本文主要是介绍【更新】cyのMemo(20231231~),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
序言
最终,无事发生,我的跨年是在图书馆(因为我忘带卡打不开实验室门),和去年一样。其实我并不想去图书馆,但是觉得在床上跨年太颓废,找个好点的处所,至少说得过去些。人嘛,体面些,不磕碜。
我对2023年基本满意,至少比前两年要好很多,在经历越来越多事情后,对世间事物的运行规律更加清楚,对自己的未来更加明晰。大家都是资深成年人,跨不跨年又有何谓?正如我现在认为的那样,拼死拼活,爬到多高的位置,无非是换了个圈子,总有比你更强的人,如果给我重来的机会,或许本科毕业就找个活干。不如养生。
文章目录
- 序言
- 20231231
- 20240101
- 20240102~20240103
- 20240104
- 20230105
- 20240106
- 20240107~20240108
- 20240109
- 20240110
- 20240111
- 20240112
- 20240113
- 20240114
- 20240115
- 20240116
- 20240117
- 20240118
- 20240119
- 20240120
- 20240121
- 20240122
- 20240123
20231231
- 吃惊地发现SXY在31日凌晨两点多竟然在淮海中路云海大厦的一间酒吧,灯红酒绿。我不是对酒吧有何偏见,但是至少在我的印象里,SXY不像是那种会去酒吧到深夜的人,我不清楚为什么,但人或许总是会变。之前跟宝玺、剑仙一起吃饭时,宝玺问你们喝酒都是为了什么,剑仙说当然是精神解脱,我不以为然,因为我喝酒都是跟最好的朋友一起吃饭才会喝。或许酒的确是有那些用途的吧。
- 然而,LXY不仅没有感冒,而且生龙活虎地在31日清晨七点,去操场跑23.24km跨年(用时2:00:55,平均配速5’12"/km,汗颜),瞋目结舌。我知道她很猛,但没想到会这么猛。我自己最长也不曾跑过半马以上的距离,更不用说是在场地。而且31号早晨重度污染,好多跑团的活动都临时取消,真是早起的鸟儿有霾吸。我撺掇LXY一起报锡马,她要是能去,我们四五个兄弟绝对不追求成绩,主线任务就是破风带路。
- 旧岁到此结束,无论喜怒哀乐,相信新年将有无限可能。——To you all
df.apply的broadcast参数,布尔型的可选参数。当为None或False时,会返回一个与原dataframe的column或index长度相同的Series。 当为True时,会返回一个index和column跟原dataframe相同的dataframe(当然结果进行了广播)。
还有一个很重要的参数raw: 布尔型。默认为False。当为False时,会将dataframe中的每一个column或每一个index上以Series的形式传到函数中(这也是常规的做法,此时逻辑是循环,通常很慢)。当为True时,则会把数据以np.ndarray的形式传到函数中,如果这个时候func用的就是numpy的函数,则执行效率会非常高。
在0.23版本以后,这个参数会被替换成result_type='broadcast',可选值包括以下几种:expand、reduce、broardcast、None。确定返回形式。(0.23.0以后版本才有并且只有当axis=1时这个参数才能发挥作用)
此外,apply支持位置参数agrs,和关键词参数**kwds
另外,假定X是dataframe的一列,比如每行的数值是一个列表或者np.ndarray,可以使用np.array(X)是无法将它变成一个矩阵的,得用np.stack或者np.vstack才行。
20240101
- Happy New Year! Wish you all the best!
- 万能的LXY终于倒下,早上说膝盖崩了,问我疼没疼,说实话,不算去年4月初意外扭脚,我已经一年半腿脚没有疼痛过了,得益于前掌跑法和力量训练(我目前的看法,不以达二级运动员为目标的跑步训练,对身体一定是利大于弊,损伤可以忽略不计,前提是训练是科学的)。
- 我觉得现在这样也挺好,把LXY当作目标去追求,让自己能够做事更努力些,能不能追得到又有何所谓?今早打开微信想回消息时,才发现认识的这两年多,我竟只跟她单聊过三句话,第一句是默认的打招呼语句,第二句是2022年春节贺喜(我没有回复),第三句是2023年春节贺喜(我有回复),尴尬得不行,王凯再三嘱托我不要在群里聊,一定要单聊,但是你这让我怎么开得了口,唉,两年前刚认识的时候,我就知道她很NB,学习运动全能选手,所以早有自知之明,但是两年后我觉得自己似乎也可以,高低现在也能算个业余精英跑者,学习也勉强说得过去,就有些蠢蠢欲动了。
- 我总觉得,那些单身很久的人,必定会有很突出的性格缺陷,我自己在关键问题上缺乏主见,患得患失,常为小事焦虑。因此相处需要的是理解,而不是冲动。
- 下午场地万米,41’07"(平均心率167bpm)。似乎平常的例训,但前5000米我是穿着外套慢摇,脱了之后,后5000米用时19’50"(4’05"+4’05"+4’01"+3’57"+3’42"),顶了一波心肺强度(190bpm)。很满意的结果,至少我现在可以轻松地把5000米跑进20分,这就足够了。

df = df.loc[df["列名"].str.contains("需要筛选的字符串"),:]
如果字段df["列名"]存在缺失,此法会报错。
解决方案是:在筛选中加上"na=False",这意思是:遇到非字符串的情况,直接忽略。
df = df.loc[df["列名"].str.contains("需要筛选的字符串", na=False),:]
之前说df["列名"].map有一个参数na_action可以用来简便处理缺失:
>>> a = pd.DataFrame({"a": [np.nan, "1", "2"]})
>>> a["b"] = a["a"].map(int, na_action="ignore")
>>> a["b"]
0 NaN
1 1.0
2 2.0
这是ok的,但是比如有时候你需要筛选带有特定字符串的,NaN并不能作为False处理,还是得用最一开始提到的方法。
20240102~20240103
- 嘉伟昨晚居然一个人去听维也纳皇家乐团的跨年演出,竟然如此上流,认识这么久我都不知道。我一直觉得下半年嘉伟沉寂是因为失恋,我也有些事情想问他,所以就约了今晚一起训练。
- 很久没有这种感觉,一天听不到消息就会些许失落,但又不肯主动去cue,昨晚快12点时LXY才冒了泡。
- 昨晚回来去操场慢跑5000米(均配4’35"),追加20kg负重的30×8组箭步,最后冲了一个400米(1’15"),练完力量适合接一组爆发,最后放松拉伸,拉了会儿单杠,状态不错。
- 今晚按计划约嘉伟跑课表,6k+6k节奏跑,间隔3~4分钟,嘉伟带的3’50"左右的配速(我跟嘉伟实力悬殊,嘉伟目标是帮我顶到极限,但不可否认跑前我确实觉得自己状态很好),第一组顶到5000米力竭,用时19’30"(表漂了,距离不准),当时觉得不可能坚持完第二组,第二组开始时跟嘉伟说,估计要跑一圈停一圈,结果第二组一直坚持到5000米才停下,用时19’08",比第一组还要快,我自己都震惊了,状态好的离谱,如果是全盛状态下,我极有可能破开19分。4分配终于被我彻底跨过,可以更轻松地腾跃以扩大步幅,现在就算是3’50"的配速,跑起来也相当稳,这就是腿部力量与核心力量强大后立竿见影的效果。
- 练完我问嘉伟有没有接着谈的打算(主要一直觉得他和濛麓走的很近,他觉得濛麓很好,但听下来他似乎另有所思),我告诉他佩瑶已有新任,嘉伟很吃惊,我说新任就一棒子脸根本比不上你,她眼光真差,嘉伟估计是受刺激了,跟我分开后他居然又折道回操场干了3个1000米间歇,唉,人呐,这就是我不愿意再去触碰恋爱的原因。其实我是想顺着引出想追LXY的事,想听听嘉伟的看法,但是时间太短我没能说出口,但我觉得自己可能也真的说不出口,我不知道自己到底在想什么,自相矛盾,却又放弃不下,我觉得自己错过了一个又一个人,难道还要这样继续错过吗?我已经没有时间了。

pandas dataframe绘图参数
DataFrame.plot(x=None, y=None, kind='line', ax=None, subplots=False, sharex=None, sharey=False, layout=None, figsize=None, use_index=True, title=None, grid=None, legend=True, style=None, logx=False, logy=False, loglog=False, xticks=None, yticks=None, xlim=None, ylim=None, rot=None, fontsize=None, colormap=None, position=0.5, table=False, yerr=None, xerr=None, stacked=True/False, sort_columns=False, secondary_y=False, mark_right=True, **kwds)
x和y:表示标签或者位置,用来指定显示的索引,默认为None
kind:表示绘图的类型,默认为line,折线图
line:折线图
bar/barh:柱状图(条形图),纵向/横向
pie:饼状图
hist:直方图(数值频率分布)
box:箱型图
kde:密度图,主要对柱状图添加Kernel 概率密度线
area:区域图(面积图)
scatter:散点图
hexbin:蜂巢图
ax:子图,可以理解成第二坐标轴,默认None
subplots:是否对列分别作子图,默认False
sharex:共享x轴刻度、标签。如果ax为None,则默认为True,如果传入ax,则默认为False
sharey:共享y轴刻度、标签
layout:子图的行列布局,(rows, columns)
figsize:图形尺寸大小,(width, height)
use_index:用索引做x轴,默认True
title:图形的标题
grid:图形是否有网格,默认None
legend:子图的图例
style:对每列折线图设置线的类型,list or dict
logx:设置x轴刻度是否取对数,默认False
logy
loglog:同时设置x,y轴刻度是否取对数,默认False
xticks:设置x轴刻度值,序列形式(比如列表)
yticks
xlim:设置坐标轴的范围。数值,列表或元组(区间范围)
ylim
rot:轴标签(轴刻度)的显示旋转度数,默认None
fontsize : int, default None#设置轴刻度的字体大小
colormap:设置图的区域颜色
colorbar:柱子颜色
position:柱形图的对齐方式,取值范围[0,1],默认0.5(中间对齐)
table:图下添加表,默认False。若为True,则使用DataFrame中的数据绘制表格
yerr:误差线
xerr
stacked:是否堆积,在折线图和柱状图中默认为False,在区域图中默认为True
