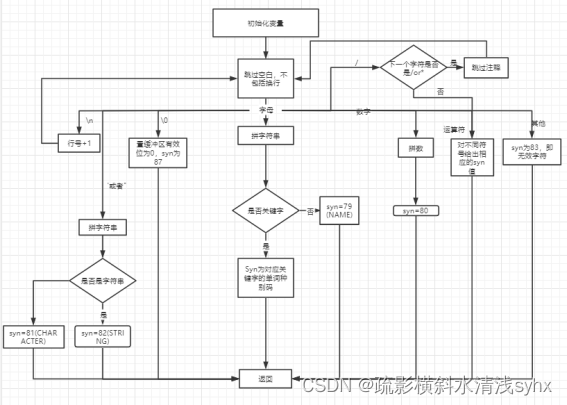
词法分析算法
c语言实现
clib.h
定义了一些用基础的数据结构。
#ifndef CLIB_H_INCLUDE
#define CLIB_H_INCLUDE
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
typedef struct c_reader c_reader; //
typedef struct c_buffer c_buffer; //缓存
typedef struct c_token c_token; //单词符号串结构体
typedef enum c_type c_type; //单词符号类型(即种别码)
typedef struct srouce_location location_t; //单词符号起始字符所在位置//c语言运算符
#define OP_TABLE \OP(EQ, "=") \OP(EQ_EQ, "==") \OP(NOT, "!") \OP(NOT_EQ, "!=") \OP(GREATER, ">") \OP(GREATER_EQ, ">=") \OP(LESS, "<") \OP(LESS_EQ, "<=") \OP(PLUS, "+") \OP(PLUS_EQ, "+=") \OP(PLUS_PLUS, "++") \OP(MINUS, "-") \OP(MINUS_EQ, "-=") \OP(MINUS_MINUS, "--") \OP(MULT, "*") \OP(MULT_EQ, "*=") \OP(DIV, "/") \OP(DIV_EQ, "/=") \OP(MOD, "%") \OP(MOD_EQ, "%=") \OP(AND, "&") \OP(AND_EQ, "&=") \OP(OR, "|") \OP(OR_EQ, "|=") \OP(XOR, "^") \OP(XOR_EQ, "^=") \OP(RSHIFT, ">>") \OP(RSHIFT_EQ, ">>=") \OP(LSHIFT, "<<") \OP(LSHIFT_EQ, "<<=") \OP(COMPL, "~") \OP(AND_AND, "&&") \OP(OR_OR, "||") \OP(QUERY, "?") \OP(COLON, ":") \OP(COMMA, ",") \OP(OPEN_PAREN, "(") \OP(CLOSE_PAREN, ")") \OP(OPEN_SQUARE, "[") \OP(CLOSE_SQUARE,"]") \OP(OPEN_BRACE, "{") \OP(CLOSE_BRACE, "}") \OP(SEMICOLON, ";") \OP(DEREF, "->") \OP(DOT, ".") \OP(DOT_DOT_DOT, "...") \OP(SHARP, "#") \OP(SHARP_SHARP, "##") //
#define TK_TABLE \TK(NAME, IDENT) \TK(NUMBER, LITERAL) \TK(CHARACTER, LITERAL) \TK(STRING, LITERAL) \TK(OTHER, LITERAL) \TK(HEADER_NAME, LITERAL) \TK(COMMENT, LITERAL) \TK(MACRO_ARG, NONE) //c语言关键字枚举
#define KW_TABLE \KW(STATIC, "static") \KW(UNSIGNED, "unsigned") \KW(LONG, "long") \KW(CONST, "const") \KW(EXTERN, "extern") \KW(REGISTER, "register") \KW(TYPEDEF, "typedef") \KW(SHORT, "short") \KW(INLINE, "inline") \KW(VOLATILE, "volatile") \KW(SIGNED, "signed") \KW(AUTO, "auto") \KW(INT, "int") \KW(CHAR, "char") \KW(FLOAT, "float") \KW(DOUBLE, "double") \KW(VOID, "void") \KW(ENUM, "enum") \KW(STRUCT, "struct") \KW(UNION, "union") \KW(IF, "if") \KW(ELSE, "else") \KW(WHILE, "while") \KW(DO, "do") \KW(FOR, "for") \KW(SWITCH, "switch") \KW(CASE, "case") \KW(DEFAULT, "default") \KW(BREAK, "break") \KW(CONTINUE, "continue") \KW(RETURN, "return") \KW(GOTO, "goto") \KW(SIZEOF, "sizeof") \KW(RESTRICT, "restrict") #define OP(e,s) C_ ## e,
#define TK(e,s) C_ ## e,
#define KW(e,s) C_ ## e,
//枚举单词符号串的种别码
enum c_type
{OP_TABLEKW_TABLETK_TABLEN_TYPES //No type
