本文主要是介绍科学研究设计五:实验设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明
这是Bangor University 2007年School of Sport Health & Exercise Sciences的教学讲义,大家可以在这里查看原课程的讲义
课程目录
- 1.什么是科学?
- 2.定量分析和定性分析
- 3.抽样
- 4.测量
- 5.实验设计
- 6.有效性
- 7.单案例设计
为什么要看这个?
这个在我看来,适合大学生或者刚入学的研究生学习,主要为了提高科学素养、培养科学研究的思维以及一些研究设计中要考虑的很多细节问题。虽然里面没有很多高超的方法,而且课程也是十年前的,但是里面对于科学的理解以及思考问题的思维方式确实值得刚进入科研这条不归路的人学习。
格式说明
- 标题格式都按照markdown排版的,但是标题之间的关系可能没有排好,主要是参考了原课程网站的标题设计
- 书中一些专有名词或者大牛们说的话都没有翻译,以防止因为我的问题导致误解
- 名人名言和我自己的理解都是用引言格式标注的,不同的是,大牛们的话是英文,我自己的理解是中文
- 因为课程中有问答环节,问题我会用加粗来标识,问题的答案一般会用斜体来标识
最后一句话
因为本人英文水平有限,有些话翻译得可能很别扭,有能力的话建议大家去看原网址。

实验是什么 What is an experiment?
“实验”这个术语经常被用来描述包括收集数据的任何情况。我经常听到学生,甚至更有经验的研究人员,把各种不同的研究情况描述为“实验性”,而事实上他们不应该这样做。例如,研究人员可以使用一组参与者的两种新型有氧健康测试来收集生理数据,然后将这两个时间点的得分关联起来,以确定新程序的重测信度。这不是一个实验。再举一个例子。假设你想从一些不同的动机测量来预测对锻炼计划的依从性。您可以让参与者在计划开始时完成对动机变量的问卷调查,然后使用回归分析来确定其对日后遵守计划的影响。这也不是一个实验。本课将告诉你为什么。
设计与分析 Design and analysis
从一开始就认识到,虽然在你的学位课程的第二年,我们分别教授研究设计和统计,但实际上它们是同一枚硬币的两面。 即使设计良好的研究,您也需要分析数据以确定任何变化、差异或关系在统计上是否显着。 相反,世界上所有的统计都不能帮助你从一个设计不好的研究中得出有效的结论。 在规划和设计一项研究时,要牢记如何分析获得的数据是至关重要的。 我忘记了最后一年的项目学生来帮我分析他们的数据的次数,只是失望地发现他们不能回答他们打算的问题,因为这个研究没有被正确设计。 设计和分析之间的关系也将在本课中进行说明。
因果关系 Causation
首先,我们来考虑一下实验的目的。回想一下关于科学本质的前一课。我们在那里了解到,科学的一个主要目标(许多人会认为最终的目标)是确定什么导致了什么。如果我们知道什么原因会发生,那么我们可以介入(或者不会发生,如果这是我们想要的)。例如,如果我们知道什么原因导致肌肉浪费在类风湿关节炎患者身上,我们可以进行干预来预防它;如果我们知道什么原因导致运动员对竞争情况更有信心,我们可以实施一个培训计划来帮助他们保持信心,等等。
所以我们要做的就是评估这个简单的命题:If X, then Y
换句话说,如果给予这个治疗(X),那么这个结果(Y)应该发生。然而,只通过实施治疗之后的结果变化是不足以证明X实际上导致Y的。除治疗外,可能还有许多其他原因导致Y的变化。假设我们想知道一个心理训练计划是否导致运动员竞争状态焦虑的减少。我们派出一批运动员参加该项目,并在训练期间和之后的比赛中评估他们的焦虑情绪。我们观察到的任何焦虑减轻可能是由于其他因素造成的。参与者可能只是习惯于通过在培训期间参加的活动中获得的经验来应对竞争压力。
为了确定它确实是X导致Y而不是别的,我们必须同时测试两个命题:
