本文主要是介绍【软件开发底层知识修炼】二十一 ABI-应用程序二进制接口一,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 前面学习了可执行程序的结构,点击链接查看上一篇文章:【软件开发底层知识修炼】二十 深入理解可执行程序的结构
- 本篇文章开始新的篇章,学习应用程序的二进制接口-ABI。
文章目录
- 1 什么是ABI(Application Binary Interface)
- 1 ABI的广义与狭义概念
- 2 什么是EABI(Embedded Application Binary Interface)
- 3 ABI规范示例
- 4 ABI的其他方面
- 4.1 ABI定义的基础数据类型
- 4.2 ABI与移植性
- 4.3 ABI规定的结构体与联合体的字节对齐方式
- 5 不同的ABI规范下的内存对齐方式代码分析
- 5.1 代码
- 5.2 Linux平台下运行结果
- 5.3 Windows平台下运行结果
- 6 总结
1 什么是ABI(Application Binary Interface)
ABI,就是应用程序二进制接口。乍一听,可能不知道是啥。后面会慢慢深入理解。
那么ABI大概包括哪些内容呢?
- 数据类型的大小,数据的对其方式
- 函数调用时发生的调用约定。比如参数的入栈顺序啊等
- 系统调用的编号,以及系统调用的方式。不同的系统可能系统函数的中断号不同等
- 目标文件的二进制格式,程序库的格式等。比如Linux下的ELF格式的文件与Windows下的可执行文件就有区别。
以上说的那些区别,说的窄一些就是不同的系统平台,虽然写的C语言可能一样,但是最终编译成的二进制可执行文件肯定是在格式上有一定的区别。当然在内存对齐啊,函数参数入栈顺序,系统调用上等等等都有可能存在区别。
我们可以看到,这些区别都比较接近底层,不像API,API是源代码层面不一样。比如不同的操作系统的API可能就有一定的区别。但是也很有可能不同的操作系统的API一样,但是ABI就不一样。总结来说API与ABI具有以下特征:
- ABI和API是不同层面的规范
- ABI是二进制层面的规范
- API是源码层面的规范
- ABI和API没有直接的联系
- 遵循相同的ABI的系统,API可能不一样
- 所提供的API相同的系统,遵循的ABI可能相同
我们要注意一点:ABI与API没有必然的关系
1 ABI的广义与狭义概念
- 广义上ABI 的概念
泛指应用程序在二进制层面应该遵循的规范
- 狭义上ABI的概念
特指
- 某个具体硬件平台的ABI规范文档
- 某个具体操作系统平台的ABI规范文档
- 某个具体虚拟机平台的ABI规范文档
2 什么是EABI(Embedded Application Binary Interface)
EABI就是:嵌入式应用程序二进制接口
EABI与ABI基本相同。我们只需要注意一点不同:EABI的应用程序中可以直接使用特权指令。至于什么是特权指令。可以转移到我的另一个博客专栏系列:《手写操作系统》专栏中查询。
3 ABI规范示例
上面说了那么多概念,可能也没能让小白明白什么是ABI规范。下面给一个例子来说明。
我们之前学过C/C++内嵌汇编,如果不懂还是需要去看前面的文章。
为什么下面的代码能够以0作为退出码结束程序的运行?

为什么呢?为什么上述代码就是代表sys_exit的系统调用呢?这其实就是一种规定。你如果是规定人员你也刻意规定2是sys_exit的系统调用编号。
但是别人就规定编号1是sys_exit的系统调用编号。并且规定在发生这个系统调用时eax存的是系统调用编号,而ebx存的是退出码,这里我们的退出码是0. 那么我们写这种内嵌汇编就要按照别人的ABI规范来。这是没办反的,除非你有能力去修改这种规范。
那么上面就是一种ABI规范。这个例子如果还是不能让你理解,也没关系,下面还有代码的例子
4 ABI的其他方面
4.1 ABI定义的基础数据类型
ABI定义了基础数据类型的大小。
我们都知道在我们电脑上写的程序int是4字节。因为我们在Intel的X86平台。如果你足够牛逼你也可以自己造硬件自己规定ABI规范,你可以将int定义为100字节都没人管你。
当然这是很难的。我们还是先来看看X86平台下,ABI规范定义的基础数据类型的大小吧。如下图:
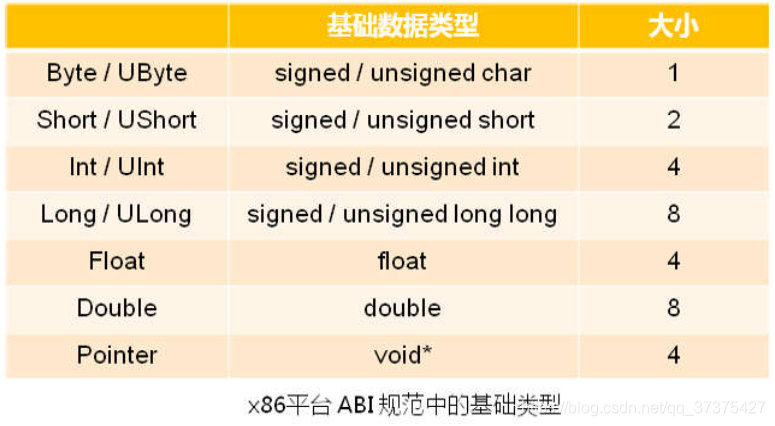
上面那些,我想大家都背过。现在知道怎么来了的吧。
4.2 ABI与移植性
首先先看下面的一张架构图:

-
上面的图很容易看懂。
-
ABI规范的基础数据类型及大小:在硬件CPU上面,肯定是ABI规范的基础数据类型大小。随着CPU硬件架构的不同,基础数据类型可能也不同。
-
类型适配层: 但是我们还要写程序,为了方便写程序,在ABI规范的上面肯定要有一个适配层。这个适配层是将ABI规范层重新定义成我们方便写代码的样子。并且平台改变时只需要重新定义类型适配层。typedef就是属于类型适配层。类型及大小不随平台而改变。
-
应用程序框架层与应用程序逻辑层:我们写代码最接近的就是这两层了,尤其是逻辑层,你写代码写的大多是逻辑层。牛逼点的可能去写框架。
- 上面的类型适配层可能没有讲明白。其实就是针对ABI规范的基础数据类型,自己给重新定义一下。比如基础数据类型int是4字节,我们可以使用
typedef int INT,这样我们以后写代码可以就完全使用INT代表4字节的整形。
但是如果换了一个平台,假如这个平台没有int基础数据类型,假设它有一个叫做newint
的基础数据类型是4字节整形(当然这是我们假设的,实际上没有)。此时我们只需要将typedef int INT修改为typedef newint INT。而我们的应用程序框架和应用程序代码,就完全不用修改。这大大地提高了我们的应用程序的移植性。
说到这里,应该明白了为什么本节的小标题叫做ABI与移植性了吧。如果不懂,再看两遍。
4.3 ABI规定的结构体与联合体的字节对齐方式
我们面试经常被问到结构体的对齐方式。这实际上也是ABI规范的。至于为什么那么规定,就要涉及到硬件与底层内存了。一般就是为了提高CPU的执行效率,也没什么神秘的。
下面我们就来看看几个简单结构体的内存对齐方式:
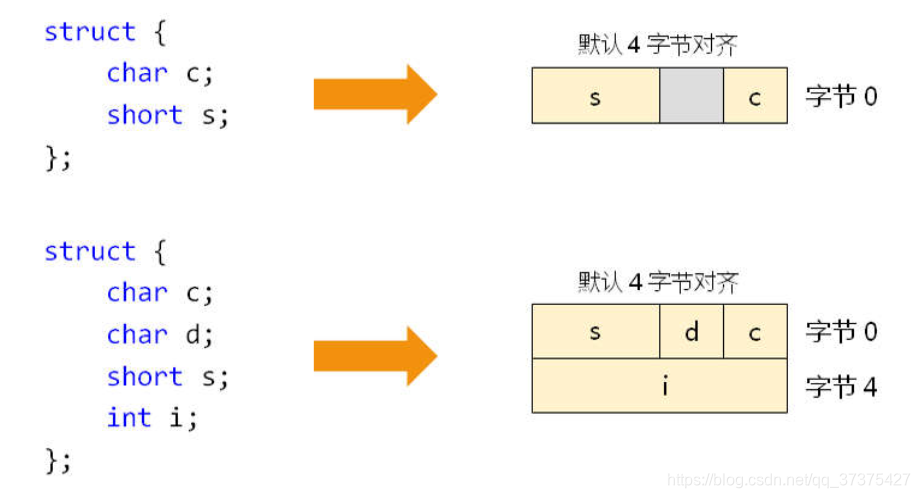
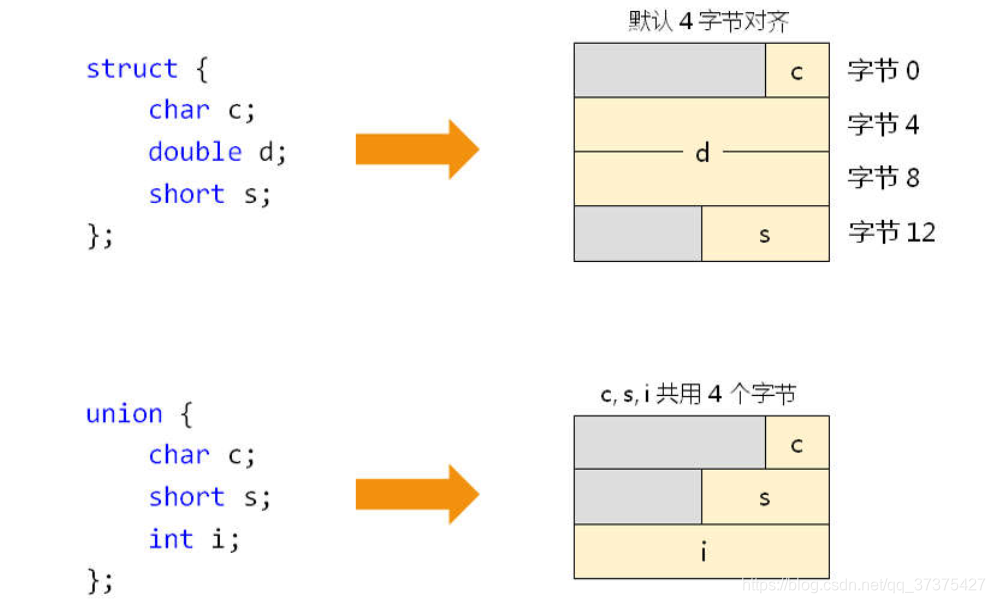
- 注意以上四个结构体的对齐方式,实际上就是因为ABI的规范,当然,就算没有ABI规范,我们应该也能够知道它的内存布局是上线那样。毕竟那是最基本的知识。
- 有一点需要注意的是上面的内存图中从上往下是低地址到高地址。每一行是4字节大小。
- 上面的联合体,实际上只有一行,不是3行12字节。它是相当于1行一共4字节。这4字节供c,s,i公用。
5 不同的ABI规范下的内存对齐方式代码分析
本节内容以代码实际案例来分析,在Linux下与WIindows下的不同ABI对应的不同内存对齐方式。
主要是以结构体的内存对齐方式来说。
在看具体代码之前,首先要知道一个知识点:
- 位域
所占用的内存是以比特来记的。
5.1 代码
- bit_field.c
#include <stdio.h>struct {short s : 9;int j : 9;char c;short t : 9;short u : 9;char d;
} s;int main(int argc, char* argv[])
{int i = 0;int* p = (int*)&s;printf("sizeof = %d\n", sizeof(s));s.s = 0x1FF;s.j = 0x1FF;s.c = 0xFF;s.t = 0x1FF;s.u = 0x1FF;s.d = 0xFF;for(i=0; i<sizeof(s)/sizeof(*p); i++){printf("%X\n", *p++);}return 0;
}
上述代码很容易读懂。我们主要想研究该代码在Linux平台下与Windows平台下的内存对齐方式的不同。
5.2 Linux平台下运行结果
首先在Linux下编译运行程序,得到结果如下:
- gcc bit_field.c -o test
- ./test
运行结果为:
sizeof = 12
FF03FFFF
1FF01FF
FF
这个运行结果看起来也不是很容易看明白内存到底是怎么分布的,将其转换成内存图就可以明白了:
-
结构体为:

-
Linux下的内存图为:

由上图可知s,j各占9个比特,并且它们是挨着的。
由于默认是4字节对齐,并且第一个4字节后面还有14个比特,所以还能存放c变量。但是如果把4字节划分成4个单独的字节这样看,那么无疑最后的24bit-31bit是一字节。所以c放在最后的24bit-31bit,更加符合对齐的意思。虽然是默认4字节对齐,但是在这4字节中,也同样要按字节对齐。这样能够提高CPU的执行效率。
FF03FFFFt和u是如上图存放的。这符合程序的运行结果:
1FF01FF至于为什么变量u不放到9bit-17bit,这个就是具体的ABI规范文档规定的。到底原理是什么就涉及的有点远了。这里不在多讲,以后有机会会详细讲解。d占用最后的4字节。
一共占用12字节,这与程序的运行结果是一样的。
但是注意这是Linux平台下的内存模型。
我们注意到上图中有一个压缩存储,实际上Linux平台下,内存模型都是压缩存储。
5.3 Windows平台下运行结果
在Windows下的vs下运行该程序,结果如下:
sizeof = 161FF1FF1FF00FFFF01FF
这个运行结果看起来也不是很容易看明白内存到底是怎么分布的,将其转换成内存图就可以明白了:
-
结构体为:
-
Windows下的内存图为:

- 在默认4字节的情况下,Windows下,s占用4字节,其实s只占了9个比特,但是由于字节对齐,后面的23比特都是空的。
1FF- j , c, t, u, d也很容易看出来。但是与上一小节的Linux下的有所不同。
- 上图中有一个非压缩存储。在Windows下就是非压缩存储。各个变量离的有一定的距离。
- 很明显,在不同的平台,内存对齐方式都是不一样的。这就是ABI规范的不同带来的不同。
6 总结
- 广义上的ABI指应用程序在二进制层面需要遵守的约定
- 狭义上的ABI指一个具体硬件或者操作系统的规范文档
- ABI定义了基础数据类型的大小
- ABI定义了结构体/联合体的内存对齐方式
欢迎与我共同探讨各种技术。
这篇关于【软件开发底层知识修炼】二十一 ABI-应用程序二进制接口一的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