};
#undef KW
#undef OP
#undef TK#define KW(e,s) if(!strcmp(str,s)) return C_ ## e;
c_type is_keyword(const char *base,int size)
{char str[256];memcpy(str,base,size);str[size] = '\0';KW_TABLEreturn C_NAME;
}
#undef KW//单词符号的位置
struct srouce_location
{const char *file;int line;int column;
};//单词符号结构体
struct c_token
{location_t src_loc; //单词符号串的位置c_type type; //token type//A string or number or iden or charchar *val;
};//
struct c_buffer
{char *cur; //当前位置char *line_base; /*行起始位置 */char *buf; //字符串缓冲unsigned int line_number; //行号
};struct c_reader
{char *file; //文件名c_buffer *buffer; //the file bufferunsigned int vaild; //is buffer vaild,vaild=1,else vaild=0c_reader *prev; //预留,用以支持include预处理以及宏定义的预处理
};//读入一个c文件
#define xmalloc(T,size) (T *)malloc(sizeof(T)*(size))
#define xcalloc(type,size) (type *)calloc(sizeof(type),size)
c_reader *read_file(const char *file)
{FILE *fp = fopen(file,"rb");if(fp==NULL){return NULL;printf("NULL");}c_reader *cr = xmalloc(c_reader,1);cr->prev = NULL;cr->file = xmalloc(char,strlen(file)+1);strcpy(cr->file,file);int size = 8*1024;c_buffer *cb = xmalloc(c_buffer,1);char *buff = xcalloc(char,size+1);int fd = fread(buff,sizeof(char),size,fp);while(!feof(fp)){fseek(fp,0,SEEK_SET);size *= 2;buff = realloc(buff,size+1);fd = fread(buff,sizeof(char),size,fp);}buff[fd] = '\0';cb->buf = buff;cb->cur = buff;cb->line_base = buff;cb->line_number = 1;cr->buffer = cb;cr->vaild = 1;fclose(fp);return cr;
}#endif //CLIB_H_INCLUDE
lex.h
#ifndef _LEX_H
#define _LEX_H#include "clib.h"
#include <ctype.h>//用以简化代码
#define IF_ELSE(condition,one,other) \if(*cur == condition) {tk->type = one;cur++;} \else tk->type = other; \break;
#define IF_ELIF_ELSE(c1,one,c2,two,other) \if(*cur == c1) {tk->type = one;cur++;} \else IF_ELSE(c2,two,other)static c_token *lex_token(c_reader *pfile)
{c_token *tk = xmalloc(c_token,1); char *base, *cur = pfile->buffer->cur; //初始化base、cur指针,base为单词符号的起始位置,cur为当前字符所在位置//略过空白字符
start:while(isspace(*cur)&&(*cur!='\n'))++cur;base = cur;switch (*cur++) //移动cur指针{case '\0':pfile->vaild = 0;tk->type=N_TYPES;break;//行号处理case '\n':pfile->buffer->line_number++;pfile->buffer->line_base = cur;goto start; break;//处理id和关键字case '_':case 'a': case 'b': case 'c': case 'd': case 'e': case 'f': case 'g': case 'h': case 'i': case 'j': case 'k': case 'l': case 'm':case 'n': case 