本文主要是介绍基于R语言的NDVI的Sen-MK趋势检验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本实验拟分析艾比湖地区2010年至2020年间的NDVI数据,数据从MODIS遥感影像中提取的NDVI值,在GEE遥感云平台上将影像数据下载下来。代码如下:
import ee
import geemap
geemap.set_proxy(port=7890)# 设置全局网络代理
Map = geemap.Map()# 指定艾比湖地区数据范围
region = ee.Geometry.BBox(82.433,44.367,84.5,45.267)def get_mean_ndvi(year):y1,y2 = f'{year}-01-01', f'{year+1}-01-01'ndvi_collection = (ee.ImageCollection('MODIS/MCD43A4_006_NDVI') .filterDate(y1,y2) .filterBounds(region))ndvi = ndvi_collection.reduce(ee.Reducer.mean())geemap.ee_export_image_to_drive(ndvi, description=f'ndvi{year}', folder='image',scale=1000,region=region)for y in range(2010,2021):get_mean_ndvi(y)
影像会下载到Google云盘中,通过手动下载到本地,其根目录结构如下:
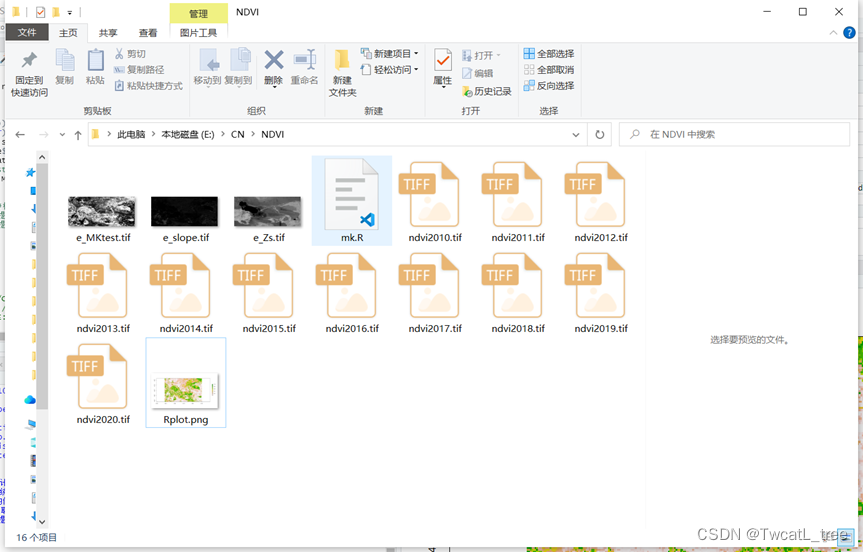
图1 根目录结构
下载该10年间的数据后,打开RStdio并导入将趋势检验中将使用的R包。代码如下:
library(sp)
library(raster)
library(rgdal)
library(trend)setwd('E:/CN/NDVI')
fl <- list.files(pattern = '*tif$')
