本文主要是介绍代码随想录第十八天 513 找树左下角的值 112 路径之和 106 从中序与后序遍历序列构造二叉树,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LeetCode 513 找树左下角的值
题目描述
给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。
假设二叉树中至少有一个节点。
示例 1:

输入: root = [2,1,3] 输出: 1
示例 2:

输入: [1,2,3,4,null,5,6,null,null,7] 输出: 7
思路
1.确定递归函数的参数和返回值
参数必须有要遍历的树的根节点,还有就是一个int型的变量用来记录最长深度。 这里就不需要返回值了,所以递归函数的返回类型为void。
本题还需要类里的两个全局变量,maxLen用来记录最大深度,result记录最大深度最左节点的数值。
代码如下:
int maxDepth = INT_MIN; // 全局变量 记录最大深度
int result; // 全局变量 最大深度最左节点的数值
void traversal(TreeNode* root, int depth)
2.确定终止条件
当遇到叶子节点的时候,就需要统计一下最大的深度了,所以需要遇到叶子节点来更新最大深度。
代码如下:
if (root->left == NULL && root->right == NULL) {if (depth > maxDepth) {maxDepth = depth; // 更新最大深度result = root->val; // 最大深度最左面的数值}return;
}
3.确定单层递归的逻辑
在找最大深度的时候,递归的过程中依然要使用回溯,代码如下:
// 中
if (root->left) { // 左depth++; // 深度加一traversal(root->left, depth);depth--; // 回溯,深度减一
}
if (root->right) { // 右depth++; // 深度加一traversal(root->right, depth);depth--; // 回溯,深度减一
}
return;代码实现
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:int maxDepth = INT_MIN;int result;void traversal(TreeNode* root,int depth){if(root -> left == NULL && root -> right == NULL){if(depth > maxDepth){maxDepth = depth;result = root -> val;}return; }if(root -> left){depth++;traversal(root -> left,depth);depth--;}if(root -> right){depth++;traversal(root -> right,depth);depth--;}return;}int findBottomLeftValue(TreeNode* root) {int depth;traversal(root,depth);return result;}
};LeetCode 112 路径之和
题目描述
给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。
叶子节点 是指没有子节点的节点。
示例 1:

输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22 输出:true 解释:等于目标和的根节点到叶节点路径如上图所示。
示例 2:

输入:root = [1,2,3], targetSum = 5 输出:false 解释:树中存在两条根节点到叶子节点的路径: (1 --> 2): 和为 3 (1 --> 3): 和为 4 不存在 sum = 5 的根节点到叶子节点的路径。
示例 3:
输入:root = [], targetSum = 0 输出:false 解释:由于树是空的,所以不存在根节点到叶子节点的路径。
思路
1.确定递归函数的参数和返回类型
参数:需要二叉树的根节点,还需要一个计数器,这个计数器用来计算二叉树的一条边之和是否正好是目标和,计数器为int型。
再来看返回值,递归函数什么时候需要返回值?什么时候不需要返回值?这里总结如下三点:
- 如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值。(这种情况就是本文下半部分介绍的113.路径总和ii)
- 如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值。
- 如果要搜索其中一条符合条件的路径,那么递归一定需要返回值,因为遇到符合条件的路径了就要及时返回。(本题的情况)
而本题我们要找一条符合条件的路径,所以递归函数需要返回值,及时返回,那么返回类型是什么呢?
