本文主要是介绍mongdb学习总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.MongoDB主键:使用ObjectId()设置_id字段
在MongoDB中,_id字段是集合的主键,以便可以在集合中唯一地标识每个文档。_id字段包含唯一的ObjectID值。
默认情况下,在集合中插入文档时,如果您没有在字段名称中添加带有_id的字段名称,则MongoDB将自动添加一个Object id字段,下图所示
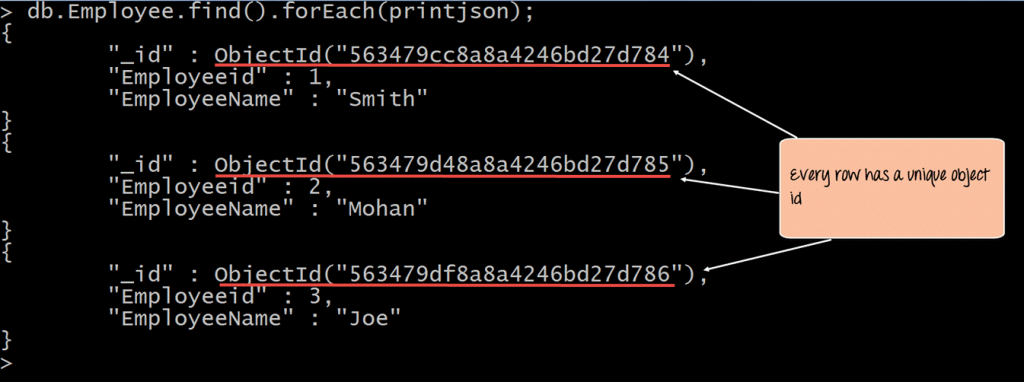
当查询集合中的文档时,可以看到该集合中每个文档的ObjectId。
如果要确保在创建集合时MongoDB不会创建_id字段,并且要指定自己的ID作为集合的_id,则需要在创建集合时明确定义它。
在显式创建id字段时,需要使用名称中的_id创建它。
让我们看一个有关如何实现的例子。
db.Employee.insert({_ id:10,“ EmployeeName”:“ Smith”})
代码说明:
- 我们假设正在创建集合中的第一个文档,因此在创建集合时在上述语句中,我们显式定义了字段_id并为其定义了一个值。
如果命令执行成功,现在使用find命令显示集合中的文档,则将显示以下输出结果:
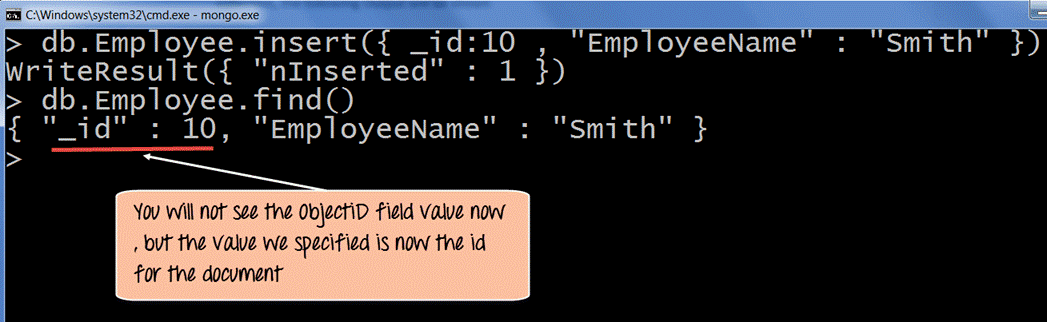
结果显示表明,我们在创建集合时定义的_id字段现在作为集合的主键。
每个mongoDB中的文档都需要一个主键,这个主键在每个集合中是唯一的,默认会带唯一索引,主键为_id字段。我们同样可以使用别的值作为 _id字段的值,但是当程序没有提供_id时,mongo会自动生成一个 _id。
mongoDB默认的 _id为一个12字节的16进制的字符串,这个字符串中保存着有用的信息,具体构成如下图所示: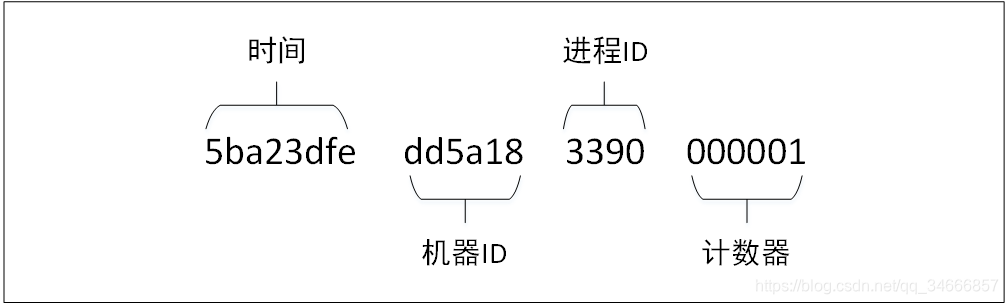
最重要的时开头的四个字节的时间信息,为Unix时间戳。后面三个字节是机器ID,两个字节的进程ID,三个字节的计数器。计数器会自动增长,可以保证同一进程、同一时刻内不会重复。
_id由这四部分组成,就可以保证在分布式的情况下,保证 _id全局唯一。mongo如此设计就可以保证及时 _id是在驱动中生成(而不是在服务器端),也可以保证全局唯一。可以参考java mongo驱动中的ObejectId类(org.bson.types.ObjectId)。
