本文主要是介绍案例分享 | Yelp 如何在 Kubernetes 上运行 Kafka(第 1 部分 - 架构),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

本文译自 Kafka on PaaSTA: Running Kafka on Kubernetes at Yelp (Part 1 - Architecture)[1]。作者:Lennart Rudolph
在 Yelp,Kafka 每天接收数百亿条消息来推进数据驱动并为关键业务管道和服务提供支持。我们最近通过在 PaaSTA (Yelp 自己的平台即服务)上运行集群,对 Kafka 部署架构进行一些改进。基于 K8s 的部署利用了 Kafka 的自定义 Kubernetes operator 以及用于生命周期管理的 Cruise Control 。

架构改进及动机
过去,我们所有的 Kafka 集群都在 AWS 的专用 EC2 实例上运行。Kafka 直接部署在这些主机上,配置管理高度依赖 Puppet 仓库。这种部署模式有些繁琐,创建一个新集群平均需要两个多小时。因此我们着手开发一种新的部署模型,以下是改进目标:
-
减少对 Puppet 缓慢运行的依赖。
-
在内部推广 PaaSTA ,并利用其 CLI 工具来提高生产力。
-
提高生命周期管理系统的可维护性。
-
简化执行操作系统主机升级和 Kafka 版本升级的过程。
-
简化新 Kafka 集群的创建(与我们部署服务的方式一致)。
-
加快代理退役,简化主机故障的恢复过程。拥有重新连接 EBS 卷的能力,避免不必要地网络资源消耗,节省资金。
Yelp 之前开发了在 Kubernetes 上运行有状态应用程序的实践(例如,Cassandra on PaaSTA and Flink on PaaSTA),因此 PaaSTA 是这个用例的自然选择。
新的部署架构利用 PaaSTA 池(或主机组)作为底层基础设施。Kafka 代理 pod 调度在 Kubernetes 节点上,并且代理 pod 具有可分离的 EBS 卷。新架构的两个关键组件是 Kafka operator 和 Cruise Control,后面会更详细地介绍这两者。我们在 PaaSTA 上部署了我们内部的 Kafka Kubernetes Operator 实例和各种 Sidecar 服务,并且每个 Kafka 集群的 PaaSTA 上也部署了一个 Cruise Control 实例。
新旧架构的两个关键区别是 Kafka 现在运行在 Docker 容器中,我们的配置管理方法不再依赖 Puppet。配置管理现在与基于 PaaSTA 的配置管理解决方案一致,在该解决方案中,只要 YAML 文件更改提交到服务配置存储库, Jenkins 就会传播这些变化。由于这次架构大修,我们才能够利用现有的 PaaSTA CLI 工具来查看集群的状态、读取日志并重新启动集群。另一个好处是,能够通过提供必要的配置(见下文)来部署新的 Kafka 集群,这种方法使我们配置新 Kafka 集群的时间减半。

PaaSTA 工具示例
example-test-prod:deploy_group: prod.everythingpool: kafkabrokers: 15cpus: 5.7 # CPU unit reservation breakdown: (5.7 (kafka) + 0.1 (hacheck) + 0.1 (sensu)) + 0.1 (kiam) = 6.0 (as an example, consider that our pool is comprised of m5.2xlarge instances)mem: 26Gidata: 910Gistorage_class: gp2cluster_type: examplecluster_name: test-produse_cruise_control: truecruise_control_port: 12345service_name: kafka-2-4-1zookeeper:cluster_name: test-prodchroot: kafka-example-test-prodcluster_type: kafka_example_testconfig:unclean.leader.election.enable: "false"reserved.broker.max.id: "2113929216"request.timeout.ms: "300001"replica.fetch.max.bytes: "10485760"offsets.topic.segment.bytes: "104857600"offsets.retention.minutes: "10080"offsets.load.buffer.size: "15728640"num.replica.fetchers: "3"num.network.threads: "5"num.io.threads: "5"min.insync.replicas: "2"message.max.bytes: "1000000"log.segment.bytes: "268435456"log.roll.jitter.hours: "1"log.roll.hours: "22"log.retention.hours: "24"log.message.timestamp.type: "LogAppendTime"log.message.format.version: "2.4-IV1"log.cleaner.enable: "true"log.cleaner.threads: "3"log.cleaner.dedupe.buffer.size: "536870912"inter.broker.protocol.version: "2.4-IV1"group.max.session.timeout.ms: "300000"delete.topic.enable: "true"default.replication.factor: "3"connections.max.idle.ms: "3600000"confluent.support.metrics.enable: "false"auto.create.topics.enable: "false"transactional.id.expiration.ms: "86400000"
运行 Kafka 2.4.1 版本的有 15 个代理的集群的示例配置文件
新架构详解
新架构的一个主要组件是 Kafka Kubernetes operator,它负责管理 Kafka 集群的状态。虽然我们仍然依赖外部 ZooKeeper 集群来维护集群元数据,但消息数据仍然保存在 Kafka 代理的磁盘中。由于 Kafka 用户依赖持久存储来检索数据,在 Kubernetes 中,Kafka 被认为是一个有状态的应用程序。Kubernetes 公开了用于管理有状态应用程序的工作负载 API 对象 。
(例如 StatefulSets ),但 Kubernetes 默认没有 Kafka-specific 结构。因此,需要标准 Kubernetes API 之外的其他功能来维护我们的实例。用 Kubernetes 的说法,operator 是一个自定义控制器,它允许我们公开这种特定的应用功能。
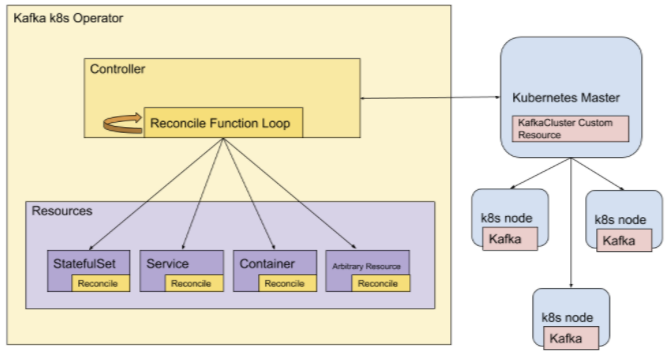