sort_columns:对列名称进行排序,默认为False
secondary_y:设置第二个y轴(右辅助y轴),默认为False
mark_right : 当使用secondary_y轴时,在图例中自动用“(right)”标记列标签 ,默认True
x_compat:适配x轴刻度显示,默认为False。设置True可优化时间刻度的显示
20240104
- 后来下班我在群里说今晚诚信慢跑,嘉伟考完最后一门要聚餐,AK要加班,宋某直接失联,我想着这周前三天都是大强度,四五可以放松跑。但我真实目的是想试探LXY来不来跑,但是等了会儿一直没有想要的答复,只好鼓起勇气去单聊约她出来,原来她下午已经打过球(看来膝盖是真的好了),她说明天可以,但是生理期,只能诚信慢跑,这就触及我的知识盲区了,为了让她信服我的诚信,今晚特地去跑了一个5’34"/km配速的6.66km(平均心率142bpm,说实话,这么慢的跑着真累),顺带打电话跟医生老妈请教了一下这个生理期的问题,老妈非常耐心地给我科普了一下常识,说我真是个睿智,生理期都不懂,白活这么大。
- 李乐康元旦去日本,为的是第100回箱根驿传,他到现场观战,人非常多。发了几张照片给我们看,热血沸腾,日本高校长跑精英的那种极致力量感,要知道中国的万米和半马国家记录放在日本这些前十的高校里,连它们参赛队伍的平均水平都比不上(人均万米28分台),这还只是他们的大学生,并非最顶尖的职业选手。今年青学(不是网球王子的青学)刷新大会新,以及5区的区间新被两次刷新(山神降临),10年7冠,重回王座,往路3个区间赏,1个区间新,也算是第100回箱根驿传之圆满,要知道复路的7区天降暴雨,极其恶劣的条件下都刷新大会记录,抛开民族情节不谈,小日本真的令人震撼。


Seaborn绘图记录:散点图
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid") #这是seaborn默认的风格#scatterplot参数
seaborn.scatterplot(x=None, y=None, hue=None, style=None, size=None,
data=None, palette=None, hue_order=None, hue_norm=None, sizes=None,
size_order=None, size_norm=None, markers=True, style_order=None,x_bins=None, y_bins=None, units=None, estimator=None, ci=95, n_boot=1000, alpha='auto', x_jitter=None, y_jitter=None, legend='brief', ax=None, **kwargs)
x,y:横纵轴数据
hue:具体用以做分类的列,如'event', 'day'
data:是你的数据集,可选;
style:绘图的风格,如'time', ''event'
size:绘图的大小,可以直接设置为'size'
palette:调色板,如可以设置为palette=["b", "r"]
markers:绘图的形状,如可以设置为['o', 'x'],其实就是点的形状
ci:允许的误差范围(空值误差的百分比,0-100之间),可为‘sd’,则采用标准差(默认95);
n_boot(int):计算置信区间要使用的迭代次数;
alpha:透明度;
x_jitter,y_jitter:设置点的抖动程度。
20230105
- 晚上按约定陪跑LXY,12.38km,1小时5分,均配5’18"。从头聊到尾(很难想象女生能这种配速跑这种距离,还是生理期,还特么能说话,我因为要克制住速度,跑到最后都僵硬了,累得不行),出于隐私考量,我就不写具体内容,因为以她的性格,真的可能只是无意地说出那些暗示性极强的话。我并没有流露太多信号,依然是站在普通朋友的立场上说话做事,因为我并没有真的下定决心,虽然我很想更进一步,最后在学校已经没有多少时间,想还能留下一段回忆。
- 跑完回实验室打了个电话给妈妈,想到经年种种,难以置信地,我竟然哭了出来。等我开始写这段话的时候,又觉得自己很幼稚得可笑。
- 都说爱的是一个,成家立业的又是另一个,但这并不意味着前者是没有意义的。我跑了4年步,被父辈祖辈质疑了4年,从当年体测1000米在及格线上挣扎的人,到如今万米破40分,5000米19分台(预计可破19分),勉强也算个业余精英,结识了一群志同道合的朋友和一两个能交心的挚友,前几天我在回翻自己之前的朋友圈,几乎全部都是跑步,尽管我第一个10km就跑到了49’50",那时觉得自己多么厉害,但现在看起来又多么弱小。坚持许多年做一件事情怎么会没有意义呢?这些年,它本身就是意义。
- 我不知道,我真的不知道,但我真的很想知道。罢了。
小技巧:发现函数的参数定义可以这样写:
def f(*a, b, c, d, **e):print(a)print(b)print(c)print(d)print(e)
f(1, 2, 3, b=1, c=2, d=3, e=123, f=342, h=324)
如果想禁用位参(即强制调用时必须注明名参的名字),可以这样写:
def g(*, a, b, c): ...
这样的情况调用函数g必须使用:g(a=1,b=2,c=3)的形式,如果写成g(1, 2, 3)则会抛出异常
TypeError: g() takes 0 positional arguments but 3 was given
20240106
- 早上AK五点半去世纪公园进行NIKE黑马训练营的训练,3’43"均配跑了20km,太可怕了,今早上海全境重霾,肉眼可见的污染。
- 下午按计划与嘉伟进行20km拉练(预定配速4分整),没想到嘉伟竟然6000米就不行了,很罕见(4分配对他来说就是很简单的有氧跑)。他下场后我顶到8000米,平均配速3’58",很吃力,感觉可以顶到10km,但绝对坚持不到20km。还好LXY过来(昨晚她是说要来凑个热闹),准备跟她摇完最后12km。
- 我本以为LXY昨晚跟我跑12km,而且是生理期,今天怎么也不至于还能跑这么多。结果今天跑的比昨天还猛,我4’57"的配速跑了10km,腿已经完全抬不动,她却依然游刃有余,最后几圈她看出我体力不支(确切地说,是腿力不支,心率都掉到135bpm了,体能是绝对够的,现在的短板是大腿力量),提出让她来跑外道,我跑内道,我一脸???,最后她又是一共跑了12km,均配5分整,真给我整不会了。
- 这两天跑的太多,约定明天就不跑了,下周再约。跑完拿两个垫子一起拉伸会儿,女生身体是真的很柔软,脸都能压到腿面上。离开后跟着走了一段,今天比昨晚走得长些(再往前应该就没有一起走过路)。年纪大了,不想像年轻人那样搞些幼稚俗气的操作,在这个互相试探的过程中逐渐摸索,但自己还是处于信息的劣势方,她问了我一些,包括我的恋爱史(我只是说自己是分手后才加入田径队),我也主动说了一些,我却似乎问得很少,该从何问起,如何问起,感觉上她很有可能到现在都没有过一次恋爱,这让我极其费解,可能就像胡哥跟我说的那样,女生太优秀就是这样吧。如果真是第一个吃螃蟹的人,我也怕被夹到舌头,唉。

关于tokenizer添加special_token的问题:
from transformers import BertConfig
from transformers import BertTokenizer
from transformers import BertModelmodel_name = "hfl/chinese-roberta-wwm-ext/"
model_dir = "models/pretrain_models/" + model_nameconfig = BertConfig.from_pretrained(model_dir)
model = BertForMaskedLM.from_pretrained(model_dir)
tokenizer = BertTokenizer.from_pretrained(model_dir)add_tokens = ["[desc]", "[title]"]
tokenizer.add_tokens(add_tokens) #返回一个数,表示加入的新词数量(2)special_tokens_dict = {'additional_special_tokens': add_token}. # add_special_tokens 传入是一个key为additional_special_tokens的dict
tokenizer.add_special_tokens(special_tokens_dict) # 效果与add_tokens等价model.resize_token_embeddings(len(tokenizer)) # 关键步骤,重新调整所有的向量数量,即vocab size
tokenizer.save_pretrained(model_dir) # 将当前tokenizer保存本地,实现保留增加[token]。
20240107~20240108
- 凯爹问我要SXY的wx,我有些不解,他说为了扩大社交圈,中金那边认识的人太少了,我觉得也没啥不方便的,只是已经一个多月没联系过。凯爹叮嘱我不要去联系SXY,我思来想去,他们搞行研的自己扯吧,我也不掺和啥了。我也吃不准SXY,保不齐她还在看我写的东西。
- 昨天去小姨家大补,七点到实验楼陪AK爬楼3组(1~15层,他干了10组,我因为前两日量太大,走路都累,休一日)。回实验室后突然觉得烦躁,因为一天没有听到LXY的消息,不平静,在日记本上划拉好久,暗示自己平复下来,拖到最后直到零点把论文投掉才离开。心真乱了,太差劲太差劲,这么多年一点长进都没有,还是这个老样子。
- 万幸没失眠(把自己逼到极限,就不会失眠),一觉醒来依然精力充沛,九点整打个早卡,本想晚上早些回去,可是下午下雨,LXY说七号楼11~23点停水,所以下午去健身房跑步顺带洗个澡窝宿舍里了,不过晚上回来操场也不开放,只是连食堂都不开是真难受。只得出去觅食,回来到实验楼负1层3000个跳绳+200个双摇,回去再补核心训练,群里大伙儿也没闲着(除了已经躺了半个月的宋某),雨天也有三位都在环校跑步。
- 真好,以前我们只是各自在跑,现在将这些水平尚可的人聚集起来(可惜女生太少,但苛求女生跑步确实很难),相互激励,这个冬天过去,整体实力一定会有进步,现在连zjc都能4’26"配速跑完16km,开春万米跑进42分应该问题不大。我现在对自己的目标是开春万米破39分,5000米破18分半(自以为是可以达到的,因为我现在比之前训练要科学规律得多)。一定要控制饮食,保证高质量睡眠,每年年后水平都是暴跌,今年难得有正当理由挨到除夕再回家,七天之后就可以返回上海,一定要把过年这个发福期扛过去,以最全盛的状态迎接上半年比赛。
余弦学习率(torch文档—余弦相似度衰减学习率,torch文档—余弦相似度衰减学习率):
转自:https://zhuanlan.zhihu.com/p/261134624
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
optimizer (Optimizer) – Wrapped optimizer.