如图所示:
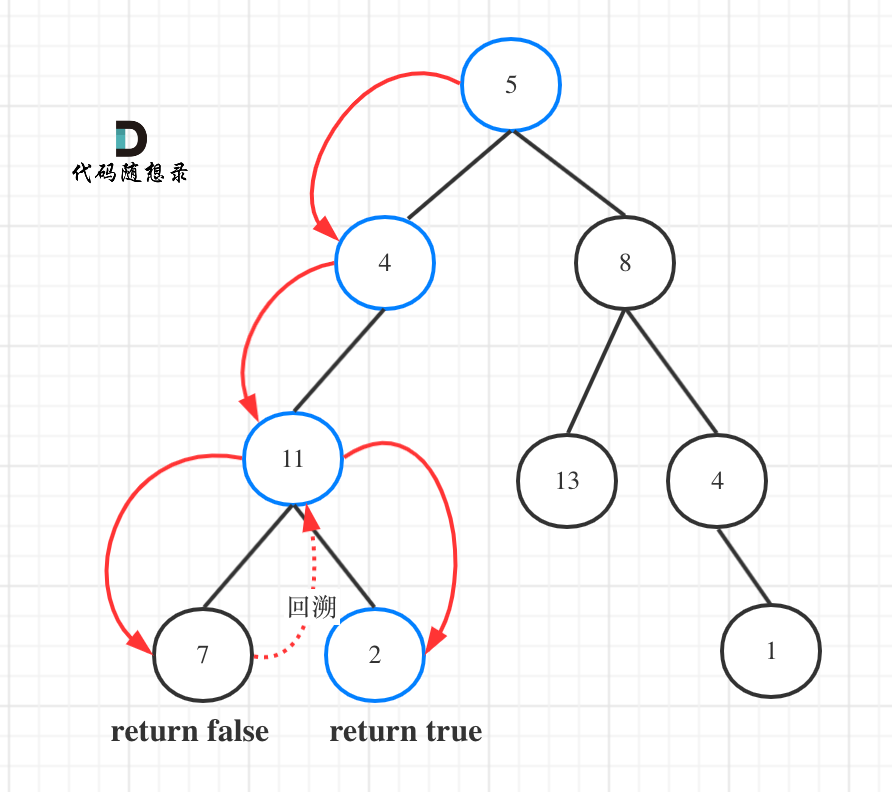
图中可以看出,遍历的路线,并不要遍历整棵树,所以递归函数需要返回值,可以用bool类型表示。
所以代码如下:
bool traversal(treenode* cur, int count) // 注意函数的返回类型
2.确定终止条件
首先计数器如何统计这一条路径的和呢?
不要去累加然后判断是否等于目标和,那么代码比较麻烦,可以用递减,让计数器count初始为目标和,然后每次减去遍历路径节点上的数值。
如果最后count == 0,同时到了叶子节点的话,说明找到了目标和。
如果遍历到了叶子节点,count不为0,就是没找到。
递归终止条件代码如下:
if (!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点,并且计数为0
if (!cur->left && !cur->right) return false; // 遇到叶子节点而没有找到合适的边,直接返回
3.确定单层递归的逻辑
因为终止条件是判断叶子节点,所以递归的过程中就不要让空节点进入递归了。
递归函数是有返回值的,如果递归函数返回true,说明找到了合适的路径,应该立刻返回。
代码如下:
if (cur->left) { // 左 (空节点不遍历)// 遇到叶子节点返回true,则直接返回trueif (traversal(cur->left, count - cur->left->val)) return true; // 注意这里有回溯的逻辑
}
if (cur->right) { // 右 (空节点不遍历)// 遇到叶子节点返回true,则直接返回trueif (traversal(cur->right, count - cur->right->val)) return true; // 注意这里有回溯的逻辑
}
return false;代码实现
class Solution {
private:bool traversal(TreeNode* cur, int count) {if (!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点,并且计数为0if (!cur->left && !cur->right) return false; // 遇到叶子节点直接返回if (cur->left) { // 左count -= cur->left->val; // 递归,处理节点;if (traversal(cur->left, count)) return true;count += cur->left->val; // 回溯,撤销处理结果}if (cur->right) { // 右count -= cur->right->val; // 递归,处理节点;if (traversal(cur->right, count)) return true;count += cur->right->val; // 回溯,撤销处理结果}return false;}public:bool hasPathSum(TreeNode* root, int sum) {if (root == NULL) return false;return traversal(root, sum - root->val);}
};LeetCode 106 从中序与后序遍历序列构造二叉树
题目描述
给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。
示例 1:
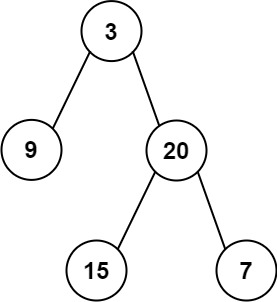