在文档(表)中没有创建时间字段的情况下,使用默认的_id还可以从主键中获取时间信息。
在对集合进行分片时,mongo只能确保分片键值是唯一的(唯一索引只对这个分片中的数据有效),不能在任一键上强制唯一,因为一个分片无法通过检查另一个分片来确认是否有重复值,即使主键_id字段也是一样,因此,如无必须,当对集合进行分片时,最好默认使用由驱动生成的ObjectId,这个可以确保唯一性。如果客户端没有强制唯一,当两个相同 _id的文档迁移到同一个分片上时,就会丢失数据。
前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
接下来的 3 个字节是机器标识码
紧接的两个字节由进程 id 组成 PID
最后三个字节是随机数

2.MongoDB 索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
createIndex() 方法
MongoDB使用 createIndex() 方法来创建索引。
注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(),之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。语法
createIndex()方法基本语法格式如下所示:
>db.collection.createIndex(keys, options)语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
实例
>db.col.createIndex({"title":1})
>createIndex() 方法中你也可以设置使用多个字段创建索引(关系型数据库中称作复合索引)。
>db.col.createIndex({"title":1,"description":-1})
>
1.2 重建索引reIndex()
db.COLLECTION_NAME.reIndex()如,重建集合sites的所有索引:
> db.sites.reIndex()