Operator 负责确定 Kubernetes 需要对集群执行操作的时间。它有一个协调循环,观察自定义集群资源的状态,并通过与 Kubernetes API 交互以及调用另一个关键架构组件 Cruise Control 公开的 API 来协调差异。
Cruise Control 是 LinkedIn 开发的开源 Kafka 集群管理系统。目标是减少与维护大型 Kafka 集群的开销。每个 Kafka 集群都有自己专用的 Cruise Control 实例,每个集群的 Operator 与其 Cruise Control 实例交互以执行生命周期管理操作,如检查集群的健康状况、重新平衡主题分区和添加/删除代理。
Cruise Control 使用的范式在许多方面与 operator 使用的范式相似。Cruise Control 监控 Kafka 集群的状态,生成一个内部模型,扫描异常目标,并尝试解决异常问题。它公开了用于各种管理任务和上述生命周期管理操作的 API 。这些 API 可替代我们之前的临时生命周期管理实现,我们使用 EC2 支持的代理来执行条件性再平衡操作或与 SNS 和 SQS 等 AWS 资源进行互动,将这些整合到一项服务中帮助简化生命周期管理栈。

集群架构
将这些组件放在一起就形成了一个集群架构,我们通过内部配置管理系统定义了一个 CRD,并将其与自定义 Kafka Docker 镜像结合起来。Kafka Kubernetes operator 在与 Kubernetes API 的交互中使用配置、CRD 和 Docker 镜像 ,在 Kubernetes 主服务器上生成 KafkaCluster 自定义资源,因此可以在 Kubernetes 节点上调度 Kafka pod,operator 通过 Kubernetes API 和 Cruise Control 服务公开的 API 来监督和维护集群的健康状况。我们可以通过 Cruise Control UI 或 PaaSTA CLI 工具观察集群并与之交互。
最后,通过一个示例场景来说明整个操作流程。考虑通过删除代理来缩小集群规模的情况。一个开发者更新集群的配置并减少代理的数量,从而更新 Kafka 集群的 CRD。作为协调循环的一部分,operator 认识到期望的集群状态与 StatefulSet 中表示的实际状态不同,所以它要求 Cruise Control 删除代理,Cruise Control API 返回有关删除任务的信息,operator 使用这个任务的元数据注释退役 pod。当 Cruise Control 执行将分区从代理移开的过程,operator 会通过向 Cruise Control 发出请求来例行检查停用的状态。一旦任务被标记为已完成,operator 将移除 pod ,集群规范的内部状态就被调和了。
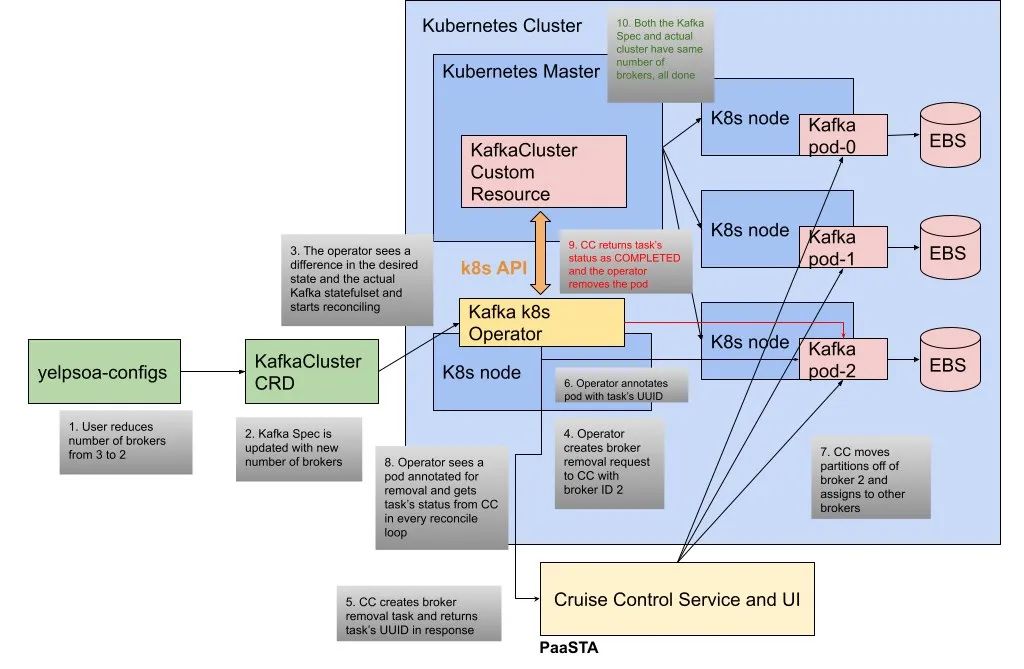
缩小规模的方案
架构设计好后,我们会做什么?
在设计了这个架构之后,我们构建了一个将 Kafka 集群从 EC2 无缝迁移到 PaaSTA 的流程。截止目前,我们已经将许多集群迁移到 PaaSTA,并使用新架构部署了新集群。我们还在继续调整硬件选择,以适应集群的不同属性。
下一篇会分享我们将现有 Kafka 集群从EC2无缝迁移到基于Kubernetes的内部计算平台的策略。
引用链接
[1]
原文链接: https://engineeringblog.yelp.com/2021/12/kafka-on-paasta-part-one.html
这篇关于案例分享 | Yelp 如何在 Kubernetes 上运行 Kafka(第 1 部分 - 架构)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