输入:inorder = [9,3,15,20,7], postorder = [9,15,7,20,3] 输出:[3,9,20,null,null,15,7]
示例 2:
输入:inorder = [-1], postorder = [-1] 输出:[-1]
思路
中序:9 3 15 20 7 左中右
后续:9 15 7 20 3 左右中
遍历二叉树的思路是,首先后续数组的最后一个元素一定是根节点,找到根节点之后切割中序数组,根节点前面的数组为左子树,后面的为右子树。根据中序数组左子树和右子树的元素个数,切割后序数组,例如左子树一共有3个数字,那么后续数组的前三个元素就是左子树,第四个到第size-1个就是右子树,然后再找后序数组左子树和右子树的最后一个元素,这个元素就是左子树或右子树的中间节点。依此类推,中间节点左右两边的数据再分为左子树和右子树,直到所有元素都遍历了为止。
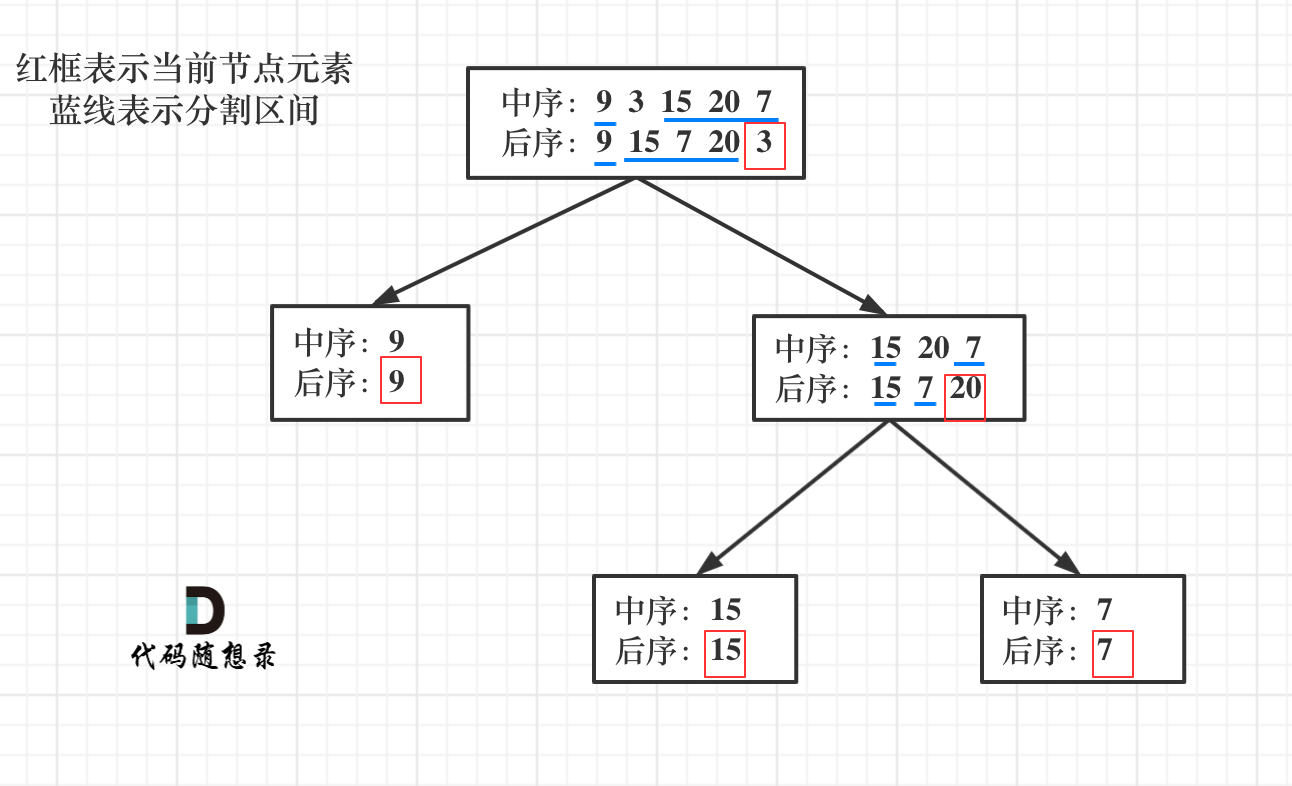
代码思路如下:
-
第一步:如果数组大小为零的话,说明是空节点了。
-
第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
-
第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
-
第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
-
第五步:切割后序数组,切成后序左数组和后序右数组
-
第六步:递归处理左区间和右区间
代码实现
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {if(postorder.size() == 0) return NULL;int rootvalue = postorder[postorder.size() - 1];TreeNode* root = new TreeNode(rootvalue);if(postorder.size() == 1) return root;int index = 0;for(index = 0;index < inorder.size();index++){if(inorder[index] == rootvalue) break; }vector<int> leftinorder;vector<int> rightinorder;vector<int> leftpostorder;vector<int> rightpostorder;for(int i = 0;i < index;i++){leftpostorder.push_back(postorder[i]);} for(int i = index;i < postorder.size()-1;i++){rightpostorder.push_back(postorder[i]);}for(int i = 0;i < index;i++){leftinorder.push_back(inorder[i]);}for(int i = index+1;i < postorder.size();i++){rightinorder.push_back(inorder[i]);}root -> left = buildTree(leftinorder,leftpostorder);root -> right = buildTree(rightinorder,rightpostorder);return root;}