If X, then Y 和 If not X, then not Y
因此,如果我们有两组运动员,其中一组接受了心理训练,另一组则没有,我们发现只有训练组的成员表现出焦虑减少(或者比没有治疗组减少更多)那么我们可以得出这样的结论,那就是这个计划导致了这些结果上的差异。这样可以吗?假设我们的心理训练组的运动员在训练期间有很多比赛,而没有处理的运动员只有几个。这可能仍然是比赛的经验,导致焦虑减少,而不是培训计划。或者,假设我们已经将更多的经验丰富的运动员分配给了训练组,而没有经验的运动员分配给了未处理组。开始的时候,更有经验的运动员可能已经具备了更多的精神技能,并且不太担心竞争事件。因此,为了得出治疗(X)导致结果(Y)的结论,我们还必须确保在该项目过程之前或过程中对Y的操作没有其他影响。我们必须把X的影响与其他潜在的影响分离开来。
那么,我们如何确定X实际上导致了Y?那么,为了确定因果关系,必须满足三个条件。我把这三个步骤称为因果关系:
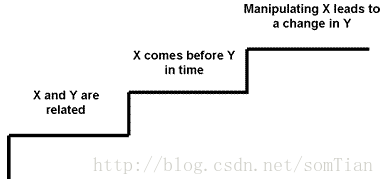
第一步是证明因果关系的一个必要但不充分的条件。 如果X导致Y那么显然他们必须是相关的。 如果吸烟导致癌症,那么吸烟必须与癌症有关。 但是,仅仅因为两件事情是相关的,所以并不意味着一件事导致另一件事。 你应该已经在统计中遇到了这个想法。 统计上,我们可以通过关联来确定两件事是否相关。 但是,相关性本身不能确定因果关系。 如果X和Y是相关的,那么X可能会导致Y,但是同样的,Y可能导致X.或者,X和Y只是相互关联的,因为它们都是由别的东西(Z)引起的。 这被称为虚假关联(spurious correlation):
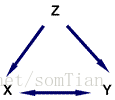
例如,鞋子大小(X)和语言技能(Y)在儿童中高度相关。 这并不意味着大脚会导致孩子更熟练。 两者都是由相同的因素造成的,我们可以称之为成熟(Z)。
第二步也是证明因果关系的一个必要但不充分的条件。在我们对宇宙的正常经验中,我们并不期望效应在其原因之前出现。如果我们发现X在时间Y之前,至少我们可以排除Y引起X的另一种假设。所以虽然这个步骤不能确定因果关系,但它确实使我们更接近于确定X引起Y.为此在两个时间点收集数据的纵向设计的原因通常比横截面设计更强,在这种设计中,所有数据都是在同一时间点收集的。
因果关系的最后一步涉及实验。我们操纵(或改变)X,以便看看我们是否在Y中得到了一个改变。通过你的统计训练,你将知道在这种情况下,X被称为自变量,Y被称为因变量(因为值Y的水平取决于X的水平)。
实验操作 Experimental manipulation
术语“实验”可以定义如下:
An experiment is a study in which at least one variable is manipulated and units are randomly assigned to the different levels of the manipulated variable(s). Pedhazur & Schmelkin (1991)
从这个定义中,我们可以看到有两个重要的条件必须满足,才能把研究称为实验。 第一个条件是我们必须操纵至少一个独立变量来创建不同的情境。 正如在上面的心理训练例子中,我们可以给参与者分配两个条件之一:一个接受该程序的治疗组和一个没有接受该程序的无治疗(控制)组。 因此,独立变量(治疗)通过创建两个情境来操纵:接受治疗而不接受治疗。
随机分配 Random assignment
其次,我们必须确保这些群组之间没有系统的差异,否则可能导致治疗的结果发生变化。 换言之,我们希望这两个群体对于结果的任何影响,除了他们是否接受治疗之外,都是等同的。 通过这样做,我们可以将治疗的效果与其他任何潜在的影响结果隔离开来。 这样的其他影响被称为潜在的独立变量,因为它们是可能导致结果变化的因素。 这种“滋扰”变量的另一个术语是混淆变量( confounding variables),因为它们混淆了研究中的结论。