firs <- raster(fl[1])for (i in 1:10) {r <- raster(fl[i])firs <- stack(firs, r)
}fun <- function(y){if(length(na.omit(y)) <10) return(c(NA, NA, NA)) #删除数据不连续含有NA的像元av <- mean(y,na.rm=T)MK_estimate <- sens.slope(ts(na.omit(y), start = 2010, end = 2020, frequency = 1), conf.level = 0.95) #Sen斜率估计slope <- MK_estimate$estimateMK_test <- MK_estimate$p.value
# Zs <- MK_estimate$statisticreturn(c(av, slope, MK_test))
}e <- calc(firs, fun) #栅格计算
#e_Zs <- subset(e,1) #提取Z统计量
e_mean <- subset(e,1) #提取均值图层
e_slope <- subset(e,2) #提取sen斜率
e_MKtest <- subset(e,3) #提取p值plot(e_mean)
plot(e_slope)
plot(e_MKtest)writeRaster(e_mean, "E:/CN/NDVI/e_Zs.tif", format="GTiff", overwrite=T)
writeRaster(e_slope, "E:/CN/NDVI/e_slope.tif", format="GTiff", overwrite=T)
writeRaster(e_MKtest, "E:/CN/NDVI/e_MKtest.tif", format="GTiff", overwrite=T)
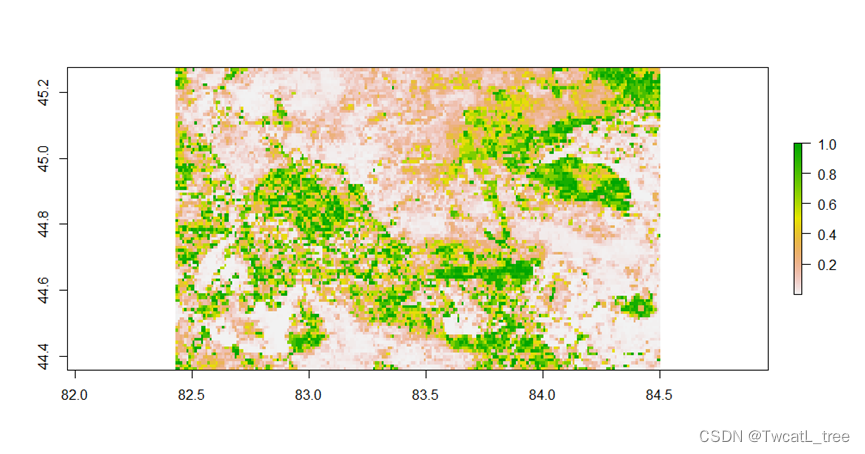
图2 2010-2020年间艾比湖地区NDVI均值图层
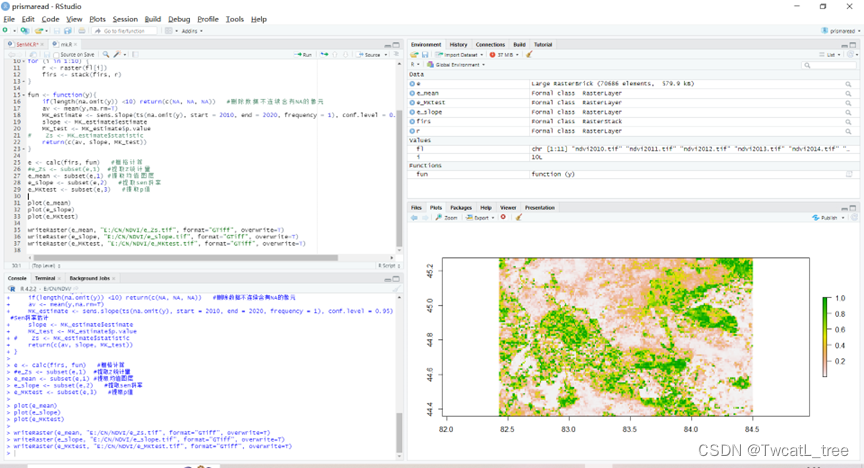
图3 R语言运行界面
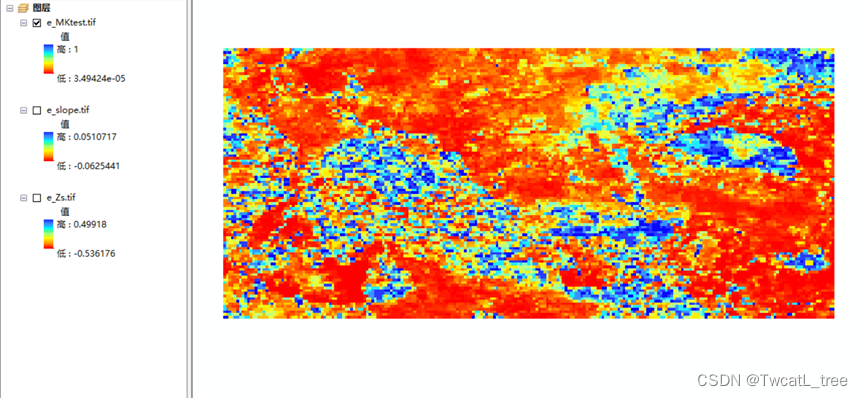