T_max (int) – Maximum number of iterations.
eta_min (float) – Minimum learning rate. Default: 0.
last_epoch (int) – The index of last epoch. Default: -1.
verbose (bool) – If True, prints a message to stdout for each update. Default: False.
CosineAnnealingLR比较简单,只对其中的最关键的Tmax参数作一个说明,这个可以理解为余弦函数的半周期.如果max_epoch=50次,那么设置T_max=5则会让学习率余弦周期性变化5次.

max_opoch=50, T_max=5👆
20240109
- 为了和LXY更进一步,我让老妈把我三年前买的羽毛球拍寄过来(这当时买来想跟前任打的,结果一次没打苟在角落吃灰,如今物是人非)。晚上下班去取球拍,回来和LXY先约跑10km(今天有电灯泡,虽然是大一小朋友,但也使我没能说上几句话),跑完我提议让她教我打会儿羽毛球(我说公司明天有羽球社团的活动,说实话,我这句话99%都是真的,周三真的羽球社活动,但我并不去参加,虽然之前颜烨确实邀请过我),她没有拒绝,便一同前往羽毛球房练了会儿。
- 还好,我的羽球技术比想象得要稍好些,之前是真碰不到球,但这次打了两三回后反手基本上都能接到,但是正手真的拉胯,一直打到最后都很难连续接到两个正手,根本碰不到球,掌握不到要领。
- 后来分别后,我返回操场取水杯,嘉伟和AK刚下班回来练,我拦住嘉伟,赏了他一片苹果,并向他透露我想追LXY的事,嘉伟似乎早已了然,我知道瞒不过他,所以只告诉他一人(也是跑圈里我最信任的兄弟),让他帮我保守秘密,这样可以避免一些不必要的麻烦,最重要的是,让我不是孤军奋战,能多架僚机。
- 嘉伟告诉我,LXY前天刚拉了一个四人小群去打羽毛球(嘉伟、韬哥、古丽),我回想那天是周日,确实是约定不跑,这样看起来她最近也找不到人打球。但怎么说呢,今晚也有让我很失落的时段,人的心态每一秒都会发生变化,最忌急于求成,一定要沉住气,凡事缓图,太容易得到也难以学会珍惜,慢慢来吧,没有什么事会一帆风顺,一定一定平常心。
CosineAnnealingWarmRestarts
torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0, T_mult=1, eta_min=0, last_epoch=-1, verbose=False)
这个最主要的参数有两个:
T_0:学习率第一次回到初始值的epoch位置
T_mult:这个控制了学习率变化的速度
如果T_mult=1,则学习率在T_0,2T_0,3T_0,…,i*T_0,…处回到最大值(初始学习率)
5,10,15,20,25,…处回到最大值
如果T_mult>1,则学习率在T_0,(1+T_mult)T_0,(1+T_mult+T_mult**2)T_0,…,(1+T_mult+T_mult2+…+T_0i)*T0,处回到最大值
5,15,35,75,155,…处回到最大值

T_0=5, T_mult=1👆
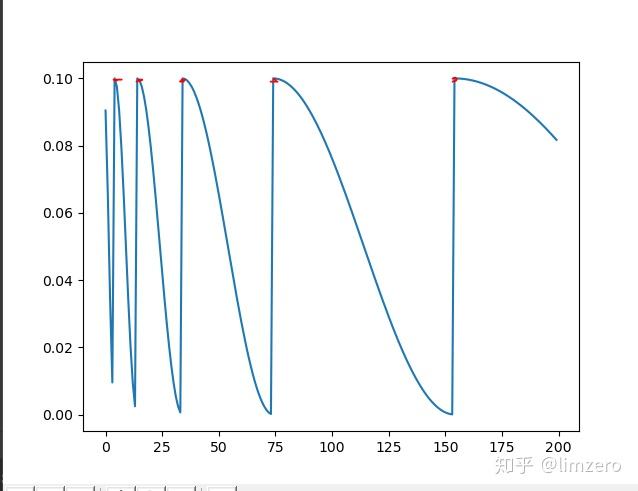
T_0=5, T_mult=2👆
所以可以看到,在调节参数的时候,一定要根据自己总的epoch合理的设置参数,不然很可能达不到预期的效果,经过我自己的试验发现,如果是用那种等间隔的退火策略(CosineAnnealingLR和Tmult=1的CosineAnnealingWarmRestarts),验证准确率总是会在学习率的最低点达到一个很好的效果,而随着学习率回升,验证精度会有所下降.所以为了能最终得到一个更好的收敛点,设置T_mult>1是很有必要的,这样到了训练后期,学习率不会再有一个回升的过程,而且一直下降直到训练结束。
20240110
- 早上不到七点,LXY又在群里摇人晚上跑(起的真早,昨天还在群里唠嗑到11点半之后),我知道晚上很冷,希望她下午有太阳时去跑,会舒服些。不是我不想晚上回来陪她跑,也不是想偷懒(周三本来是就是跟嘉伟跑课表),而是,一来我觉得没必要每天跑10km,这太伤身,何况女生(当然今天跑完我觉得她可能真的是身体比我还好,这话我收回),二来就是没必要每天都见面,因为总有一天会见不到的,浇些冷水对我是好事,得到时有多欣喜,失去后就有多失落,何况八字还没一撇,根本就未开始。
- 后来晚上我下地铁给LXY发消息,外面真的很冷,没必要勉强出来跑,但她坚持要跑,还要拉上古丽,我说人家必不可能出来,没人会跟你一样发神经(这么冷的天跑步不是发神经?),最后古丽确实没来,当然我也不希望她来。
- 所以今晚跑得很舒服,一来跑得很慢,5’37"配速的10.65km,也没电灯泡,可以轻松聊天,我连风衣都没脱,聊了学校很多过去的事情(作为这个学校的老住客,很怀念过去的生活),各自导师派的烂活,以及最近有趣的事,不涉及敏感话题,说起来就很轻松。她下周四就要回家,回家之前要先跟同学出去玩两天,我说你去哪儿玩,她说去合肥,我说去合肥也能叫出去玩嘛,就像我去南京,那不就串个门,好像没出省,但又好像出了省,所以我很少去南京。
- 跑完拉伸,前两天没拉伸搞得我小腿胀,今天拉完一下子好多了。一起走到七号楼分别,LXY问我明天还跑吗,我说你来我就来,她说那就老时间。
- 那就一起呗,趁你还在学校,一周时间,我也不知道会发生些什么。这辈子最错误的事,就是在2021年5月1日丧失理智,Bad End,乃至消沉数月,而最正确的事,是在2021年10月2日加入田径队,收获如此多朋友,以及交心的挚友,我不知道还能否收获学生时代尾声上的伴侣,但是无论成败,或许那天我只是心血来潮,但如今回看,一切又是那么命中注定。
所以可以看到,在调节参数的时候,一定要根据自己总的epoch合理的设置参数,不然很可能达不到预期的效果,经过我自己的试验发现,如果是用那种等间隔的退火策略(CosineAnnealingLR和Tmult=1的CosineAnnealingWarmRestarts),验证准确率总是会在学习率的最低点达到一个很好的效果,而随着学习率回升,验证精度会有所下降.所以为了能最终得到一个更好的收敛点,设置T_mult>1是很有必要的,这样到了训练后期,学习率不会再有一个回升的过程,而且一直下降直到训练结束。
import torch
from torch.optim.lr_scheduler import CosineAnnealingLR,CosineAnnealingWarmRestarts,StepLR
import torch.nn as nn
from torchvision.models import resnet18
import matplotlib.pyplot as plt
#
model=resnet18(pretrained=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
mode='cosineAnnWarm'
if mode=='cosineAnn':scheduler = CosineAnnealingLR(optimizer, T_max=5, eta_min=0)
elif mode=='cosineAnnWarm':scheduler = CosineAnnealingWarmRestarts(optimizer,T_0=5,T_mult=1)'''以T_0=5, T_mult=1为例:T_0:学习率第一次回到初始值的epoch位置.T_mult:这个控制了学习率回升的速度- 如果T_mult=1,则学习率在T_0,2*T_0,3*T_0,....,i*T_0,....处回到最大值(初始学习率)- 5,10,15,20,25,.......处回到最大值- 如果T_mult>1,则学习率在T_0,(1+T_mult)*T_0,(1+T_mult+T_mult**2)*T_0,.....,(1+T_mult+T_mult**2+...+T_0**i)*T0,处回到最大值- 5,15,35,75,155,.......处回到最大值example:T_0=5, T_mult=1'''
plt.figure()
max_epoch=50
iters=200
cur_lr_list = []
for epoch in range(max_epoch):for batch in range(iters):'''这里scheduler.step(epoch + batch / iters)的理解如下,如果是一个epoch结束后再.step那么一个epoch内所有batch使用的都是同一个学习率,为了使得不同batch也使用不同的学习率则可以在这里进行.step'''#scheduler.step(epoch + batch / iters)optimizer.step()scheduler.step()cur_lr=optimizer.param_groups[-1]['lr']cur_lr_list.append(cur_lr)print('cur_lr:',cur_lr)
x_list = list(range(len(cur_lr_list)))
plt.plot(x_list, cur_lr_list)