'o': case 'p': case 'q': case 'r': case 's': case 't': case 'u': case 'v': case 'w': case 'x': case 'y': case 'z': case 'A': case 'B': case 'C': case 'D': case 'E': case 'F': case 'G': case 'H': case 'I': case 'J': case 'K': case 'L': case 'M': case 'N': case 'O': case 'P': case 'Q': case 'R': case 'S': case 'T': case 'U': case 'V': case 'W': case 'X': case 'Y': case 'Z': while(isalnum(*cur)||*cur=='_')cur++;tk->type=is_keyword(base,cur-base);break;//处理数字,目前只支持整数处理case '0': case '1': case '2': case '3': case '4': case '5': case '6': case '7': case '8': case '9': while(isdigit(*cur))cur++;tk->type = C_NUMBER;break;//处理字符串及单字符case '\'': case '\"': while((*cur!=*base)&&(*cur!='\n')&&(*cur!='\0')) cur++;tk->type = (*(base) == '\'') ? C_CHARACTER:C_STRING;cur += (*base == *cur) ? 1:0;break;//跳过注释case '/': if(*cur == '/'){ while(*cur!='\n'&&*cur!='\0')++cur; goto start; } // 跳过单行注释else if(*cur == '*'){ cur++; // 跳过块注释while (!(*cur == '/' && cur[-1] == '*' || cur[0] == '\0')){if(*cur++ == '\n') {pfile->buffer->line_number++;pfile->buffer->line_base = cur;}}cur++; goto start;} else IF_ELSE('=',C_DIV_EQ,C_DIV)//专有符号处理case '-': if(*cur == '-'){tk->type = C_MINUS_MINUS;cur++;}else IF_ELIF_ELSE('>',C_DEREF,'=',C_MINUS_EQ,C_MINUS)case '=': IF_ELSE('=',C_EQ_EQ,C_EQ)case '!': IF_ELSE('=',C_NOT_EQ,C_NOT)case '^': IF_ELSE('=',C_XOR_EQ,C_XOR)case '*': IF_ELSE('=',C_MULT_EQ,C_MULT)case '%': IF_ELSE('=',C_MOD_EQ,C_MOD)case '#': IF_ELSE('#',C_SHARP_SHARP,C_SHARP)case '>': if(*cur == '>') {cur++;IF_ELSE('=',C_RSHIFT_EQ,C_RSHIFT)} else IF_ELSE('=',C_GREATER_EQ,C_GREATER)case '<': if(*cur == '<') {cur++;IF_ELSE('=',C_LSHIFT_EQ,C_LSHIFT)} else IF_ELSE('=',C_LESS_EQ,C_LESS)case '+': IF_ELIF_ELSE('+',C_PLUS_PLUS,'=',C_PLUS_EQ,C_PLUS)case '&': IF_ELIF_ELSE('&',C_AND_AND,'=',C_AND_EQ,C_AND)case '|': IF_ELIF_ELSE('|',C_OR_OR,'=',C_OR_EQ,C_OR)case '~': tk->type = C_COMPL;break;case '?': tk->type = C_QUERY;break;case ':': tk->type = C_COLON;break;case ',': tk->type = C_COMMA;break;case '(': tk->type = C_OPEN_PAREN;break;case ')': tk->type = C_CLOSE_PAREN;break;case '[': tk->type = C_OPEN_SQUARE;break;case ']': tk->type = C_CLOSE_SQUARE;break;case '{': tk->type = C_OPEN_BRACE;break;case '}': tk->type = C_CLOSE_BRACE;break;case ';': tk->type = C_SEMICOLON;break;case '.': tk->type = C_DOT;if(*cur=='.'