图4 p值
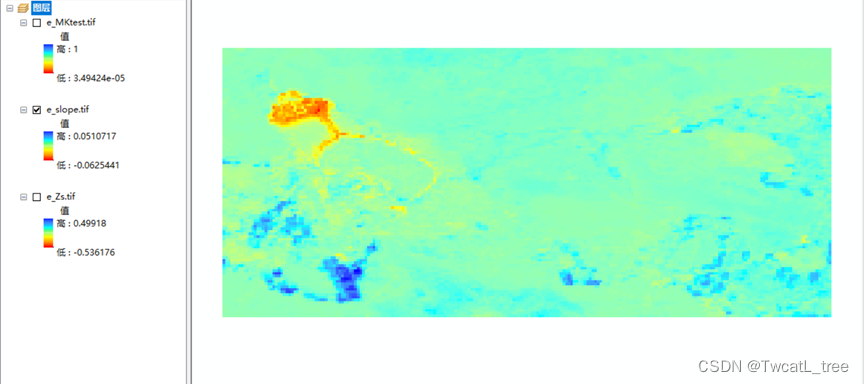
图5 sen斜率
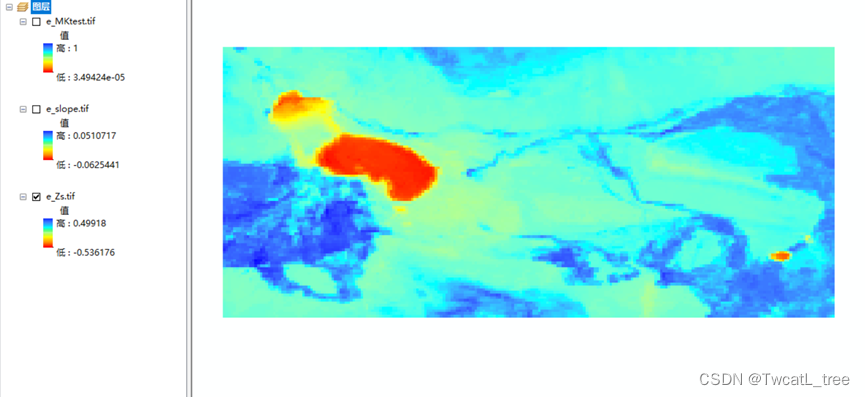
图6 Z统计量
R语言计算完slope和Z值后,根据这两个结果就可以进行NDVI趋势制图了。
一、变化趋势划分
结合SNDVI和Z统计量划分NDVI变化趋势:
1、slope
-0.0005~0.0005稳定区域
大于或等于0.0005植被改善区域
小于-0.0005为植被退化区域
2、Z统计量
二、Slope划分
置信水平0.05
Z绝对值大于1.96显著
Z绝对值小于等于1.96不显著
Slope被划分为三级:
SNDVI≤−0.0005 植被退化
−0.0005≥SNDVI≥0.0005 植被生长稳定
SNDVI≥0.0005 植被改善
使用重分类(Reclassify)对slope进行划分
由于slope.tif文件研究区范围外的值非空,所以在这里先裁剪了一下
裁剪所用矢量和栅格数据坐标系需要一致,否则范围容易出错
统一使用了WGS84地理坐标系作为空间参考
使用Model builder构建地理处理流
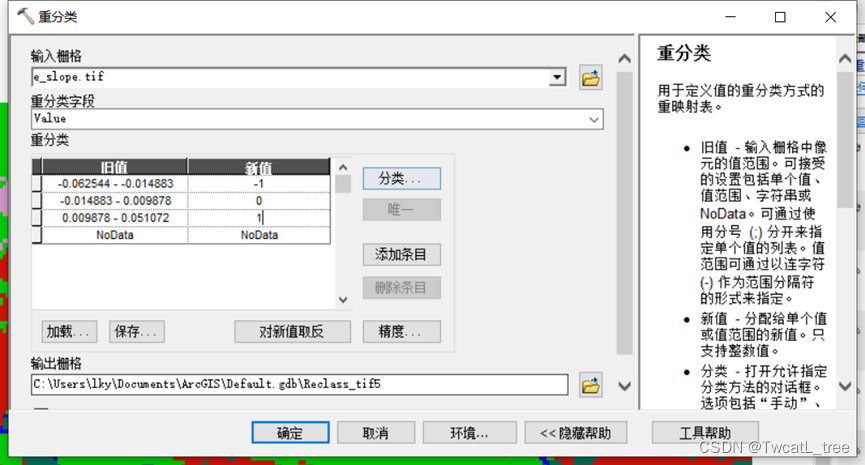
图7 重分类
三、Slope划分过程
重分类结果:
-1退化
0稳定
1改善
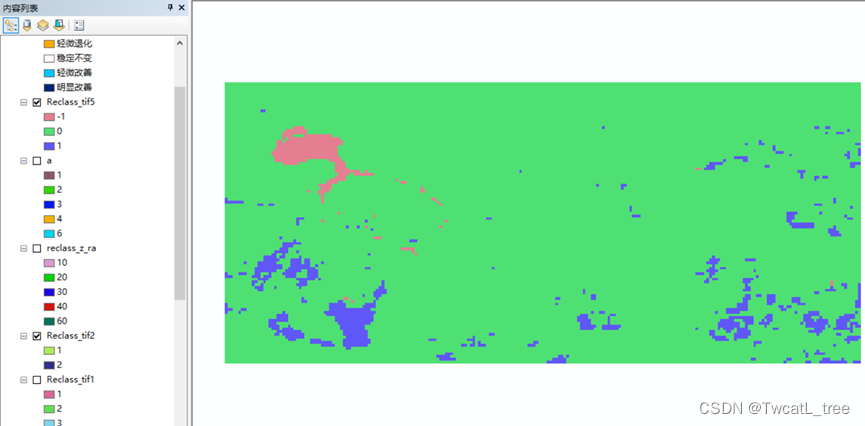
图8 重分类结果
四、Z值划分
对Z值进行重分类,确定显著性
|Zs|≤0.196 未通过95%置信度检验,不显著
|Zs|≥0.196 通过95%置信度检验,显著

图9 重分类
五、Z值重分类
重分类结果:
1不显著
2显著

图10 重分类结果
六、变化趋势计算
使用栅格计算器将Slope和Z值计算结果相乘,最后得到趋势变化划分
-2严重退化
-1轻微退化
0稳定不变
1轻微改善
2明显改善

图11 栅格计算器相乘

图12 arcgis计算NDVI趋势图
这篇关于基于R语言的NDVI的Sen-MK趋势检验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