plt.show()
最后,对scheduler.step(epoch + batch / iters)的一个说明,这里的个人理解:一个epoch结束后再.step, 那么一个epoch内所有batch使用的都是同一个学习率,为了使得不同batch也使用不同的学习率 ,则可以在这里进行.step(将离散连续化,或者说使得采样得更加的密集),下图是以20个epoch,每个epoch5个batch,T0=2,Tmul=2画的学习率变化图
20240111
- 昨晚LXY在群里口无遮拦(我跟胡哥说我这个冬天跑得多些是因为今年想干个全马,她回复我满足你,直到下周四我回家,天天缠着你10k),虽然她行事作风一向不把自己当女生,但是落在我身上还是很胃疼(在我和她圈子的交集里,除AK我是没有竞争对手的,但AK是95年的,又是云南人,而且AK的圈子可太大了,我觉得不太可能;她也一样,除非她觉得婷玉姐是对手,但LTY那段位我根本不敢碰,但更多的可能是她仅仅想找个人跑步而已),她前脚在群里说完,住隔壁的胡哥就跟我说,这不得和妹子有点情况,还跑啥锡马,找个半马带她冲啊!我本想瞒着,但是毕竟男人太懂男人,何况还是扬州老乡,当面我也扯不下脸撒谎,只能实话实说。
- 胡哥说他一眼就看出我想追LXY,说我表现得太明显,最早最早听我提到LXY时就感觉到了(说实话,那时只是仰慕,并没有想过追),当时刚过零点,我也要睡了,不想深夜跟胡哥掰扯太久,想等下次有机会再细说。
- 我依然没有十足的把握,但我还是决定抽时间写封情书,虽然很俗套,但我喜欢这么做,讲道理我们这个年纪,说喜欢二字多少显得有些幼稚,但能怎么办呢?除此以外我也不知道该说些啥。如果要出手,就只有这个周末,因为下周四LXY就要回家,错过就要等到年后,我怕的不是夜长梦多(她能母胎solo到现在,就能solo得更久),而是她若无意,毕竟跟她交集的圈子里有这么多人在看着,虽然现在已知的只有嘉伟和胡哥知道,我怕自己再也混不下去了。
- 后来晚上下班,LXY跟我说被导师薅去干活,但这是好事,最近一周几乎每天的活动消耗都到了1000卡以上,腿真有些受不了,而且浇点冷水也好。回来之后到底还是有些失落,想找人陪我去练羽毛球,问了胡哥、安迪、嘉伟、宋某都不方便,悻悻然去羽毛球馆拦了两个男的折磨,第一个我特意给他先送了瓶果汁,防止他嫌我菜,还是陪我打了好久,第二个觉得我实在太菜,打了四五个就走了,太真实了。看到大家都打的那么上手,我一个人去馆后的空排球场,对着视频教程练接球,练发球。我一定要把羽毛球练好[苦涩]。
- 我想着下学期能白天陪她打打球多好,唉,我根本就是个体育白痴,身体协调性从小就差,运动会永远的观众,广播体操天天被老师留下来纠正,只有从2020年初开始跑步,靠日复一日的碰壁、反省、改进,花了整整四年才达到如今的水平,我以为自己能做到一切,但我已经没有时间了。
torch自定义反向传播:https://zhuanlan.zhihu.com/p/359524837
我们实现一个 a + b a+b a+b的tensor求和cuda算子,于是我们可以利用它来实现 L = a 2 + b 2 \mathcal{L}=a^2+b^2 L=a2+b2,最终训练收敛后 a a a和 b b b都会趋近于 0 0 0,模型没有输入,只有两个可训练的参数 a a a和 b b b。
功能是搭建了一个PyTorch模型,并且调用了自定义的cuda算子,实现了自定义的反向传播函数,最终完成训练。
首先定义模型
class AddModel(nn.Module):def __init__(self, n):super(AddModel, self).__init__()# tensor长度self.n = n# 定义可训练参数a和bself.a = nn.Parameter(torch.Tensor(self.n))self.b = nn.Parameter(torch.Tensor(self.n))# 正态分布初始化参数a和bself.a.data.normal_(mean=0.0, std=1.0)self.b.data.normal_(mean=0.0, std=1.0)def forward(self):# 求a^2与b^2a2 = torch.square(self.a)b2 = torch.square(self.b)# 调用自定义cuda算子对两个平方数求和c = AddModelFunction.apply(a2, b2, self.n)return c
20240112
- 六点醒来,失眠,是近几个月来第一次失眠。昨晚10.55离开实验室时,给LXY发消息,直到我睡下都没收到回复,我突然有些担心,因为不至于这么早睡觉,也不至于在导师家忙到通宵,害怕是否在路上出事。我醒来就看到她六点回复的消息,虚惊一场。
- 昨晚回三门路,还是把情书写完(现在字写得勉强还说得过去),不管用得到用不到,先备在身上。结果LXY早上继续约我晚上七点跑,而且她一大早环校跑5km,把昨天的量补了,是真的恐怖。
- 后来我想到她很喜欢吃栗子,我五点溜出去买了一袋,发现路边摊的真不行,糖炒栗子竟然不够甜,还是上美团又点了一份,把情书直接塞进去。我决心不当懦夫,懦夫了这么多年,必须莽一回,炸就炸了,今晚就出手,不折磨自己了。
- 大约是搞砸了吧…[哭泣]
星雨:已识二年有余 却似如初见两年前 你是完全陌生
一年前 你是令我仰慕
而如今 你是无法言说其实我很孤僻 囚生 笼中鸟 八年未改
直至进队许久 与人熟络 方豁然开朗我知晓 在此年岁 枉言喜欢 难免些许幼稚然 慢热如我 八年财大 繁花落尽
直至与我一同走过的 都一一离去我不愿再错过 写下此页 谨表吾意阳
20240113
- 今天下午约了嘉伟进行1600米×6的间歇,预定配速是340,结果嘉伟第一组冲到330,第一组即力竭,最后我一共跑了3组1600米和3组1000米,间歇4分钟,其中第5组1000米顶到3’23",估计现在体测1000米的是能跑到满分线3’15"的。
- 昨晚之后一直没有消息,其实我并不急,感觉还是做得太草率了,每次都是这样,后知后觉,莽起来没脑子,怂起来没血性。后来在实验室跟朋友扯到快12点才走,朋友跟我扯了半天倒是让我轻松了许多,我知道昨晚不会有结果,我估计LXY应该会今天过来给我当面审判,死猪不怕开水烫,回去洗洗早睡了。
- 结果还是太尴尬,下午跑完一起去吃了饭,回来路上还是没有说出口,我估计她也没有准备好,到最后还是在版聊解决问题(srds,我算是被发了张好人卡吧…),女生总是要更理智一些(虽然算半个工科男,但我感觉自己很多时候是很感性的),脑袋一拍就容易草率。但今天唯一的遗憾,是按道理周六我要去蜀地源大吃一顿,结果只是跟吃了碗牛肉刀削,没过瘾,但也吃不下更多了,罢了,就当这周省个饭钱呗。
- 结局:normal end,无事发生,这样也挺好,谈恋爱确实很累,彼此都轻松些也是好的,正如12月9日那天的想法,多个朋友总是比多个npy好。
实现自定义cuda算子前向和反向传播
下面就是如何实现AddModelFunction.apply()函数了,我们先来看一下具体代码:
class AddModelFunction(Function):@staticmethoddef forward(ctx, a, b, n):c = torch.empty(n).to(device="cuda:0")if args.compiler == 'jit':cuda_module.torch_launch_add2(c, a, b, n)elif args.compiler == 'setup':add2.torch_launch_add2(c, a, b, n)elif args.compiler == 'cmake':torch.ops.add2.torch_launch_add2(c, a, b, n)else:raise Exception("Type of cuda compiler must be one of jit/setup/cmake.")return c@staticmethoddef backward(ctx, grad_output):return (grad_output, grad_output, None)
这个类继承的是torch.autograd.Function类,我们可以用它来实现一下无法自动求导的操作,比如arxmax这种不可导的函数。
20240114
- 中午找嘉伟陪我练球,免费陪练,还不嫌我菜。嘉伟先花20分钟喂我正手发高远球,我连续六七次碰不到,嘉伟没疯我都快疯了。后来发现,得有个参照物,把左手举起来瞄准球,就能比较好的正手打中,虽笨但管用;然后发现反手又碰不到球,又花20分钟喂我反手。太稳了,每周末找练一次,争取速成。
- 晚上跟LXY跑完10k,浓雾加大风,现在我竟然觉得一天一个10k是很普通的事,有人一起确实轻松许多,可惜这样的好日子无多。消耗很大,所以我还是出去把昨晚没吃的蜀地源补了,468g肉+370g菜,外加2碗饭,再一瓶可乐,每周一次放纵,反正吃不胖,就硬造。
- 很纠结,我有些后悔让更多人知道这个地方。以前也有这种情况,那时我会选择不写,但是过一段时间又憋得慌。我本意是在清净之处留下些活过的痕迹,但后来发现这也是一种很重要的潜在沟通渠道,但是不再想让更多的人知道此处。
- 我越来越觉得自己最近一段时间变了许多,变成自己以前讨厌的样子,对如今的行事风格很陌生,但又不想再变回去,唉。