};ps:这里已知前序,中序或者中序,后序都可以构造唯一的二叉树,但是前序和后序不可以,因为前序和后序的左子树,右子树都是相连的,不可以构造唯一的二叉树。
LeetCode 654 最大二叉树
题目描述
给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建:
- 创建一个根节点,其值为
nums中的最大值。 - 递归地在最大值 左边 的 子数组前缀上 构建左子树。
- 递归地在最大值 右边 的 子数组后缀上 构建右子树。
返回 nums 构建的 最大二叉树 。
示例 1:

输入:nums = [3,2,1,6,0,5] 输出:[6,3,5,null,2,0,null,null,1] 解释:递归调用如下所示: - [3,2,1,6,0,5] 中的最大值是 6 ,左边部分是 [3,2,1] ,右边部分是 [0,5] 。- [3,2,1] 中的最大值是 3 ,左边部分是 [] ,右边部分是 [2,1] 。- 空数组,无子节点。- [2,1] 中的最大值是 2 ,左边部分是 [] ,右边部分是 [1] 。- 空数组,无子节点。- 只有一个元素,所以子节点是一个值为 1 的节点。- [0,5] 中的最大值是 5 ,左边部分是 [0] ,右边部分是 [] 。- 只有一个元素,所以子节点是一个值为 0 的节点。- 空数组,无子节点。
示例 2:
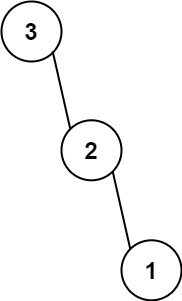
输入:nums = [3,2,1] 输出:[3,null,2,null,1]
思路
本题的思路和上一题的思路基本一致,刚开始没有判断nums的size是否为0,会有如下报错。
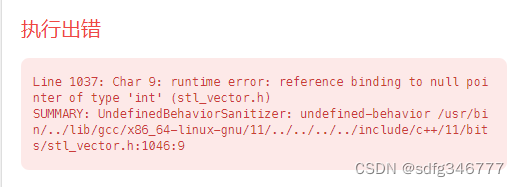
刚开始的nums不为空,递归几轮之后可能数组就会为空,所以还是要判断,size为1也要判断。
代码实现
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}* };*/
class Solution {
public:TreeNode* constructMaximumBinaryTree(vector<int>& nums) {if(nums.size() == 0) return NULL;int maxvalue = 0;int maxindex;for(int i = 0;i < nums.size();i++){if(nums[i] > maxvalue){maxvalue = nums[i];maxindex = i;}}TreeNode* root = new TreeNode(maxvalue);if(nums.size() == 1) return root;vector<int> lefttree;vector<int> righttree;for(int i = 0;i < maxindex;i++){lefttree.push_back(nums[i]);}for(int i = maxindex+1;i < nums.size();i++){righttree.push_back(nums[i]);}root -> left = constructMaximumBinaryTree(lefttree);root -> right = constructMaximumBinaryTree(righttree);return root;}
};这篇关于代码随想录第十八天 513 找树左下角的值 112 路径之和 106 从中序与后序遍历序列构造二叉树的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




