本文主要是介绍【一文秒懂】Ftrace系统调试工具使用终极指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


文章目录
- 1、Ftrace是什么
- 2、Ftrace的实现原理
- 2.1 Ftrace框架图
- 2.2 Ftrace是如何记录信息的
- 3、如何使用Ftrace
- 3.1 配置详解
- 3.2 挂载debugfs文件系统
- 3.3 traceing目录介绍
- 3.3.1 trace
- 3.3.2 trace_pipe
- 3.3.3 tracing_on
- 3.3.4 current_tracer
- 3.3.5 available_filter_functions
- 3.3.6 available_tracers
- 3.3.7 buffer_size_kb
- 3.3.8 buffer_total_size_kb
- 3.3.9 set_ftrace_filter
- 3.3.10 set_ftrace_notrace
- 3.3.11 set_ftrace_pid
- 3.3.12 set_graph_function
- 3.3.12 set_graph_notrace
- 3.4 简单使用示例
- 3.4.1 函数追踪
- 3.4.2 追踪图形显示
- 3.4.3 动态过滤追踪
- 3.4.4 重置追踪
- 4、进阶用法
- 4.1 追踪任意命令
- 4.2 追踪指定函数的调用流程
- 4.3 追踪指定模块的所有函数
- 5、自动化管理
- 6、总结
1、Ftrace是什么
Ftrace是Function Trace的简写,由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6.27 中开始就内置了。
Ftrace是一个系统内部提供的追踪工具,旨在帮助内核设计和开发人员去追踪系统内部的函数调用流程。
随着Ftrace的不断完善,除了追踪函数调用流程的作用外,还可以用来调试和分析系统的延迟和性能问题,并发展成为一个追踪类调试工具的框架。
除了Ftrace外,追踪类调试工具还包括:
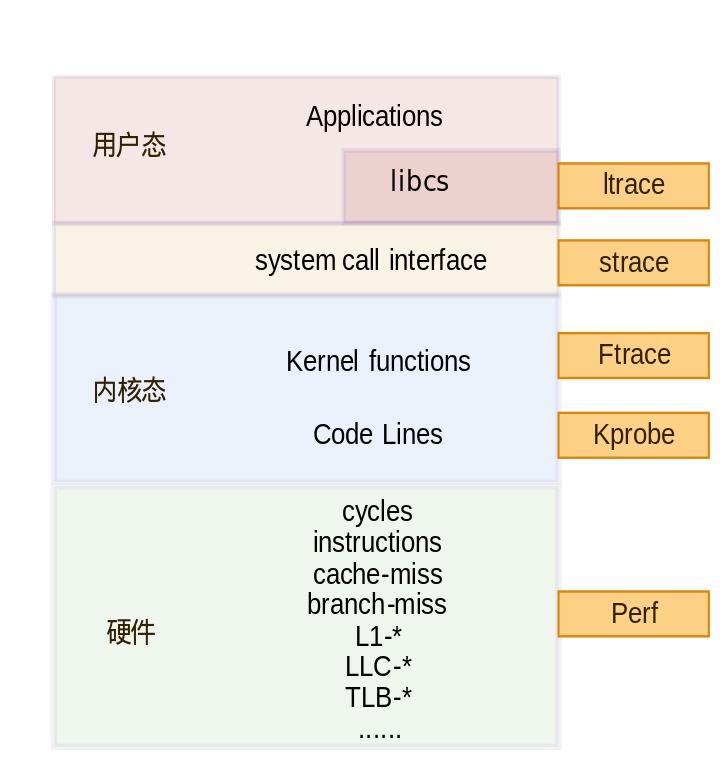
2、Ftrace的实现原理
为了帮助我们更好的使用Ftrace,我们有必要简单了解Ftrace的实现原理。
2.1 Ftrace框架图
Ftrace的框架图如下:

由框架图我们可以知道:
ftrace包括多种类型的tracers,每个tracer完成不同的功能- 将这些不同类型的
tracers注册进入ftrace framework - 各类
tracers收集不同的信息,并放入到Ring buffer缓冲区以供调用。
2.2 Ftrace是如何记录信息的
Ftrace采用了静态插桩和动态插桩两种方式来实现。
静态插桩:
我们在Kernel中打开了CONFIG_FUNCTION_TRACER功能后,会增加一个-pg的一个编译选项,这个编译选项的作用就是为每个函数入口处,都会插入bl mcount跳转指令,使得每个函数运行时都会进入mcount函数。
Ftrace一旦使能,对kernel中所有的函数插桩,这带来的性能开销是惊人的,有可能导致人们弃用Ftrace功能。