我们通常通过随机分配参与者(上述定义中的 units)到不同的治疗条件(自变量)来实现组的等价。 我们的运动员样本必然会在很多方面发生变化:一些运动员会比其他运动员更有经验,有些运动员会参加更多的比赛,自然而然地不易焦虑,更聪明,有更好的辅导支持等等。 所有这些因素都可能影响结果。 通过随机分配运动员到两组,我们可以确保他们在这些因素方面上基本等同。
请注意,我只是说“基本等同”。事实上,随机分配到不同组的两个(或更多)个人组在所有方面不可能都是完全相同的。当随机分配时,我们依赖于由于概率规律的假设,个体之间的任何差异将是均匀的。因此,通过随机分配获得的组被称为概率等价(probabilistically equivalent)。换句话说,他们在概率上是相似的。团队的相似和随机化过程相当。当然,在小样本情况下,这可能是纯粹偶然的,两组之间有区别的可能性更大。因此,只要有可能,使用随机化来分配组是一个好主意。你可以通过测量这些变量来进行测试,然后测试一下这些组是否与它们有显着不同。例如,假设年龄在一项研究中可能是一个混杂的变量。你可以很容易地检查研究组的平均年龄有没有显着差异。
然后,操纵自变量和随机分配组是实验的关键特征。 没有这两个特征的研究都不是一个实验。 在本课第一段给出的例子中,没有操作变量,也没有随机分配给组。 这就是为什么这些研究不是实验。
一个真正的实验涉及操纵自变量,同时保持所有其他潜在的自变量不变,并随机分配到自变量的不同组。
任何其他类型的研究不是一个实验!
回想一下之前的抽样课程,我们需要区分随机分配到组和样本的随机选择。 对群体进行随机化并不意味着你有一个代表你感兴趣的人群的样本。为了对群体做出有效的推断,你仍然需要获得一个有代表性的样本。
准实验 Quasi-experiments
虽然真正的实验是确定因果关系的标准方法,但不幸的是,直接操纵自变量或随机分配参与者到不同的群组并不总是可能的。 没有人进行真正的实验来证明吸烟会导致人类癌症。 原因很明显, 你不能随意指定人吸烟二十年,然后看看你的吸烟组是否有较高的癌症发病率。 同样,人的一些属性是固定的,不能被操纵。 如果我们对性别对某些结果的影响,我们不能随意分配个人为男性或女性。
这并不意味着我们不能解决这些问题。 我们仍然可以通过使用所谓的准实验设计来将真实实验的原理应用于这些情况:
A quasi-experiment has all the elements of an experiment, except that subjects are not randomly assigned to groups. Pedhazur & Schmelkin (1991)
在一个准实验中,自变量不是由调查者直接操纵的。 相反,自变量在某种程度上是自然发生的,或者已经通过一些超出研究者控制的过程而发生了变化。 例如,假设我们研究不同性别的肌肉损伤的差异。 尽管我们不能随机分配男性和女性的参与者,但我们仍然可以比较男性和女性对肌肉损伤的反应。 这被称为非等组设计,并且被广泛使用。 这个设计的主要问题在于,由于这些群体是非等价的,除了自变量之外,它们在很多方面都会有所不同。 因此,在因变量中观察到的任何差异都可能是由于这些其他潜在的自变量。 我们可以尽量减少,但不能完全消除此问题。