{"nIndexesWas" : 2,"nIndexes" : 2,"indexes" : [{"key" : {"_id" : 1},"name" : "_id_","ns" : "newDB.sites"},{"key" : {"name" : 1,"domain" : -1},"name" : "name_1_domain_-1","ns" : "newDB.sites"}],"ok" : 1
}索引的类型和属性
唯一索引
唯一索引是索引具有的一种属性,让索引具备唯一性,确保这张表中,该条索引数据不会重复出现。在每一次insert和update操作时,都会进行索引的唯一性校验,保证该索引的字段组合在表中唯一。
复合索引
概念:指的是将多个键组合到一起创建索引,终极目的是加速匹配多个键的查询。
看例子来理解复合索引是最直接的方式:
所以我们可以建立复合索引 db.flights.createIndex({ flight: 1, price: 1 },{background: true})
内嵌索引
可以在嵌套的文档上建立索引,方式与建立正常索引完全一致。
个人信息表结构如下,包含了省市区三级的地址信息,如果想要给城市(city)添加索引,其实就和正常添索引一样
db.personInfos.createIndex({“address.city”:1})
const personInfo = new Schema({name: { type: String, required: true },address: {province: { type: String, required: true },city: { type: String, required: true }, district: { type: String, required: true },}
}, {timestamps: true});地理位置索引(Geospatial Index)
能很好的解决一些场景,比如『查找附近的美食』、『查找附近的加油站』等
文本索引(Text Index)
能解决快速文本查找的需求,比如,日志平台,相对日志关键词查找,如果通过正则来查找的话效率极低,这时就可以通过文本索引的形式来进行查找
索引的优点
1.减少数据扫描:避免全表扫描代价
2.减少内存计算:避免分组排序计算
3.提供数据约束:唯一和时间约束性
3.mongodb持久化
mongodb与mysql不同,mysql的每一次更新操作都会直接写入硬盘,但是mongo不会,做为内存型数据库,数据操作会先写入内存,然后再会持久化到硬盘中去,那么mongo是如何持久化的呢