为了解决这个问题,开发者推出了Dynamic ftrace,以此来优化整体的性能。
动态插桩:
这里的动态,是指的动态修改函数指令。
- 编译时,记录所有被添加跳转指令的函数,这里表示所有支持追踪的函数。
- 内核将所有跳转指令替换为
nop指令,以实现非调试状态性能零损失。 - 根据
function tracer设置,动态将被调试函数的nop指令,替换为跳转指令,以实现追踪。
总而言之,Ftrace记录数据可以总结为以下几个步骤:
- 打开编译选项
-pg,为每个函数都增加跳转指令 - 记录这些可追踪的函数,并为了减少性能消耗,将跳转函数替换为
nop指令 - 通过
flag标志位来动态管理,将需要追踪的函数预留的nop指令替换回追踪指令,记录调试信息。
3、如何使用Ftrace
3.1 配置详解
CONFIG_FTRACE=y # 启用了 Ftrace
CONFIG_FUNCTION_TRACER=y # 启用函数级别的追踪器
CONFIG_HAVE_FUNCTION_GRAPH_TRACER=y # 表示内核支持图形显示
CONFIG_FUNCTION_GRAPH_TRACER=y # 以图形的方式显示函数追踪过程
CONFIG_STACK_TRACER=y # 启用堆栈追踪器,用于跟踪内核函数调用的堆栈信息。
CONFIG_DYNAMIC_FTRACE=y # 启用动态 Ftrace,允许在运行时启用和禁用 Ftrace 功能。
CONFIG_HAVE_FTRACE_NMI_ENTER=y # 表示内核支持非屏蔽中断(NMI)时进入 Ftrace 的功能
CONFIG_HAVE_FTRACE_MCOUNT_RECORD=y # 表示内核支持通过 mcount 记录函数调用关系。
CONFIG_FTRACE_NMI_ENTER=y # 表示内核支持通过 mcount 记录函数调用关系。
CONFIG_FTRACE_SYSCALLS=y # 系统调用的追踪
CONFIG_FTRACE_MCOUNT_RECORD=y # 启用 mcount 记录函数调用关系。
CONFIG_SCHED_TRACER=y # 支持调度追踪
CONFIG_FUNCTION_PROFILER=y # 启用函数分析器,主要用于记录函数的执行时间和调用次数
CONFIG_DEBUG_FS=y # 启用 Debug 文件系统支持
上面只是介绍了部分配置,更多详细配置可自行了解。
并且上述配置不一定全部打开,勾选自己需要的即可,通常我们选择
CONFIG_FUNCTION_TRACER和CONFIG_HAVE_FUNCTION_GRAPH_TRACER即可,然后编译烧录到开发板。
3.2 挂载debugfs文件系统
Ftrace是基于debugfs调试文件系统的,所以我们的第一步就是先挂载debugfs。
mount -t debugfs none /sys/kernel/debug
此时我们能够在/sys/kernel/debug下看到内核支持的所有的调试信息了。
# cd /sys/kernel/debug/
# ls
asoc gpio regmap
bdi ieee80211 sched_debug