把之前积累的7000多条GPT4响应的HotpotQA多跳问题的回答过了一遍,还是有明显错误的结果。
但是我发现有明显的问题答案给错了,比如5a879ba55542993e715abfc3,5ae1f596554299234fd04372,而且这种都是典型的错误,即打标注的人被混淆了,比如后者:
context:"2008 Summer Olympics": "The 2008 Summer Olympic Games, officially known as the Games of the XXIX Olympiad () and commonly known as Beijing 2008, was a major international multi-sport event that took place in Beijing, China, from 7 to 24 August 2008.A total of 10,942 athletes from 204 National Olympic Committees (NOCs) competed in 28 sports and 302 events (a total of one event more than the schedule of the 2004 Games).China became the 22nd nation to host the Olympic Games and the 18th to hold a Summer Olympic Games.\n It was the third time that the Summer Olympic Games were held in East Asia and Asia, after Tokyo, Japan, in 1964 and Seoul, South Korea, in 1988.","Summer Olympic Games": "The Summer Olympic Games (French: \"Jeux olympiques d'\u00e9t\u00e9\" ) or the Games of the Olympiad, first held in 1896, is an international multi-sport event that is hosted by a different city every four years.The most recent Olympics were held in Rio de Janeiro, Brazil.The International Olympic Committee organizes the games and oversees the host city's preparations.In each Olympic event, gold medals are awarded for first place, silver medals are awarded for second place, and bronze medals are awarded for third; this tradition began in 1904.The Winter Olympic Games were created due to the success of the Summer Olympics.",question: When did the game which held three times in in East Asia first held label: 1896
gpt4: The game which held three times in East Asia was first held in 1964.
cot: The context mentions that the 2008 Summer Olympics was the third time the Summer Olympic Games were held in East Asia and Asia, after Tokyo in 1964 and Seoul in 1988. Therefore, the first instance of the game being held in East Asia was in Tokyo, 1964.
这个明显就是标签打错了,大模型的结果和论据都是完全正确的。
就目前来看,几乎可以认为gpt4的输出结果就是黄金标准,看下来hotpot还是太脏了,这是dev集上的案例,检查发现gpt4至少有5%的结果和给的答案不匹配,但这里面绝大多数都是答案本身有问题。
另一个问题就是hotpot几乎是强制的extractive形式的回答,这个并不好,因为很多时候答案未必是可以抽出来的。23年ACL还有人在做同时输出答案和推理过程(还只是很简单的推理过程,即论据发现)的工作,之前肯定是有人做过的,所以如果真的能做出输出cot的小型生成模型,一定是巨大的创新。‘
20240115
- 算了,该写啥写啥,我不能因为有人可能会看,就刻意改变自己的内容。
- 晚上状态很好,因为今天慧悦不在,中午实打实地睡了一个小时,我有点想一个人好好练会儿,最近几乎全是慢跑,量比以前多,但强度太低。后来还是被LXY叫去一起跑了会儿,我当然很高兴,只是担心她是照顾我的情绪所以叫我一起跑,其实没啥必要,想打球就去打呗,每个人都应该有自己隐私的空间,何况现在也并没有所谓约束。
- 她俩走后,我自己冲了5圈4分配,回实验室后,还是决定不去羽毛球馆了,一来实在没必要给自己找不自在,眼不见心不烦,二来在实验室吹空调不香嘛,非要出去挨冻。本来我是真想跟DGL菜鸡互啄一下,毕竟能找个水平相当的对手不容易(不过实际情况很有可能是我比DGL还要菜…),最后还是打消了这个念头,以前总给自己找不自在,现在多一事不如少一事,明智些,少做无意义的事,好好跟嘉伟把球练起来就完了。
- 看到WXY新发的pyq,总觉得他是消沉许久,近期又幸福了起来。多年不见,依然很羡慕他这样干净清澈的眼神。
- 明天我亲爱的宋某终于回来,已有20多天没见,还以为年前再不能一睹芳容,但是,作为见面礼,我要趁他初愈,好好拿捏一下,以后不一定有机会[奸笑]。
https://zhuanlan.zhihu.com/p/666671956
LinearFunction反向传播源码详解
class LinearFunction(torch.autograd.Function):@staticmethoddef forward(ctx, input: Tensor, weight: Tensor, bias: Tensor) -> Tensor:# input -- [B, M] weight -- [N, M] bias -- [N]output = input @ weight.T + bias[None, ...]ctx.save_for_backward(input, weight)return output # [B, N]@staticmethoddef backward(ctx, grad_output: Tensor) -> Tuple[Tensor, Tensor, Tensor]:# grad_output -- [B, N]input, weight = ctx.saved_tensorsgrad_input = grad_output @ weightgrad_weight = grad_output.T @ inputgrad_bias = grad_output.sum(0)return grad_input, grad_weight, grad_bias# 对LinearFunction进行封装
class MyLinear(torch.nn.Module):def __init__(self, in_features: int, out_features: int, dtype: torch.dtype) -> None:super().__init__()self.in_features = in_featuresself.out_features = out_featuresself.weight = torch.nn.Parameter(torch.empty((out_features, in_features), dtype=dtype))self.bias = torch.nn.Parameter(torch.empty((out_features,), dtype=dtype))self.reset_parameters()def reset_parameters(self) -> None:torch.nn.init.uniform_(self.weight)torch.nn.init.uniform_(self.bias)def forward(self, input: Tensor) -> Tensor:return LinearFunction.apply(input, self.weight, self.bias) # 在此处使用
- LinearFunction需要继承自torch.autograd.Function,并且需要实现forward和backward两个静态方法,注意是静态方法!