mongodb在启动时,专门初始化一个线程不断循环(除非应用crash掉),用于在一定时间周期内来从defer队列中获取要持久化的数据并写入到磁盘的journal(日志)和mongofile(数据)处,当然因为它不是在用户添加记录时就写到磁盘上,所以按mongodb开发者说,它不会造成性能上的损耗,因为看过代码发现,当进行CUD操作时,记录(Record类型)都被放入到defer队列中以供延时批量(groupcommit)提交写入,但相信其中时间周期参数是个要认真考量的参数,系统为90毫秒,如果该值更低的话,可能会造成频繁磁盘操作,过高又会造成系统宕机时数据丢失过。
4.与mysql 数据库的优缺点比较
MongoDB具有另一个优势,它具有高度可扩展性。 如果数据量巨大,那么这不是问题,您只需向集群添加更多节点,一切就可以顺利进行。 唯一的缺点是查询比MySQL慢。
格式有所更改,您也可以以最小的痛苦反映这些更改。
脱离业务场景来说技术选型是没有任何意义的
-
开发更高效:公司初期处于探索期,产品迭代非常快,MongoDB 是 NoSQL 数据库,不需要做建库建表等 DDL 操作,特别在产品快速迭代,需要频繁增减字段的时候就更高效,当然这个也是有代价的,从本质上来说,MongoDB 是读模式,它几乎不检查写入的内容是否合法,对数据 Schema 的解释是在应用程序的代码中,导致写入数据的约束性是没有保证的。
-
运维更高效:当时公司研发非常少,这段时间整个后端只有两个工程师,没有专职的运维和 DBA ,但是 MongoDB 的单机性能比 MySQL 要高不少,不但对数据库的运维成本要低不少,并且当时除了几个热点库外,其他的库 MongoDB 可以直接扛住流量压力,省去了中间的 Cache 层,让开发和运维都更高效。
-
有事务需求的场景不多:当时使用的是 MongoDB 2.x 和 3.x,只提供了数据一致性的选择(强一致性、单调一致性和最终一致性)和原子操作,在少数的几个场景,比如交易相关的场景,通过选择强一致性和原子操作,再在应用层实现 MVCC 的机制,可以满足简单的事务需求。
关系型数据库可以理解为依赖一个模型来创建的数据库
地理位置存储
MongoDB支持地理位置、二维空间索引,可以存储经纬度,因此可以很快的计算出两点之间的距离,等位置信息。如查询附近的人、或者订餐系统、配送系统等