block memblock sched_features
clk mmc0 sleep_time
device_component mmc1 suspend_stats
devices_deferred mtd tracing
dma_buf opp ubi
extfrag pinctrl ubifs
fault_around_bytes pm_qos wakeup_sources
3.3 traceing目录介绍
在/sys/kernel/debug目录下,包含的是kernel所有的调试信息,本章只关注与tracing目录,下面挑选一些比较重要的属性文件来分析。
万变不离其宗,如此复杂的框架,设计人员已经提供了
README文件,里面详解了各个属性文件的含义,我建议抛弃本文,看README吧:)
3.3.1 trace
trace :包含当前追踪的内容,以人类可读的格式展现,通过echo > trace来清除。
3.3.2 trace_pipe
trace_pipe 和 trace 一样,都是记录当前的追踪内容,但它和 trace 不一样的是:
- 对
trace_pipe的读操作将会阻塞,直到有新的追踪数据进来为止; - 当前从
trace_pipe读取的内容将被消耗掉,再次读trace_pipe又会阻塞到新数据进来为止。
简单的来说,
cat trace_pipe是堵塞读取,有数据就读,没数据就等待;而cat trace有没有数据都是直接返回的
3.3.3 tracing_on
tracing_on:向 tracing_on 写入 1,启用追踪;向 tracing_on 写入 0,停止追踪。
追踪使用
ring buffer记录追踪数据。修改tracing_on不会影响ring buffer当前记录的内容。
3.3.4 current_tracer
current_tracer 表示当前启用的 tracer ,默认为 nop ,即不做任何追踪工作:
# cat current_tracer
nop
3.3.5 available_filter_functions
available_filter_functions:可以被追踪的函数列表,即可以写到 set_ftrace_filter,set_ftrace_notrace,set_graph_function,set_graph_notrace 文件的函数列表。
3.3.6 available_tracers
available_tracers 文件中包含的是当前编译到内核的 tracer 列表,也表示当前内核支持的tracer列表。
该列表的内容,就是可以写到 current_tracer 的 tracer 名。
# cat available_tracers
function_graph function nop
nop:表示为空,不追踪function:追踪函数调用function_graph:以图形形式追踪函数调用
3.3.7 buffer_size_kb
buffer_size_kb 记录 CPU buffer 的大小,单位为 KB 。
per_cpu/cpuX/buffer_size_kb 记录 每个CPU buffer 大小,单位为 KB 。可通过写 buffer_size_kb 来改变 CPU buffer 的大小。