- forward输入的第一个参数都是ctx,后跟前向传播所需要的一个或多个输入,可以是任意类型的参数。输出也可以是一个或多个的任意类型结果。
- backward的输入输出类型的要求也和forward一样,但是数量是和forward有对应关系的,不能随便想怎么写就怎么写。上面代码中,backward的输入grad_output,对应了forward的输出output的梯度;输出grad_input, grad_weight, grad_bias则分别对应了forward的输入input、weight、bias的梯度。这很容易理解,因为是在做链式求导,LinearFunction是这条链上的某个节点,输入输出的数量和含义刚好相反且对应。
- ctx就是在此处只承担的一个功能(当然还可以有其他功能,详见官方文档),通过ctx.save_for_backward在forward中保存下来backward需要的变量,然后通过ctx.saved_tensors在backward中提取出这些变量。
- LinearFunction的使用不是直接调用forward,backward,而是调用LinearFunction.apply(input, weight, bias)。推荐如以上代码所示,封装进torch.nn.Module的子类。
20240116
- 到胃的一晚,3k@3’54" + 5k@5’00" + 4k@3’55" + 30个×8组箭步(20kg负重),其实不算累,感觉上休息得很好,但今天回来身体电量只剩33,最后的力量做得还是很极限,虽然又被宋某鸽,也算是很尽兴。最近强度一直不够,接下来又要连日下雨,趁着这两天天气好,赶紧把强度堆点儿起来。
- 中间5k是在陪胡哥慢跑,按约,把最近的事说了些,胡哥也谈了自己的经历,听来也是一番波折。胡哥毕竟长我两岁,都是以结婚为目的去谈,而我潜意识里可能没有那么强的目的性,尤其是在经历过一次之后,一谈就成几乎是童话中的桥段,但别人或许并不这么想。
- 也罢,顺其自然。昨晚跟老妈长聊一个小时,向她详细介绍了我圈子里几个重要的朋友,以及我自己对当下和未来的看法,能感觉到老妈很欣慰。但我却对一些问题愈发困惑,周五约了许久不见的老友吃饭,我想听些不同的答案。
我最近发现了一个非常奇怪的BUG,我先把案例放出来,因为我也不知道怎么解释这个问题:
比如你在外部写一个文件temp.txt,里面只写一行内容:
{1: np.nan}
然后你用下面这段代码去读它:
import pandas as pddf = pd.read_csv("temp.txt", sep='\t', header=None)df.columns = ["col_1"]print(type(df["col_1"][0]))df["col_1"] = df["col_1"].map(eval) # 不报错
df["col_1"] = df["col_1"].map(lambda x: eval(x)) # 会报错print(df["col_1"][0][1] == df["col_1"][0][1])
即直接使用df["col_1"] = df["col_1"].map(eval)是不报错的(注意,我没有import numpy as np,所以第二个df["col_1"] = df["col_1"].map(lambda x: eval(x))就报错了,但第一个就不报错)
我现在无法解释这两种写法的区别是什么,但是这个情况实在是太奇怪了。如果我把temp.txt里的内容改为
{1: numpy.nan}
则两种写法都报错(前提是不import numpy),如果有人知道原理是什么,请务必告诉我。
20240117
- 最后还是把3.31芜湖马拉松(10km组)报上了,一来万一扬马跳票,给自己多留个选择,虽然很想那天回家把主场半马刷个好成绩,尤其是去年扭伤硬扛了2个多小时才走完全程,很感人但更丢人;二来或许到3月底这段时间还会发生些什么呢,尽管大老远出省跑个10km性价比有些低,但到时候要是想去却去不了可多难受。
- 这两天不知道为什么很累,作息几乎没有变化,可能是破事多了些,下班身体电量都只剩35(过往都能有50上下),今晚也是陪安迪热身时就觉得身体很沉重,但是预定是要跑间歇(力量训练后,适合间歇将力量释放出来,这是东哥说的,我觉得很有道理),临时改为变速12×(400米@1’30"+400米@2’30")。
- 第一组跑慢,后面拉了点起来,基本上快圈都在1’24"以内,这个区间很舒适,反正顶完400米就能很舒服地慢慢颠,痛苦不会持续很久(想想周末1600米间歇是真的痛苦,明明1圈就不行了,还要再硬顶3圈),但成功干爆了宋某和安迪,安迪跟了10组,宋某跟了不到4组就吐了,回首不堪往事,真有被爽到。
- 跟宋某聊了些,总是需要摸索生活交集的均衡点,每个人都有自己生活,没有必要非得硬融进去,但又很难忍住完全不过问。反正明早LXY回家玩儿了,解脱,万事年后再说。翻日历发现竟然还有三周才过年,特么现在就不想上班了,好难好难坚持这种生活和训练强度,尤其时年关将近,太容易松懈,一定要把冬训坚持下来。
关于df.stack和df.unstack重提,每次都分不清,想用都要回头查:
这个问题只要记住下面这一个例子就完事了:
df = pd.DataFrame({"index_1": ["a", "a", "a", "b", "b", "b"],"index_2": ["score_1", "score_2", "score_3", "score_1", "score_2", "score_3"],"count": [1, 2, 3, 4, 5, 6],"percent": [.1, .2, .3, .4, .5, .6]
})df = df.set_index(["index_1", "index_2"])"""count percent
index_1 index_2
a score_1 1 0.1score_2 2 0.2score_3 3 0.3
b score_1 4 0.4score_2 5 0.5score_3 6 0.6
"""stack的操作会让索引多一级,一般来说我们不会搞这种操作,因为多重索引不是我们想要的,上面构造的是一个二级索引表,所以一般的操作是通过unstack把它变成一级索引的形式,这样更好看一些:
df.unstack()"""count percent
index_2 score_1 score_2 score_3 score_1 score_2 score_3
index_1
a 1 2 3 0.1 0.2 0.3
b 4 5 6 0.4 0.5 0.6
"""
这里会有个衍生的小问题,就是上面这个结果其实是带多级表头的,多级索引很多好办,直接reset_index(level=None, drop=False)这样就能一级一级的拆出来,而多级表头比较麻烦,不能很好地拆出来,但我们可以:
import pandas as pd# 创建包含多级表头的DataFrame
data = {'A': [1, 2], 'B': [3, 4]}
index = ['Group A', 'Group B']
columns = pd.MultiIndex.from_tuples([('Header 1', 'Subheader 1'), ('Header 1', 'Subheader 2')])
df = pd.DataFrame(data=data, index=index, columns=columns)
print("原始DataFrame:\n", df)# 获取第一级表头的值
first_level_headers = df.columns.get_level_values(0).tolist()
print("\n第一级表头的值:\n", first_level_headers)# 获取第二级表头的值
second_level_headers = df.columns.get_level_values(1).tolist()
print("\n第二级表头的值:\n", second_level_headers)
来获取每个层级地值,但的确不太好把它们拆出来,除非是用df.T把索引和表头交换,然后reset_index,感觉很笨。
20240118
《癸卯年腊八 · 人去冬雨至》
广厦寰宇水濛濛,扁舟一叶探萍踪。
腊香不掩凭阑意,青衫湿处别恨浓。
一梦一醒一夜终,一叹一咏一枯荣。
待至三月花开日,归燕南飞喜相逢。
- 冬雨初至,人未至,两周寒潮,不是很能提起兴致,各种意义上日子都挺难过。差不多有一年没有写过诗,现在性情变太多,说实话很讨厌现在的自己,但不想也再不能改得回去了。
- 晚上回来先跟DGL打了40分钟羽毛球,很舒服,突出一个菜鸡互啄,但她还要比我强一点点,但只要别阴我,打个十几个来回还是可行的(现在反手高远球也能比较好的打上了),但是被一个不到一米六的小姑娘打得四方乱跑,实在是丢人…
- 打完很高兴,羽球就是要手感,多打就能上手,回去要跟AK爬楼,结果乐极生悲,手机一摔,屏幕失灵,只得冒雨赶去五角场万达华为店(没有地图还绕了些路,好在凭靠第六感找到店),结果这儿也没维修部,重买了部新的(本来旧机也用了三四年,不心疼)。老妈说你爹年会刚中个奖,就给你败家败掉了,特么用的又不是你的钱,真的是。
一个ECHART画计图的demo,宝玺姐是真麻烦,既要又要,跟甲方提要求画一个正方形的圆一样。本子就那么大,还想画得又复杂又好看,受不了了。
<!DOCTYPE html>
<html>
<head><title>ECharts 关系图</title><script src="http://cdn.bootcss.com/jquery/1.11.2/jquery.min.js"></script><!-- use from online--><script src="https://cdn.bootcss.com/echarts/4.1.0.rc2/echarts.js"></script><!-- use from local--><script src="/static/js/echarts.min.js"></script>
</head><body>
<div id="main" style="width:1000px;height:800px"></div>