数据规模增长很快
前面提到过关系型数据库数据量过大时,需要进行分库分表,这样真正操作起来可能会比较麻烦。如果选择mongo进行分库分表操作时,就会变得很简单。
保证高可用的环境
Mongo本身就拥有高可用及分区的解决方案,设置主从服务器非常方便,除此之外Mongo还可以快速并且安全的实现故障节点的转移。
文件存储需求
GridFS是MongoDB规范,用于存储和检索图片、音频、视频等大文件。GridFS虽然是文件存储的一种方式,可以存储超过16M的文件。但是它本身又是存储在MongoDB集合中的
其他场景
如游戏开发中我们可以通过MongoDB存储用户信息、装备、积分等,除此之外物流系统、社交系统、甚至物联网系统,Mongo都能提供完美的数据存储服务。
MySQL
业务存在许多事务性的操作,需要保证事务的强一致性。
如果你有这种强事务一致性的数据,可以考虑MySQL。普通的多变的数据存储,可以MongoDB。
| 数据库 | MongoDB | MySQL |
|---|---|---|
| 数据库模型 | 非关系型 | 关系型 |
| 存储方式 | 以类JSON的文档的格式存储 | 不同引擎有不同的存储方式 |
| 查询语句 | MongoDB查询方式(类似JavaScript的函数) | SQL语句 |
| 数据处理方式 | 基于内存,将热数据存放在物理内存中,从而达到高速读写 | 不同引擎有自己的特点 |
| 成熟度 | 新兴数据库,成熟度较低 | 成熟度高 |
| 广泛度 | NoSQL数据库中,比较完善且开源,使用人数在不断增长 | 开源数据库,市场份额不断增长 |
| 事务性 | 仅支持单文档事务操作,弱一致性 | 支持事务操作 |
| 占用空间 | 占用空间大 | 占用空间小 |
| join操作 | MongoDB没有join | MySQL支持join |
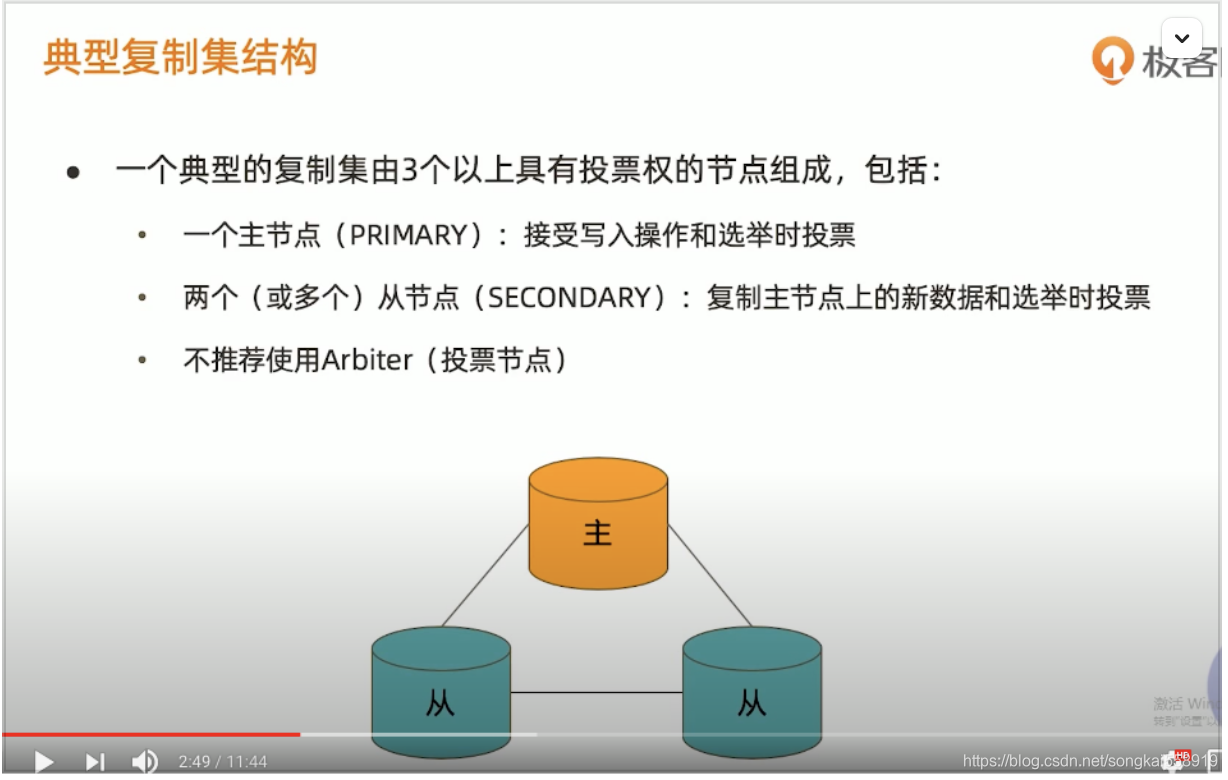
5.主从复制
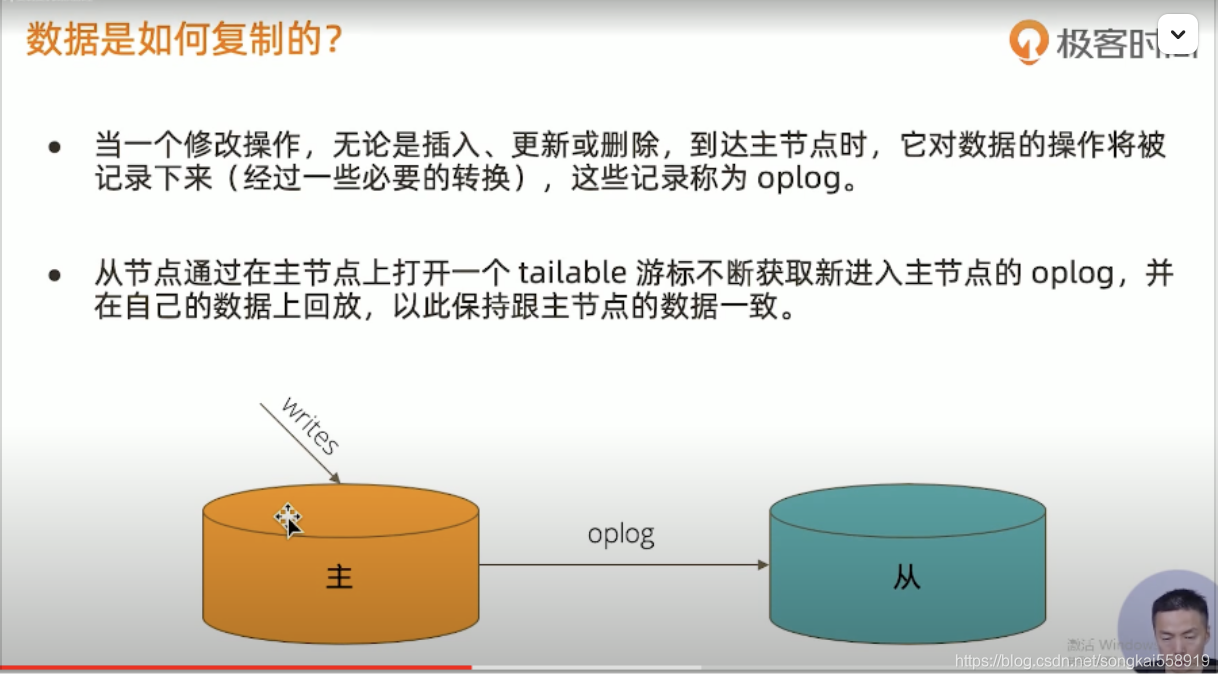
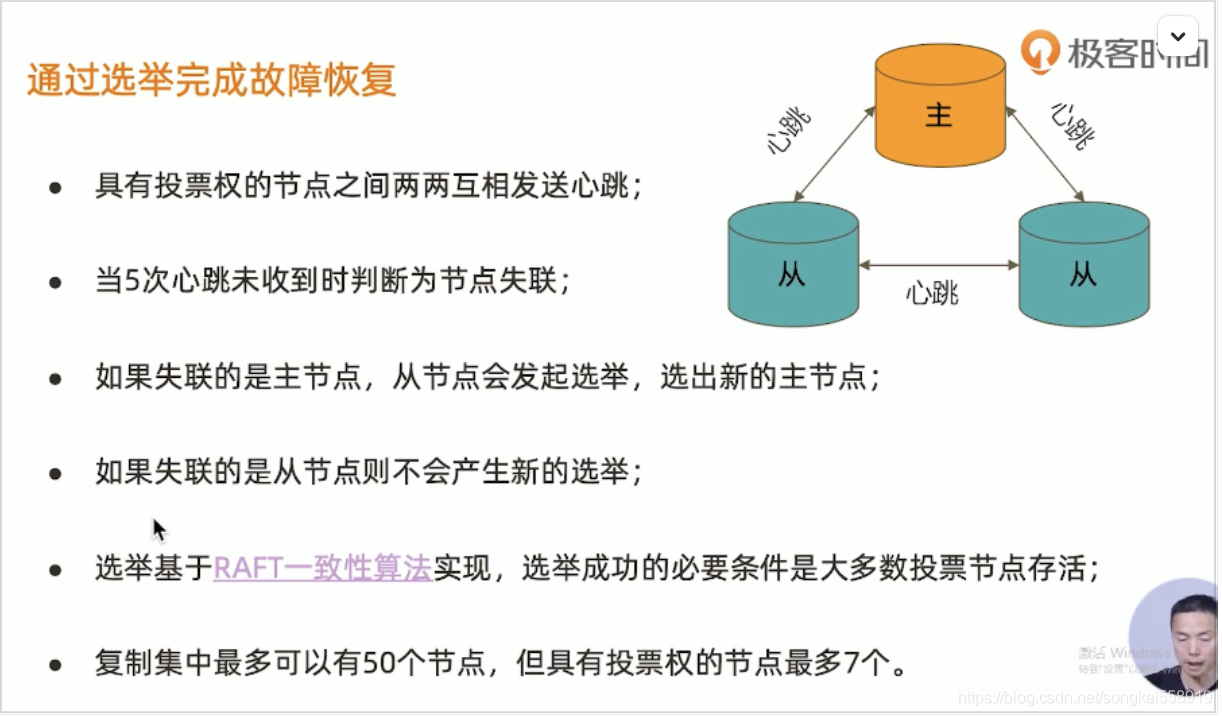


这篇关于mongdb学习总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







