本文主要是介绍对话生成方法中的“共鸣”,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天推荐的是一篇对话生成方向的论文(Empathetic Dialogue Generation via Sensitive Emotion Recognition and Sensible Knowledge Selection),论文将对话过程中用户的情感变化考虑进去,从而可以给用户一种“共鸣”的感觉,针对其不同的情感回复更加贴合其情绪的文本,构造更加人性化的对话系统。感觉是一个不错的出发点,非常贴合实际场景,论文的代码逻辑性也是非常强,喜欢这篇论文的话推荐阅读源码
【摘要】
目前的对话生成方法首先把情感作为单一的静态变量对待,忽视了对话过程中情感的变化,无法产生共鸣,其次,在引入外部知识的时候,没有综合考虑知识和情感之间的一种协调,导致两者可能存在冲突现象。本文提出情感和知识交互的方法(Serial Encoding and Emotion-Knowledge interaction ,SEEK )以提高对话生成的质量。
论文:2210.11715v2.pdf (arxiv.org)
代码:https://github.com/wlr737/emnlp2022-seek
【引言】
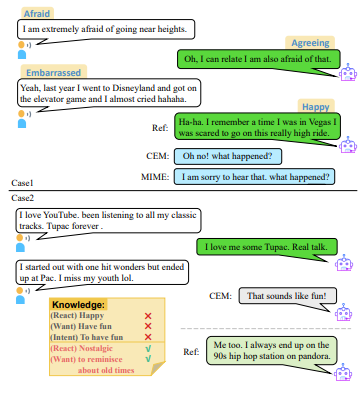
共鸣是对话中至关重要的一点,在对话过程中交互双方产生共鸣有利于对话朝着更好的方向发展。对话系统的关键一点为理解用户的情绪变化,并给出合理的回复。之前的研究者也着力于提高对话系统的共鸣能力,有的采取获取对话中的情绪信息,有的加入共鸣知识。但是目前的方法都是获取对话级别情感,忽略了对话过程中情绪的动态变化。如下图中,用户的情绪从“害怕”转移到“尴尬”。因此本文为了获得对话过程中的情感变化,使用的是utterance-level的编码策略(之前研究者获得的是整个对话文本的情感),其可以获得对话过程中用户的情感变化,在此基础上,提出emotion-intent识别任务,以更好的获得情感变化,为了解决知识和情感之间产生冲突的问题,本文设计了一个两者双向可以交互的框架。
【模型】
为了获得对话过程中的情感变化,设计了几个子任务:每一个对话的情感识别、基于回复的情感意图预测、整个对话的情感识别。在这三个子任务中需要得到对话的编码和知识的编码,以及将这两者进行融合。为了生成回复,需要将融合的对话信息筛选知识,再进入解码器得到回复内容。因此,模型主要过程包括对话编码器、知识编码器、融合对话和知识、选择知识。
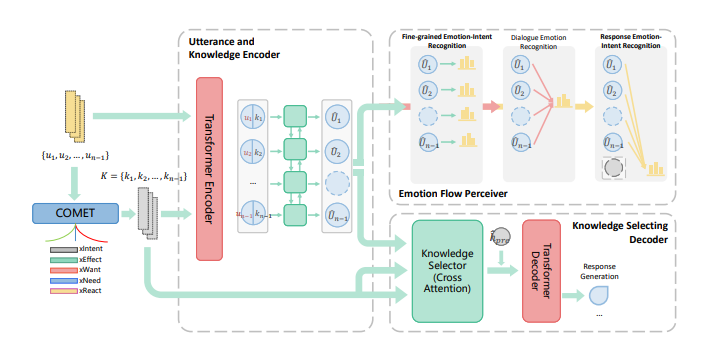
1、对话编码器:使用transformer编码,使用cls的输出。
此步将整个对话内容的每一个对话使用transformer的encoder进行编码。并使用其CLS对应的输出作为对话表示。
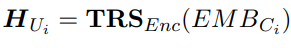
