本文主要是介绍SQL Server 2014 安装配置always on,备份计划,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为两台数据库服务器配置安装Always on,windows环境为server 2016
域控:172.26.12.52
db1:172.26.2.215
db2:172.26.2.216
虚拟IP:172.26.2.217 ,172.26.2.219
仲裁机:172.26.2.218
先加入域控,
在db1、2上都安装故障转移集群:
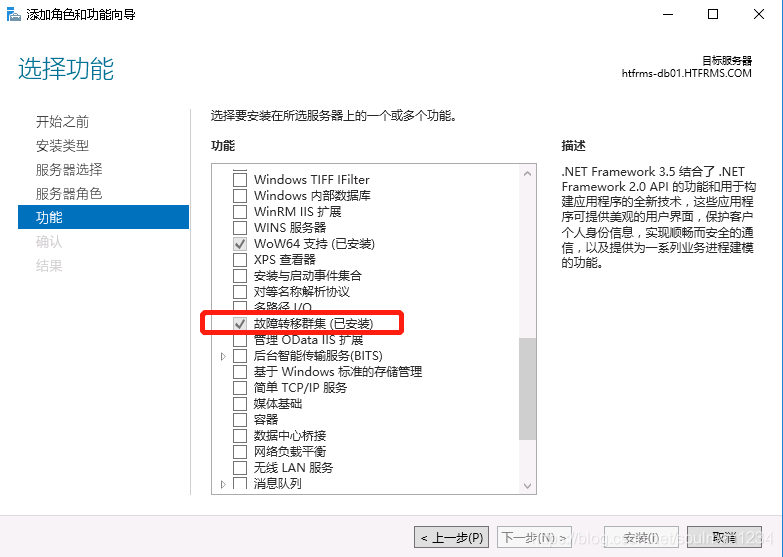

安装完成后在仲裁管理机器上创建集群(也可以先测试集群,就是选择下图的验证配置,和创建集群差不多,会先验证配置):

验证配置如下,输入地址,点添加即可(这里记得关闭防火墙,笔者这里遇到域控防火墙未关,然后添加失败的情况):

运行测试:

完成后创建集群,输入地址,进行下一步,需要配置集群名称和访问地址:

完成:
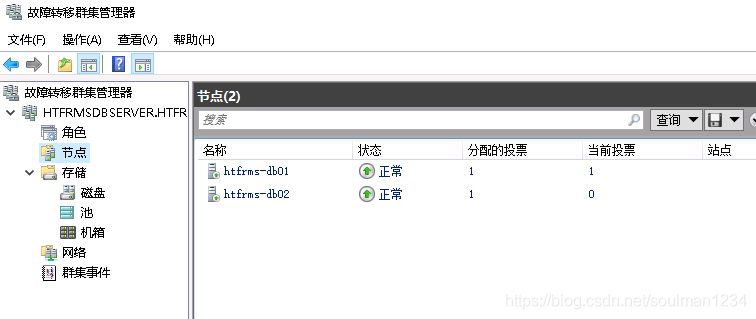
配置集群仲裁:

设置共享文件夹:

完成:

修改两台db服务器的Sql server 服务和代理服务为域控账户登录(这里笔者在安装sql server 时就把此域账户加入了)
切换到域账户登录到服务器,后续添加alwaysOn要用到。
在服务里找到代理服务,选择登录,此账户,输入域账户密码:

设置好代理后再设置主服务。
设置好域账户登录到sql server并授权sysadmin:

修改两台db服务器的配置管理器,设置启用always on:

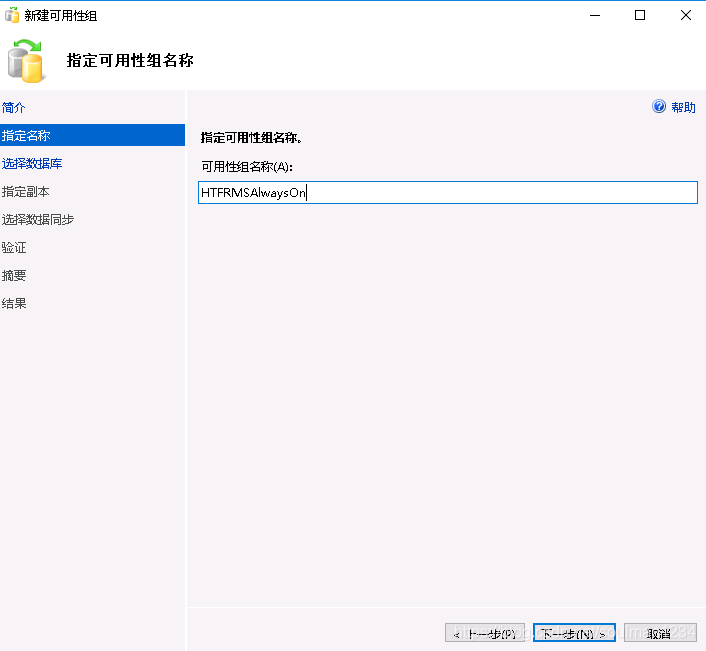
在db1中新建always on:

新建名称:
部分数据库是备份过来的,不满足先决条件,需要完整恢复模式:

选择需要设置的数据库,属性里的选项中,设置恢复模式为完整:

如果上述还不行,可能会有这种情况出现,你本身bak文件为简单模式备份而来,这时候你先修改属性里的恢复模式再执行备份,然后使用备份文件再恢复一次才行:

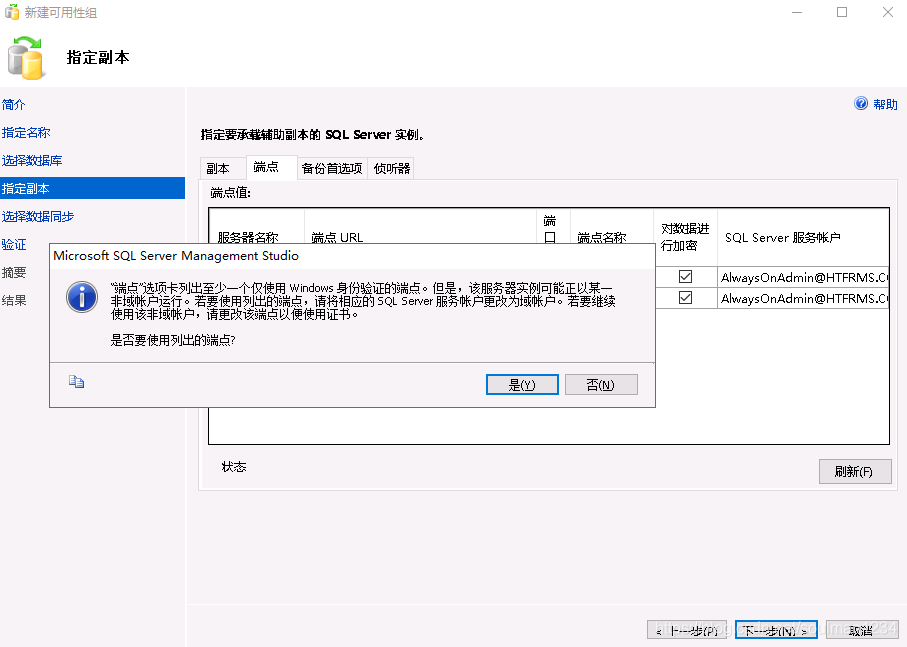
选择添加副本:

选择Db2(这里就是前面为什么要设置域账户到登录并用域账户登录到服务器了)

设置自动故障转移和同步提交:

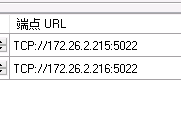
端点URL最好配置为ip:
“备份首选项”和“侦听器”不需要设置,保持默认,选择是,使用列出的端点。
选择仅连接,下一步,验证:

配置下一步,运行,完成:

已完成:


在看看故障:

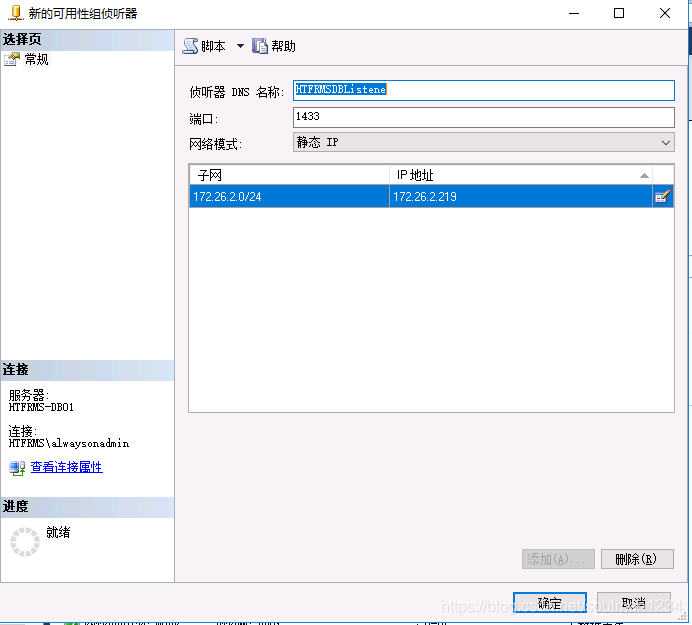
配置侦听器:

添加静态IP:

完成:
测试alwayson,重启db1的服务器的sql server :

DB2会自动切换为主要:

配置备份任务:
设置always on 备份首选:
连上主副本服务器,在主节点服务器sql management studio上,连上本地sql服务:

选择always on 属性:

选择备份首选,主副本,确定。

创建数据库的备份计划任务:
启用sql server 代理:
选择维护计划向导:

下一步:

设置名称啥的:

点击更改,配置为对应的计划后确定:

下一步:
可以选择计划的任务,例如:备份完整数据库、差异数据库、日志等,勾选要做的任务,点击下一步:

下一步:
选择对应数据库下一步:

再次选择数据库,在目标选择数据库备份的路径:

设置备份目录:

选项里面设置备份过期时间等,根据实际情况设置:

定期删除就保存较久的备份文件(根据实际情况设置):

下一步:

配置清单:


完成:

这篇关于SQL Server 2014 安装配置always on,备份计划的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





