本文主要是介绍用pycharm使用恒源云服务器的傻瓜操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前情提要:本来用的是学校的服务器,但是不够用了所以转战云服务器,花钱办事。第一次用外面的服务器,摸索前进。恒源云_GPUSHARE-恒源智享云恒源智享云gpushare.com 是一个专注 AI 行业的共享算力平台,旨在为用户提供高性比价的GPU云主机和存储服务,让用户拥有高效的云端编程和训练体验,不再担忧硬件迭代/环境搭建/数据存储等一系列问题。![]() https://www.gpushare.com/
https://www.gpushare.com/
目录
1.注册
2.上传数据集
3.租卡
4.远程连接服务器
1.注册
注册恒源云账号,此处建议用个方便的密码,因为有很多时候要输入。

2.上传数据集
2.1前面租好实例之后就可以点进我的数据--oss存储先把自己数据集上传。先把数据集整理成压缩包。
2.2按照上传的操作指引操作。先下载oss命令,安装好后点开。输入login,按照指示输入用户名和密码,登录成功。
Input your command:
login
Username:1231231234
Password:***************
1231231234 login successfully!创建文件夹存放你的数据集,输入mkdir oss://dataset,就创建成功个人文件夹。
mkdir oss://dataset
Create folder [oss://] successfully, request id [00000184469F5F33901067C07D811111]
Create folder [oss://dataset/] successfully, request id [00000184469F5F7D90106817B7911111]从本地设备复制你的数据集到个人文件夹。输入cp C:\aaa\dataset\iaaa.7z oss://datasets/(C:\aaa\dataset\iaaa.7z是你的数据集压缩包本地存放的地址)
Input your command:
-->cp C:\aaa\dataset\iaaa.7z oss://datasets/
Start at 2022-10-05 07:47:06.0895598 +0000 UTCParallel: 5 Jobs: 5
Threshold: 50.00MB PartSize: auto
VerifyLength: false VerifyMd5: false
CheckpointDir: C:\Users\Lenovo\.hycloud_ossutil_checkpoint[--------------------------------] 100.00% 1.38MB/s 820.44MB/820.44MB 9m56.133s
Waiting for the uploaded key to be completed on server side.Upload successfully, 820.44MB, n/a, C:\aaa\dataset\iaaa.7z --> oss://datasets/iaaa.7z, cost [597256], status [200], request id [0000018446CB0CCC9011CC75BE111111]检查个人文件夹里是否成功上传了数据集,输入ls -s -d oss://datasets/,出现如下反馈则是成功。
Input your command:
-->ls -s -d oss://datasets/
Start at 2022-10-05 07:59:54.1815603 +0000 UTCListing objects .Folder list:
oss://datasets/Object list:
oss://datasets/iaaa.7zFolder number is: 1
File number is: 13.租卡
3.1点进我的实例--创建实例,选择喜欢的显卡。注意要对自己的模型要用的内存有个大概的估计,显存不要选少了。

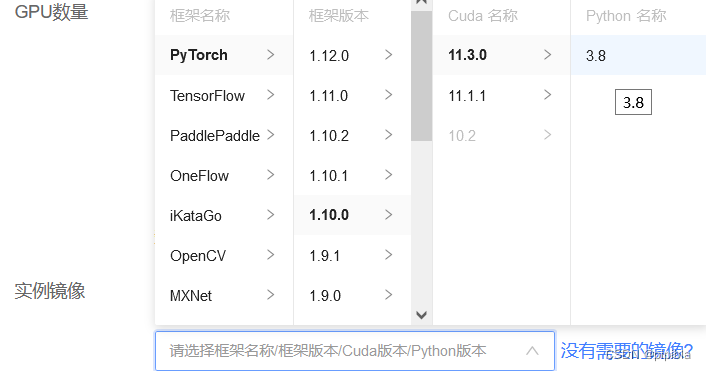
3.2实例镜像按照自己的需求选,选好之后我们的base环境里就直接给你搭好了不用自己创建。
3.3按照自己的计划选择是按小时付费、包日、包月还是包年。我第一次用先浅浅一试按小时。
4.远程连接服务器
4.1实例创建好之后是自动打开的,可以用本地的编译器或者平台提供的jupyterlab上进入实例,跑你的代码。我用习惯了pycharm,所以我接下来会将pycharm连上云服务器,用jupyterlab将个人文件夹里的数据集复制到实例文件夹中(也可以在连好的pycharm的ssh终端移动文件夹)。
4.2移动数据集到实例文件夹。我们点击实例与数据--我的实例,然后在快捷工具那里点进jupyterlab,点击terminal,就能直接进入实例中。此时右侧导航栏就是实例的目录,找到hy-tmp文件夹,那里就是存放我们的代码和数据集的地方。