<script type="text/javascript">var myChart = echarts.init(document.getElementById('main'));var categories = [];for (var i = 0; i < 2; i++) {categories[i] = {name: '类目' + i};}option = {title: {text: 'ECharts 关系图'}, // 图的标题tooltip: {formatter: function (x) { return x.data.des;}},// 提示框的配置toolbox: {show: true,feature: {mark: {show: true},restore: {show: true},saveAsImage: {show: true} // 保存为图片}}, // 工具箱legend: [{// selectedMode: 'single',data: categories.map(function (a) {return a.name;})}],series: [{type: 'graph', // 类型:关系图layout: 'force', //图的布局,类型为力导图symbolSize: 40, // 调整节点的大小roam: true, // 是否开启鼠标缩放和平移漫游。默认不开启。如果只想要开启缩放或者平移,可以设置成 'scale' 或者 'move'。设置成 true 为都开启edgeSymbol: ['circle', 'arrow'],edgeSymbolSize: [2, 10],edgeLabel: {normal: {textStyle: {fontSize: 20}}},force: {repulsion: 2500,edgeLength: [10, 50]},draggable: true,lineStyle: {normal: {width: 2, color: '#4b565b'}},edgeLabel: {normal: {show: true,formatter: function (x) {return x.data.name;}}},label: {normal: {show: true,textStyle: {}}},data: [{name: 'node01', des: 'nodedes01', symbolSize: 70, category: 0,},{name: 'node02', des: 'nodedes02', symbolSize: 50, category: 1,},{name: 'node03', des: 'nodedes3', symbolSize: 50, category: 1,}, { name: 'node04', des: 'nodedes04', symbolSize: 50, category: 1,}, { name: 'node05', des: 'nodedes05', symbolSize: 50, category: 1,},{name: 'node06', des: 'nodedes06', symbolSize: 50, category: 2,}],links: [{source: 'node01', target: 'node02', name: 'link01', des: 'link01des'},{source: 'node01', target: 'node03', name: '数字经济', des: 'link02des'}, {source: 'node01', target: 'node04', name: 'link03', des: 'link03des'}, {source: 'node01', target: 'node05', name: 'link04', des: 'link05des'}, {source: 'node06', target: 'node04', name: 'linkcat2', des: 'linkcat2'}],categories: categories,}]};myChart.setOption(option);
</script>
</body>
</html>
20240119
- 不算颜烨和王凯这两位老搭档,SXY已经是我认识最久的朋友(没有之一),而且是唯一能算得上是朋友的异性,而困扰我的问题正在于此。
- 晚上按约和SXY在芳甸路搞了顿火锅,如果我没有记错的话,这应该是我俩认识四年多来第二次吃饭,上一次在去年三月,近一年的时间,SXY似乎没有变化很多,还是那老样子,但我或许变了太多。这次很舒服,至少比上次要舒服得多,上次很不自然(因为觉得自己乳臭未干,而她已经快要毕业工作,所以大部分时间都是听众),但这次几乎没有什么可顾忌的事,也把想问的事给说出口了,答案在意料之中,凡事实际问题实际考虑,总是很难绝对地去评判,我困扰是因为上一段昙花一现的感情就败在这里,但总觉得有个异性朋友也无不合理,我真是不想就这么断弃,本来就没有几个能算得上是朋友的人,有个互相比较了解的老朋友,又是半个老乡,真的很不容易。
- LXY离校后,我也不想去叨扰,她的生活肯定要比我丰富得多,我做好自己的事就完了,万事等年后再说,年前主线任务就是水论文+训练,如果上半年要跑全马,无非是南京和苏州里选一场,那都是后话了。
- 今日跑休,明天计划进行长距离拉练,我最近状态很好,但是天气很差,如果明天上午世纪公园的训练取消,就下午找时间自行拉练,需要来一场30K探探底,雨不停就去打球(会打球真是件好事,可以对冲下雨的风险)。
排序函数:
df_name.sort_values(by, column_name, axis=0, ascending=True, inplace=False, kind=’quicksort’, na_position=’last’, ignore_index=False, key=None)
一列升一列降:
df_name.sort_values(by column_name, axis=0, ascending=True, inplace=False, kind=’quicksort’, na_position=’last’, ignore_index=False, key=None)
# -*- coding: utf-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cnimport os
import pandas as pd# 将所有的结果输出到同一文件(方便复制到EXCEL)
def out_to_the_same_file(root = "分类汇总"):strings = []filenames = []for filename in os.listdir(root):filepath = os.path.join(root, filename)with open(filepath, 'r', encoding="utf8") as f:strings.append(f.read())with open("comb.txt", 'w', encoding="utf8") as f:f.write("\n\n".join(strings))# 将所有的结果输出为可以直接复制到EXCEL中标准格式的代码()
def formatter_content(root = "分类汇总"):_orders = ["gender", "age", "city_level", "income", "huko","new_citizen", "education", "occupation",]_key_value = {_key: _value for _value, _key in enumerate(_orders)}def _key(_filename):_filename = _filename[:-4] # 扔掉最后的.csvfor _order in _orders:if _filename.endswith(f"_{_order}"):return _key_value[_order]assert False, _filename # 没有匹配到结果,抛出异常cur_suf = Nonecur_filenames = []for filename in os.listdir(root):suf = '-'.join(filename.split('-', 2)[:2]) # 这个就是题号,必然唯一if cur_suf is None:cur_suf = sufcur_filenames.append(filename)elif suf == cur_suf:cur_filenames.append(filename)else:cur_suf = sufcur_filenames = sorted(cur_filenames, key=_key, reverse=False)print(len(cur_filenames))print('\n'.join(cur_filenames))print('-*' * 16)views = [] # 同一道题不同的视图列表for i, fname in enumerate(cur_filenames):fpath = os.path.join(root, fname)with open(fpath, 'r', encoding="utf8") as f:df = pd.read_csv(f, sep='\t', header=[0, 1], index_col=0)view = df["percent"] # 我只要百分比views.append(view)views_row = pd.concat(views, axis=1)views_row.to_csv(f"{cur_suf}.csv", sep='\t', header=True, index=True)cur_filenames = []
formatter_content()
20240120
- 早上耐克训练不出意外地被取消,嘴上说不早起但还是定了闹钟,血亏。AK因为下午要年会,提前11点出去路跑30km,配速4’08",底蕴太厚,就这么加班,周六一觉起来还是这么猛。不过,我最近状态确实也很好,周一跟LXY
水跑完最后一练,周二周三立即换上大强度(体能+力量+变速),周四周五半练半休(下雨,羽球+爬楼),身体已经恢复得极好,感觉上30km应该是能下得来的。- 午睡起来,精神饱满,虽天气不佳,但无碍,环校10圈,25km(最难跑的是20号楼后面那段,风太大),基本上保持了4’20"的配速,中间只在20km处停了一次(到实验楼小解并补了点水),本来是觉得一定可以撑下来最后10km(4圈),但到第10圈后半程时明显感觉大腿不支,加上时至傍晚,气温降了很多,北风起,雨势渐长,不想强迫自己,就到此为止。整体上跑完比较舒适,腿没有不适,回实验室拿了张床垫吹着空调拉伸较长时间就完全恢复了。感觉上如果天气好,这个状态是可以顶完全马的,但无论如何,至少现在的水平是比之前任何一个时点都要显著高了许多。
- 晚上直接放开吃!!!

多记一个自动求导的例子,我发现其实之前写MRR的时候,对于ARGSORT的操作,其实近似的结果误差是可能会很大的,结果就是LOSS完全掉不下来,不知道该怎么处理:
y = 10 × ( x 1 + x 2 − 5 ) 2 + ( x 1 − x 2 ) 2 y=10\times(x_1+x_2-5)^2+(x_1-x_2)^2 y=10×(x1+x2−5)2+(x1−x2)2
import torch
from torch import nn# y = 10*(x1+x2-5)^2 + (x1-x2)^2
class Func(nn.Module):def __init__(self, size=2):super(Func, self).__init__()params = torch.rand((size,1),requires_grad=True)self.params = nn.Parameter(params)def forward(self, inputs):y = inputs[0] * torch.pow(self.params[0]+self.params[1]-inputs[1],2)\+ torch.pow(self.params[0]-self.params[1],2)return yclass cusLoss(nn.Module):def __init__(self):super(cusLoss, self).__init__()def forward(self,y_pred, y_true):return torch.abs(y_true-y_pred)model = Func(size=2)optimizer = torch.optim.AdamW(model.parameters(),lr=1,weight_decay=1e-5)
loss_func = cusLoss()
x = torch.tensor([10,5])for i in range(400):y_pred = model(x)loss = loss_func(y_pred,0)optimizer.zero_grad()loss.backward()optimizer.step()print("loss: ", loss.item())for item in model.parameters():print(item)
20240121