另一个常见的准实验设计被称为断点回归(regression-discontinuity) 设计,或者更简单地说是截断设计。这涉及根据他们在预处理变量上的分数给参与者分组。例如,您可能想要比较治疗对个体焦虑高或低的影响。您首先要测量他们的特质焦虑,然后根据预定的截止点将参与者分配到高和低组。通常使用中值分割程序。首先计算截止变量上总样本的中位数。然后,将所有那些得分低于中位数的参与者分配给“低”组,将那些得分高于中位数的得分分配给“高”组。问题在于,如果分数正常分布(应该是这样),大多数人都会在中位数附近得分。所以,你只是把那些刚刚高于中值“高”的那些和那些刚刚低于中值“低”的那些称作实际上相当平均的那些。另一种方法是采取更多的极端截断,分数分布的顶部和底部三分之一,并从研究中消除中间的分数。那么问题是,你必须丢弃大量的数据,你会收集相当大的麻烦。
对于断点回归,这里有个讲解更透彻的例子:如果我们想知道上“一本”是否对学生未来工资有影响,使用RD方法,就是观察那些在一本线上下2分的学生,看“上一本”和“没上一本”的学生的未来工资差异。这个想法的天才之处在于,高考的上下5分,实在是一件随机性非常大的事情。让这批学生重新考一次,不少学生的情况可能就要逆转。对于这5分区间内的学生来说,一条一本线,就像一个天然的分割线,将两组人随机分开了。
设计符号 Design notation
坎贝尔和斯坦利(Campbell and Stanley,1963)引入了一个简单的符号系统来描述不同类型的设计,我们将在下一节中使用。
观察 Observations
观察或测量由O表示。下标用于表示特定的测量时机(例如O1,O2)
操纵变量 Treatments
自变量(治疗,操作,干预,训练程序或任何你要操纵的事情)都由X表示。在同一研究中的不同治疗由下标表示(例如X1, X2)。 一个没有治疗的条件空白表所示。
群组 Groups
不同小组在不同的行。 连续的X和O适用于同一组。 例如,有两组,将会有两行。
分配组 Assignment to groups
随机分配由R表示。非等价组由N表示;;截止分配的组由C表示
时间 Time
从左到右的维度表示时间顺序。 例如,O1 X O2表示观察,治疗,然后是第二次观察。
设计类型 Types of design
基本上有三类设计:实验,准实验和预实验(有时称为非实验)。 以下决策树可以帮助您确定在研究中使用哪种类型的设计:

现在我们来看看这些不同设计分类的一些具体例子。 这些设计代表了基本应用; 他们有更复杂的变化。 我们将在下一课中继续研究主要设计的具体优缺点。
预实验设计 Pre-experimental designs
1. 案例研究 One shot case study (posttest only design)
所有的最简单的设计,案例研究可以用我们的符号系统来描述:
X−−−−−−−−−−−−O
我们只有一组参与者,给他们一个治疗(操纵自变量),然后测量其(所谓的)效果。 例如,我们可能会给一些群体增加体力活动的动机,然后衡量他们的锻炼量。 这种设计在证明治疗的因果效应方面的弱点应该是显而易见的。 由于我们没有衡量参与者在治疗前做了多少锻炼,我们怎么能说出治疗是否导致了改变? 而且,如果他们没有接受治疗,我们不知道他们可能做了多少活动。
这并不是说这样的设计毫无用处。 假设你对英格兰退出世界杯决赛对人们情绪状态的影响感兴趣。 事件发生后,通过访问个人可以获得有关人们情绪的有用信息。 但是你不能从数据中得出任何的因果影响。 你不能确定这是英格兰退出,而不是其他因素,决定了样本的情绪状态。
2.单组,前测,后测 Single group, pretest, posttest design
O1−−−−−−−−−−−−X−−−−−−−−−−−−−O2
有了这个设计,我们可以确定治疗和因变量一起变化。 但是,我们仍然不知道是不是治疗导致了变化,为什么不是其他因素,因为我们不知道没有治疗,效果是否会改变。 在这里,我们正在测试最早提出命题,如果X那么Y,而不是另一半:如果不
这篇关于科学研究设计五:实验设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