4.3在右侧编辑器中写oss login,先登录账号。再进入文件夹cd /hy-tmp,再写oss cp oss://datasets/iaaa.7z /hy-tmp(oss://datasets/iaaa.7z个人文件夹中存放数据集的位置,/hy-tmp是实例文件夹中我们想存放数据集的位置),回车执行从个人文件夹中复制压缩包到实例文件夹中的操作。
4.4参考这个链接,在pycharm连接云服务器。
pycharm远程连接服务器完整教程![]() https://blog.csdn.net/hehedadaq/article/details/118737855IP地址和用户名密码从我的实例的登录指令处获得。
https://blog.csdn.net/hehedadaq/article/details/118737855IP地址和用户名密码从我的实例的登录指令处获得。
![]()
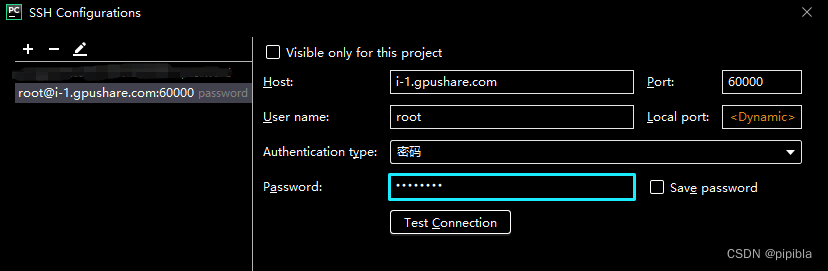
点击复制后把文本黏贴,得到下图。
60000是端口,root是用户名,密码在上图获得,i-1.gpushare.com是host
ssh -p 60000 root@i-1.gpushare.com在pycharm配置时云服务器信息的填写。在按照上面的步骤配置的时候我选择了不自动上传本地文件到服务器,我手动保存才上传,这保证了我不会浪费云服务器的空间。
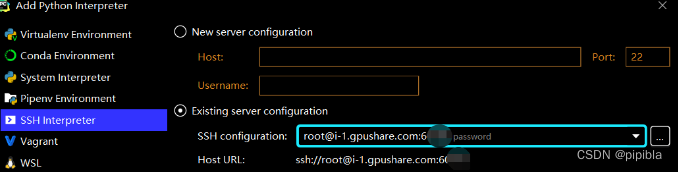
这里注意跟教程里不同的是!!配置解释器的时候要选择下图这个。
4.5 在pycharm配置好之后就可以点开ssh终端,安装一些我们要用到的包了。首先检查下有了什么包。
apt update #执行安装前必须执行该命令,更新远程仓库的元数据到本地
pip list # 列出这个base环境下已经安装的包,我们会发现在选择镜像的时候的配置已经配好了点开自己的工程看现在缺什么,补上。
pip install xxxx --no-cache #装我的代码要用的包
pip uninstall xxxx #卸载解压缩数据集iaaa.zip到hy-tmp文件夹里。
root@Iec5c5c61e0040000:~# cd /hy-tmp/ #进入目标文件夹
root@Iec5c5c61e00400000:/hy-tmp# 7z x iaaa.zip -o/hy-tmp #解压
7-Zip [64] 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21
p7zip Version 16.02 (locale=C.UTF-8,Utf16=on,HugeFiles=on,64 bits,80 CPUs Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz (50654),ASM,AES-NI)Scanning the drive for archives:
1 file, 833105551 bytes (795 MiB)Extracting archive: iaaa.zip
--
Path = iaaa.zip
Type = zip
Physical Size = 833105551Everything is Ok Folders: 4
Files: 4500
Size: 1003050000
Compressed: 833105551压缩文件夹可以用zip指令,把/home/111/222/333下的文件全部压缩成234.zip压缩包。
zip -q -r 234.zip /home/111/222/333其他很多指令可以参考。恒源云用户文档![]() https://gpushare.com/docs/getting-started/command/
https://gpushare.com/docs/getting-started/command/
# 解压 .tar.gz 文件到当前目录
~# tar -xf compress.tar.gz# 解压 .tar.gz 文件到 /hy-nas 目录
~# tar -C /hy-nas -xf compress.tar.gz# 将文件和文件夹压缩成 .tar.gz 文件
~# tar -zcf compress.tar.gz file directory# 解压 zip 或 rar 推荐使用 7z 命令,使用 apt 安装
~# apt-get update
~# apt-get install p7zip-full -y# 使用 unzip 解压 .zip 文件到当前目录
~# unzip -q compress.zip# 如果 zip 超过 1GB 推荐使用 7z 命令解压,-o 后直接加解压缩路径
~# 7z x compress.zip -o/hy-nas# 将文件和文件夹压缩成 .zip 文件
~# zip -q -r compress.zip file directory# 解压 .rar 文件到当前目录
~# 7z x compress.rar
4.6把包和数据集都搞定之后,别忘了更改代码里用到的绝对路径。接下来就自己自由发挥咯~不用时记得把服务器关机。
这篇关于用pycharm使用恒源云服务器的傻瓜操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