- 更阴间的天气,还好昨天没偷懒。午饭后找嘉伟练了1小时球,包场,一点半来了个不会打球的胖子,给嘉伟好好上了一课,嘉伟反手被压得惨不忍睹,每次救完后场想回中就被压,不回中就被放短,杀又杀不死,屁股都给打抽筋了。羽球说到底就是要能打得远,低质量近场球没有生路,业余场真的是一力降十会,自己平时手腕到大臂完全练不到,一点儿不会发力,过来的高远球怎么都打不回后场,好菜。
- 下午在图书馆看了会儿书,想想真是羡慕王凯,就连二战的时候他都会每天坚持看哲学书,我真的从大学之后就再也没有看过书。但是,现在又能理解,哲学反而确是最有用的,知识的说教,奇幻的故事,都已无用,实体书确实能给到更坚实的信仰与观念,是更好的指导。
- 招行满4减2的优惠还不结束,看来这学期吃食堂的人是真的少,库存用到现在还有结余,以前一般不满2个月就提前结束。从11月1日开始,我几乎一天不落地薅过来(一天两次,因为中午吃不到,所以只能早晚,现在连晚上都吃不到了,所以直接早上买两份),不过真也是多亏这活动,肯定不会每天都这么勤快地去学校吃早饭…
关于networkx画图的layout
import os
import numpy as np
import pandas as pd
import networkx as nx
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei']from collections import Counterdf = pd.read_csv("../graph.txt", sep='\t', header=None) # 这个文件每行就是\t分割的两个词G = nx.DiGraph() # 无多重边有向图
for i in range(df.shape[0]):G.add_edge(df.loc[i, 0], df.loc[i, 1]) # 添加一条边
nx.draw(G, with_labels=True)
这个所有的layout可以用:
for i in dir(nx):if "layout" in i:print(i)
记几个比较特色的布局展示:
默认随机布局:
nx.draw(G, pos=nx.circular_layout(G), with_labels=True)

nx.draw(G, pos=nx.kamada_kawai_layout(G), with_labels=True)
nx.draw(G, pos=nx.planar_layout(G), with_labels=True)

nx.draw(G, pos=nx.shell_layout(G), with_labels=True)
刚好跟circular是反过来的
nx.draw(G, pos=nx.spectral_layout(G), with_labels=True)
nx.draw(G, pos=nx.spiral_layout(G), with_labels=True)
20240122
- 我决定要首马破三,很疯狂,强如AK和嘉伟,首马不过257和259,但说句不要脸的,今冬厚积薄发,感觉破三已不遥远。
- 昨晚饭后,冷,但还是去操场看看,有段时间不一个人摇,不习惯,踱了半圈,没有动力,偶遇倒三角大哥(在跑129的30km课表),起兴,4’45"的配速边跑边聊了会儿,原来是本家,同济博士,目前也是冲击破三,5000米后大腿稍许发酸,不再勉强。去年七月尚不如他,然今非昔比。
- 近两三月,饮食、睡眠、训练趋于规律,每周1次力量和1-2次变速间歇,加上一月初两周养生10K,现在体能很好。手表目前预测是全马3小时9分。而前天的25K拉练,寒风细雨,也能连续2小时在接近破三的配速下,保持上身稳定和步伐轻盈。单论大腿与核心力量应该在嘉伟之上(只是体重远在嘉伟之上…),嘉伟上马前始终觉得短板在体能,所以疯狂堆跑量(连续几日20K以上,真很伤,按理当时他的水平稳开255,可冲250),而我现在觉得全马的一切都可以归结于心肺和力量,破三配速(4’15"/km)下心率不算高(约165bpm),而力量提升可以显著提高对乳酸的耐受能力,最直接的感受是大腿灌铅的时间大大减缓(我每次耐力训练都是大腿先扛不住,可能是体重的原因,但不想减,70kg刚刚好,男的太瘦实在不好,不精神)。
- 翻了些陈年旧账,地铁上仔细分析了一下过去两个月的人和事,以及说过的话,觉得自己想得太简单,而且想太多,缺乏自知之明。但将来的事很难讲,我也不是一个喜欢做长远计划的人,总之走一步看一步呗,时间会见证一切,年纪越大,越难强求。
- 跑休,下班去小姨家吃点儿好的,放在往年,现在该圆滚滚咯。
开三小时会(浪费三小时人生),感觉经济学研究,有些画靶射箭,用到的机器学习方法滞后,说作模型解释,但这么多年,也没人深入。如今风头偏转,还有人拿激光剑打原始人,拿GPT4跟RNN作对比(https://arxiv.org/abs/2312.08317),总之记一下AT那边的团队都想做啥吧:
- 小微借贷(平台)对金融包容性的影响研究
- 群体:女性、农村、教育程度低、未注册个体户
- 数据来源:调研数据、体系内数据
- 阿里关心的是监管的问题,大数据风控问题是黑箱子,不清楚
- 助贷、联合贷,不安全(与银行)
- 乡村振兴
- 阿里风控:
- 机器学习模型判断
- 策略,规则判断
- 几乎没有真人来判别
- 预授信额度,根据还款情况,经营情况进行改变
- 监管关心的风控只看结果
- 风控模型没有透露出来(防止被反控)
- 北大IMF:小微贷款可控性,自己定义(假设)很多变量来进行判别对比
- 模型一样,数据不一样,对比传统银行和蚂蚁业务风控模型
- 数据一样,模型不一样,对比传统银行和蚂蚁业务风控模型
- 但这样做很难发好刊
- 人机融合的借呗贷款批准研究
- 外部冲击对机构投资者和个人投资者的冲击不同
- 散户可能不会走,虽然金额小,但是规模大,所以会有个缓冲
- 散户行为一致,从众心理,不动则都不动,否则一拥而散
- 无感积分对支付宝用户黏性作用的研究(公司很关心,且很少人做的题)
- 无感积分:是一种便捷的积分获取方式,它允许消费者在购物中心或其他商圈内通过移动支付快速获得积分,整个过程不需要额外的操作。
- 是直接积分到对应的商场或其他消费场所,然后可以抵扣一些消费(比如停车费)
- 其实可能是无所谓微信或者积分,都是可以在对应的商场攒到积分的
- 先发优势,微信先搞的无感积分,支付宝后面也开始做了
- 这是个有差异化的研究,需要和业务对一下,看看是否能够提供类似的数据(这个数据的本质来源应该是商场,而非支付宝)
- 只要知道支付宝和哪些商场在何时进行合作的
- 比如支付宝上,用户点开“一点万象”小程序的数据是否有日志记录
- 这个研究是董事长关心的,因为用户黏性是战略性问题
- 注意:必须在业务在推进时进行研究,否则业务不鸟你
- 游戏化机制对用户消费的影响研究
- 常态化的游戏(蚂蚁财富小游戏、蚂蚁森林小游戏、好友互动的游戏)、阶段性促销的游戏活动(余额宝之类)、季节性游戏(集福)
- 老师主要指:蚂蚁森林、芭芭农场(这个是蚂蚁和淘宝互通的)、淘宝的数据(但蚂蚁和阿里完全切流,支付宝拿不到淘宝的数据)
- 研究动机:
- 淘宝上的游戏可能更促进消费
- 蚂蚁上的游戏可能更偏于公益
- 移动支付对小微企业/个人行为的影响研究
- 二维码支付的信用溢出作用:
- 比如银行不给无记录的人贷款,但是支付宝可以提供一些信贷记录来使得银行给这些人从0到1,再从1到N
- 蚂蚁森林对用户绿色环保行为的影响
- 目前平台上已经有20多个和蚂蚁森林相关的课题
- 理财行为对个人消费行为的影响
- 理财行为
- 房地产价格的变动,对消费行为的影响
- 比如房价上升10%,所以觉得赚到了,可能会去消费,但是房子不会立即出卖,因此需要消费信贷来解决
- 用户的理财行为、支付宝细类数据
- 结论:财富效应,理财行为加剧了非理性消费,是不好的,但在学术上很喜欢
- 监管很关注花呗对大学生、甚至更小的学生非理性消费的问题
- 蚂蚁对此出台了很多相应的产品,改善这种现象
- 波动上涨与平稳上涨对财富效应的效应(行为经济学)
- 消费类型:
- 生存型消费:衣食住行
- 发展型消费:学习、运动
- 享受型消费:娱乐
- 这个应该说的是西财数据
- 预测资产?
- 在预测中,引入因果视角
- 在信息不全(如缺乏资产数据)的情况下,这个其实是半监督、弱监督学习
- 反事实推理、因果学习
- 疑问;调研数据拿到的数据
- 房产证、资产信息证明,很难较准
- 问卷无偏?万分之五的回收率(已经是在)
- 模型内部纠偏(防止问卷调研本身带来的偏差)
- 联合订阅对用户接受度的影响分析
- 爱奇艺订阅,爱奇艺和其他平台(淘宝、腾讯之类的)一起订阅(典型的比如在移动流量套餐)
- 免费用几个月,再联合订阅,再变成单一订阅,看看是否能够促进用户进行
- 关键点:支付宝能够查阅到的这个问题
- 但问题是有可能是忘记关自动订阅,结果就是
- 需要挑一些联合订阅的事件,然后从历史记录上扒扒看是否有一些记录看得到
20240123
- rebuttling… 这次coling小分给的最高的reviewer,summary分给的最低,别人都是刀子嘴豆腐心,就他豆腐嘴刀子心,下手真特么狠。
- 西湖,故事旧缘处,记忆的起点。但不想去瞎凑热闹,纯找不自在,不过这条标毅线确实不错,26k爬升1300米,路线很美,以后越野赛前的热身候选。安迪是杭州人,他告诉我西湖边上还有更长的43k超毅线,跨年时浙大甚至有人开发一条100k的超长越野线,强悍。
- -4℃,晚上跟安迪慢摇了10k,恢复状态,其实并不冷,我只穿了一件卫衣和一条西裤,5’07"的配速,一路说话,平均心率才142bpm。但后面做箭步的时候手指头真冻掉了,戴手套都不管用,做了4组(×30)后实在痛苦,把铃片搬去大活,吹着暖气补到9组,差强人意。
- 跟安迪聊下来,越来越觉得杭州是个好地方,我一直有种感觉,就是上海金融化太深,太务虚(其实北京也是同理,只是非金融),核心技术还是集中在杭州、深圳这些地方,关键那边房价好低,听说安迪阿里总部附近的房价都跌到2w多,而且基础设施建得很好,除了教育资源相对紧俏。确实没得非要往上海这围城里钻,但谁又知道杭州何尝不是一座围城?一切都变化得太快,难以预料。
ax v.s. plt
fig = plt.figure(figsize=(6,4))
ax = fig.add_subplot(2, 3, 1) # 2行,3列,左上角# 具体而言:
# Three integers (nrows, ncols, index).
# The subplot will take the index position on a grid with nrows rows and ncols columns.
# index starts at 1 in the upper left corner and increases to the right.
# index can also be a two-tuple specifying the (first, last) indices (1-based, and including last) of the subplot,
# e.g., fig.add_subplot(3, 1, (1, 2)) makes a subplot that spans the upper 2/3 of the figure. ax和plt的区别在于很多函数都要加`set_`,plt直接`xlabel, ylabel, title`即可
```python
ax.set_xlabel('...')
ax.set_ylabel('...')
ax.set_title('...')
# 这样也是一种方法,但我觉得画的没上面好看
fig, ax = plt.subplots(2, 2)
plt.subplots_adjust(hspace=1, wspace=0.5)
(TBD)
这篇关于【更新】cyのMemo(20231231~)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