3.3.8 buffer_total_size_kb
buffer_total_size_kb 记录所有 CPU buffer 的总大小,即所有 CPU buffer 大小总和。
如有 128 个 CPU buffer ,每个大小 7KB,则
buffer_total_size_kb记录的总大小为 128 * 7KB = 896。
buffer_total_size_kb 文件是只读的。
3.3.9 set_ftrace_filter
set_ftrace_filter :过滤函数追踪,仅仅追踪写入该文件的函数名。
可填入的参数,可以通过available_filter_functions文件查看当前支持的函数名。
该过滤功能,也有很多其他变体,如追踪某个模块的函数调用等。
官方给的示例:
Format: :mod:<module-name>
example: echo :mod:ext3 > set_ftrace_filter # 该模块必须是已经加载进去的模块
3.3.10 set_ftrace_notrace
set_ftrace_notrace:和 set_ftrace_filter 刚好相反,系统禁用对其中列举函数的追踪。
3.3.11 set_ftrace_pid
系统对 set_ftrace_pid 文件中指定的 PID进程进行追踪。
如果开启了 options/function-fork 选项,fork 的子进程的 PID 也会自动加入文件,同时该选项也会引起系统自动将退出进程的 PID 从文件中移除。
3.3.12 set_graph_function
此文件中列出的函数将导致函数图跟踪器仅跟踪这些函数以及它们调用的函数。
但是该跟踪的记录,仍然受set_ftrace_filter 和 set_ftrace_notrace 的影响。
3.3.12 set_graph_notrace
与 set_graph_function 类似,但当函数被命中时,将禁用函数图跟踪,直到退出函数。
更多干货可见:高级工程师聚集地,助力大家更上一层楼!
3.4 简单使用示例
一般我们挂载上
debugfs后,tracing_on是处于打开状态的。
3.4.1 函数追踪
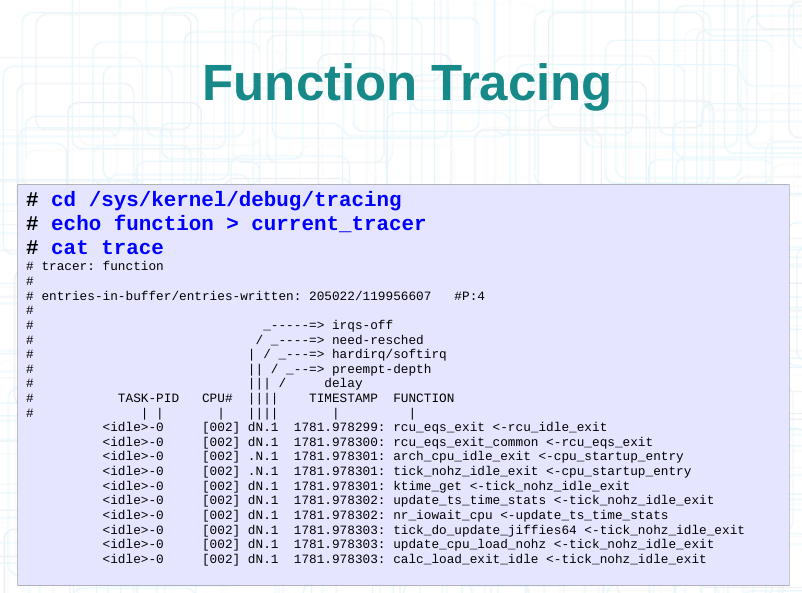
3.4.2 追踪图形显示
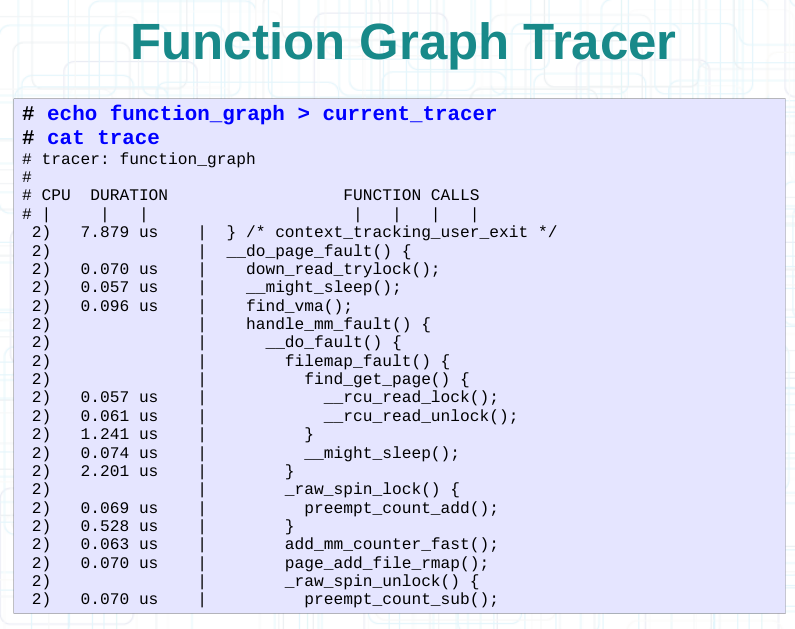
3.4.3 动态过滤追踪
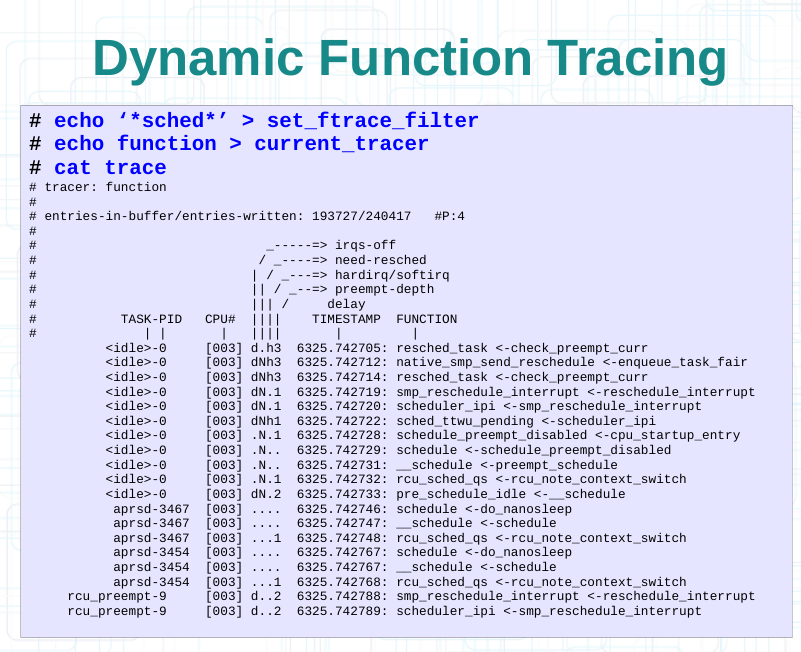
3.4.4 重置追踪
echo 0 > tracing_on # 关闭trace
echo > trace # 清空当前trace记录
cat available_tracers # 查看当前支持的追踪类型
echo function_graph > current_tracer # 设置当前的追踪类型
echo 1 > tracing_on # 开启追踪
cat trace # 查看追踪结果
4、进阶用法
上述章节,只是介绍了Ftrace最基本的命令,下面来看一下Ftrace在具体问题中的用法!
4.1 追踪任意命令
如何追踪我们执行的命令呢?