2、知识编码器:COMET+transformer
使用针对情感的预训练模型COMET对5种类型(人的效果(xEffect),说话人的影响(xReact),说话人之前的意图(xIntent),说话人当前意图(xNeed),说话人之后意图(xWant))的知识进行生成,然后再使用上面的transformer得到表示,此步使用平均池化得到最终的知识表示。
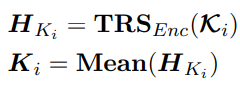
3、融合对话和知识:拼接对话表示和知识表示,输入双层lstm得到。
首先使用lstm得到融合知识和对话的表示,并采用3个损失来使其获得情感变化。
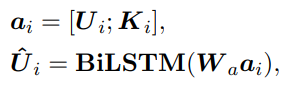
(1)每个对话的情感识别
上述结果进入softmax分类计算交叉熵。

(2)基于回复的情感意图预测
计算所有对话的attention,加权进入softmax,和最后一个对话的情感类别计算交叉熵。
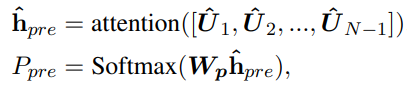
(3)整个对话的情感识别
计算所有对话的attention,加权进入softmax,和整个对话的情感计算交叉熵。
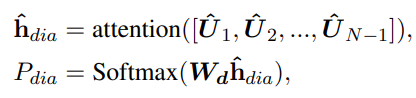
3、选择知识
使用上面lstm的结果作为Q,知识的结果作为K、V,使用transfomer的交叉attention计算,最后经过一个pooling操作,然后和基于回复的预测进行拼接,作为decoder的第一个字符表示。训练的的时候直接作为正确标签的第一个字符,预测的时候,decoder的第一个输入就是这个表示。
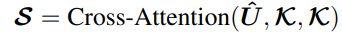
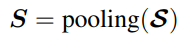
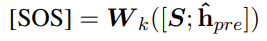
5、总体损失函数
前面三个交叉熵损失,加最后一个普通的生成的损失(交叉熵损失)和使用Frequency-Aware CrossEntropy (FACE)的损失,这个FACE是为了避免重复生成相同字符的改进版的交叉熵损失函数。其通过之前生成的词的频率作为原始交叉熵的一个权重实现这个过程,以得到多样性较强的生成结果。
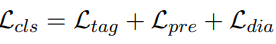
【实验】
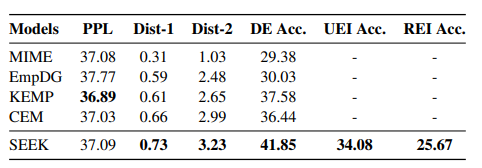
1、和其他模型的对比结果
2、人类A/B测试(%)在连贯性,共情和流利性上的对比结果
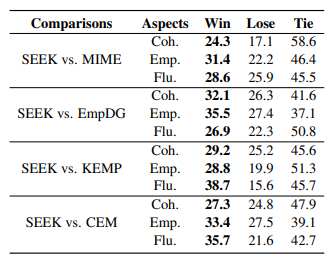
3、case分析结果
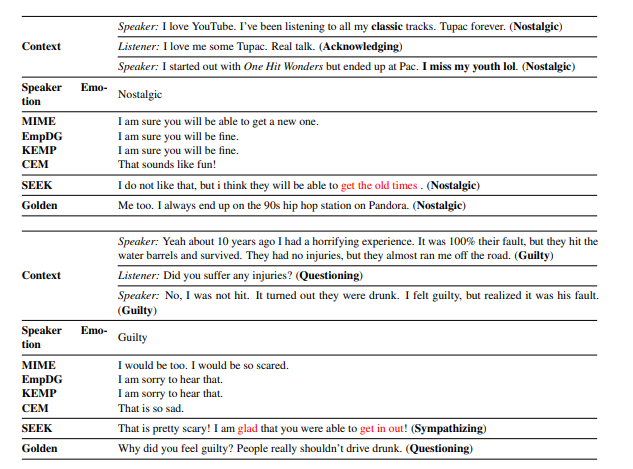
这篇关于对话生成方法中的“共鸣”的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