&&cur[1]=='.'){tk->type=C_DOT_DOT_DOT;cur+=2;} break;default:tk->type = C_OTHER;break;}int size = cur - base; //此时cur指向单词符号串的尾部,base指向单词符号串的起始位置pfile->buffer->cur = cur; //记录处理到的位置tk->src_loc.line = pfile->buffer->line_number; //将行号信息记录到该单词tk->src_loc.column = base+1 - pfile->buffer->line_base; //将列号信息记录到该单词tk->src_loc.file = pfile->file; //将文件信息记录到该单词tk->val = xcalloc(char,size+1); memcpy(tk->val,base,size); //记录单词符号的值,即一个字符串// printf("%s\n",tk->val);return tk;
}
#endif //_LEX_H
scan.c
用以展示词法分析的结果
#include "lex.h"
#include <stdio.h>/*
* 原型:void scan(c_reader *pfile,FILE *out)
* 功能:从字符串表示的源程序中识别出具有独立意义的单词符号
* 参数:输入参数:pfile ---缓冲区
* 输出参数:out --- 输出文件
* 返回值:无
*/
void scan(c_reader *pfile,FILE *out)
{char *dest = xmalloc(char,64);fprintf(out,"(line ,column,offset):\t(c_type,token)\n");while(pfile->vaild){c_token *tk = lex_token(pfile);switch (tk->type){case N_TYPES:break; default:fprintf(out,"(%-6d,%-6d,%-6d):\t(%-2d,%s)\n",tk->src_loc.line,tk->src_loc.column,strlen(tk->val),tk->type,tk->val);break;}}
}int main(int argn,char **argv)
{FILE *fo;if(argn<2)return -1;if(argn<3){fo = stdout;}else{fo = fopen(argv[2],"w");}c_reader *cr = read_file(argv[1]);scan(cr,fo);fclose(fo);return 0;
}
运行示例
编译
gcc scan.c -o scan.exe
运行方式
//运行方式一
.\scan.exe test.c //结果将输出到屏幕
//运行方式二
.\scan.exe test.c abc.txt //结果将输出到abc.txt文件
测试源文件
#include <stdio.h>int main(int argn,char **argv)
{int a,*b;a += *b;*b = a << 2;return 0;
}
结果输出
(line ,column,offset): (c_type,token)
(1 ,1 ,1 ): (46,#)
(1 ,2 ,7 ): (82,include)
(1 ,10 ,1 ): (6 ,<)
(1 ,11 ,5 ): (82,stdio)
(1 ,16 ,1 ): (44,.)
(1 ,17 ,1 ): (82,h)
(1 ,18 ,1 ): (4 ,>)
(3 ,1 ,3 ): (60,int)
(3 ,5 ,4 ): (82,main)
(3 ,9 ,1 ): (36,()
(3 ,10 ,3 ): (60,int)
(3 ,14 ,4 ): (82,argn)
(3 ,18 ,1 ): (35,,)
(3 ,19 ,4 ): (61,char)
(3 ,24 ,1 ): (14,*)
(3 ,25 ,1 ): (14,*)
(3 ,26 ,4 ): (82,argv)
(3 ,30 ,1 ): (37,))
(4 ,1 ,1 ): (40,{)
(5 ,5 ,3 ): (60,int)
(5 ,9 ,1 ): (82,a)
(5 ,10 ,1 ): (35,,)
(5 ,11 ,1 ): (14,*)
(5 ,12 ,1 ): (82,b)
(5 ,13 ,1 ): (42,;)
(6 ,5 ,1 ): (82,a)
(6 ,7 ,2 ): (9 ,+=)
(6 ,10 ,1 ): (14,*)
(6 ,11 ,1 ): (82,b)
(6 ,12 ,1 ): (42,;)
(7 ,5 ,1 ): (14,*)
(7 ,6 ,1 ): (82,b)
(7 ,8 ,1 ): (0 ,=)
(7 ,10 ,1 ): (82,a)
(7 ,12 ,2 ): (28,<<)
(7 ,15 ,1 ): (83,2)
(7 ,16 ,1 ): (42,;)
(8 ,5 ,6 ): (78,return)
(8 ,12 ,1 ): (83,0)
(8 ,13 ,1 ): (42,;)
(9 ,1 ,1 ): (41,})这篇关于c语言解释器1-词法分析器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