Ftrace支持追踪特定进程,通过set_ftrace_pid属性来设置指定进程。然后在该进程中,执行特定的命令。
首先我们需要设置好我们的追踪器
mount -t debugfs none /sys/kernel/debug
cd /sys/kernel/debug/tracing
echo 0 > tracing_on # 关闭追踪器
echo function > current_tracer # 设置当前追踪类别在我们设置好追踪器后,使用如下命令,即可追踪我们执行的命令your_command
echo > trace; echo $$ > set_ftrace_pid; echo 1 > tracing_on; your_command; echo 0 > tracing_on
为什么要写成一条语句?
因为ftrace当打开时,在没有过滤的情况下,瞬间会抓取到内核所有的函数调用,为了更准确的抓取我们执行的命令,所以需要打开trace,执行完命令后,马上关闭。
4.2 追踪指定函数的调用流程
跟踪函数的时候,设置 echo 1 > options/func_stack_trace 即可在 trace 结果中获取追踪函数的调用栈。
mount -t debugfs none /sys/kernel/debug
cd /sys/kernel/debug/tracing
echo 0 > tracing_on # 关闭追踪器
cat available_filter_functions | grep "xxxxxx" # 搜索函数是否存在
echo xxxxxx > set_ftrace_filter # 设定追踪的函数
echo function > current_tracer # 设置当前追踪类别
echo 1 > options/func_stack_trace # 记录堆栈信息
echo > trace # 清空缓存
echo 1 > tracing_on # 开始追踪
效果如下:
# cat trace
# tracer: function
#
# entries-in-buffer/entries-written: 2/2 #P:3
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |kworker/1:1-59 [001] .... 168.954199: mmc_rescan <-process_one_workkworker/1:1-59 [001] .... 168.954248: <stack trace>=> mmc_rescan=> process_one_work=> worker_thread=> kthread=> ret_from_fork=> 0
4.3 追踪指定模块的所有函数
要想我们的ko文件能够被Ftrace记录到,我们需要在编译模块的时候,加上编译参数-pg,这点很重要,否则你在available_filter_functions列表中,查找不到你想要的函数。
然后,需要我们设置过滤器,设置方法有以下几种:
- 按模块直接过滤:
# 示例
Format: :mod:<module-name>
example: echo :mod:ext3 > set_ftrace_filter
追踪
ext3模块内的所有函数
- 按函数直接过滤
如果该模块内的函数,命名都有一定的规则,可以按照正则表达式来过滤
# 示例
echo "mmc*" > set_ftrace_filter
过滤包含
mmc字符的所有函数
- 按照函数差异来过滤
如果函数命名没有规律,又想过滤该模块所有函数,该怎么办?
按照加载模块前后的函数差异,写入到文件中来过滤
cat available_filter_functions > /tmp/1.txt
cat available_filter_functions > /tmp/2.txt
diff /tmp/1.txt /tmp/2.txt > /tmp/3.txt
cat /tmp/3.txt | sed 's/^+//' | awk '{print $1}' # 如果diff出来格式前带有+-号,需要手动去掉
cat /tmp/3.txt > set_ftrace_filter
5、自动化管理
Ftrace功能很强大,在内核层面我们通过echo和cat即可获取我们想要的所有信息,但是通过一次一次敲命令显得有些繁琐,自己也对常用的功能整合了一个自动化脚本,能够通过命令行,直接追踪特定模块、函数、命令,极大提高了调试效率。
PS:自动化脚本获取:公~号【嵌入式艺术】
# /root/common_trace.sh
Usage: /root/common_trace.sh {module|funcs|funcs_stack|command|clear}/root/common_trace.sh module ext4 /root/common_trace.sh funcs sysfs /root/common_trace.sh funcs_stack sysfs /root/common_trace.sh command sysfs [functions] /root/common_trace.sh clear
脚本主要实现的功能有:
- 追踪指定模块,查看所有调用流程
- 追踪指定函数,查看该函数的调用链
- 追踪指定函数,获取堆栈信息
- 追踪用户命令,查看所有调用流程,并可选择指定函数来查看调用流程。
脚本除了
command功能外,其他功能都需要手动调用common_trace.sh clear来停止追踪。
6、总结
以上,介绍了Ftrace的由来,实现原理,以及如何使用Ftrace,并最终提供了自动化测试脚本,希望对大家有所帮助。
这篇关于【一文秒懂】Ftrace系统调试工具使用终极指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








