本文主要是介绍AWS 专题学习 P3 (RDS、Aurora、ElastiCache),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. Amazon RDS Overview
- RDS v.s. 在 EC2 上部署数据库
- RDS — Storage Auto Scaling
- RDS Read Replicas
- Read Scalability
- Use Cases
- Network Cost
- RDS 多可用区(灾难恢复)
- RDS — 从单可用区到多可用区
- RDS Custom
- 2. Amazon Aurora
- Aurora 高可用性和只读扩展
- Aurora 数据库集群
- Aurora 的特点
- Aurora Replicas - Auto Scaling
- Aurora – 自定义端点
- Aurora Serverless
- Aurora Multi-Master
- Global Aurora
- Aurora 机器学习
- 3. Backups
- RDS 备份
- Aurora 备份
- RDS 和 Aurora 还原选项
- Aurora 数据库克隆
- 4. RDS & Aurora Security
- 5. Amazon RDS Proxy
- 6. Amazon Elasticache
- 概述
- ElastiCache 解决方案架构 - DB缓存
- ElastiCache 解决方案架构 - 用户会话存储
- ElastiCache - Redis vs Memcach
- Elasticache - 缓存安全性
- Patterns for ElastiCache
- Elasticache - Redis用例
1. Amazon RDS Overview
- RDS 代表关系型数据库服务
- 它是一种托管数据库服务,用于使用SQL 作为查询语言的数据库。
- 它允许您在云中创建由 AWS 管理的数据库
- Postgres
- MySQL
- MariaDB
- Oracle
- Microsoft SQL Server
- Aurora(AWS 专有数据库)
RDS v.s. 在 EC2 上部署数据库
- RDS 是一项托管服务:
- 自动配置、操作系统修补
- 持续备份和恢复到指定时间戳(时间点恢复)
- 监控仪表板
- 读取副本以提高读取性能
- DR(灾难恢复)的多可用区设置
- 升级维护窗口
- 缩放能力(垂直 & 水平)
- EBS 支持的存储(gp2 或 io1)
- 但是不能通过 SSH 直接连接到 RDS 实例
RDS — Storage Auto Scaling
- 可以动态增加 RDS 数据库实例上的存储
- 当 RDS 检测到数据库可用存储空间不足时,它会自动扩展
- 避免手动扩展数据库存储
- 必须设置最大存储阈值(数据库存储的最大限制)
- 在以下情况下自动修改存储:
- 免费存储空间少于分配存储空间的 10%
- 低存储至少持续 5 分钟
- 自上次修改以来已过去 6 小时
- 适用于具有不可预测工作负载的应用程序
- 支持所有 RDS 数据库引擎(MariaDB、MySQL、PostgreSQL、SQL Server、Oracle)
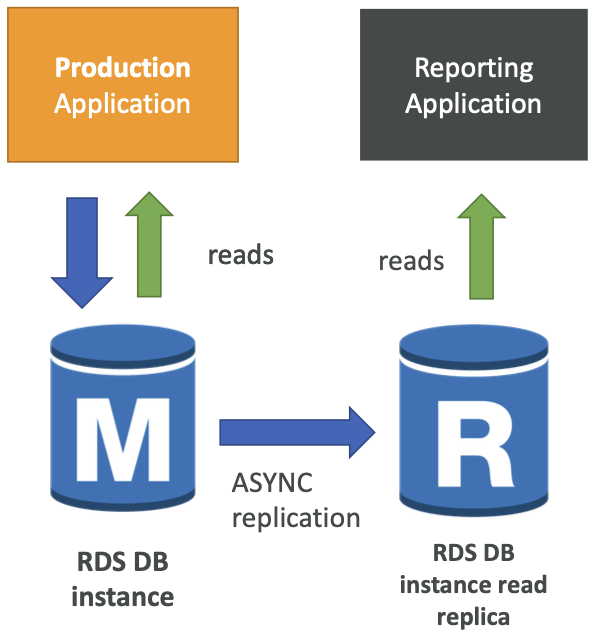
RDS Read Replicas
Read Scalability
- 最多 5 个只读副本
- AZ 内、跨 AZ 或 跨 Region
- 复制是异步的,因此读取是最终一致的
- 副本可以提升到它们自己的数据库
- 应用程序必须修改连接地址字符串以利用只读副本

Use Cases
- 已存在一个正常负载的生产数据库
- 想使用一个报告应用程序来运行一些分析
- 创建一个只读副本以运行新的工作负载
- 希望生产应用不受影响
- 只读副本仅用于 SELECT (=read) 类型的语句(不是 INSERT、UPDATE、DELETE)
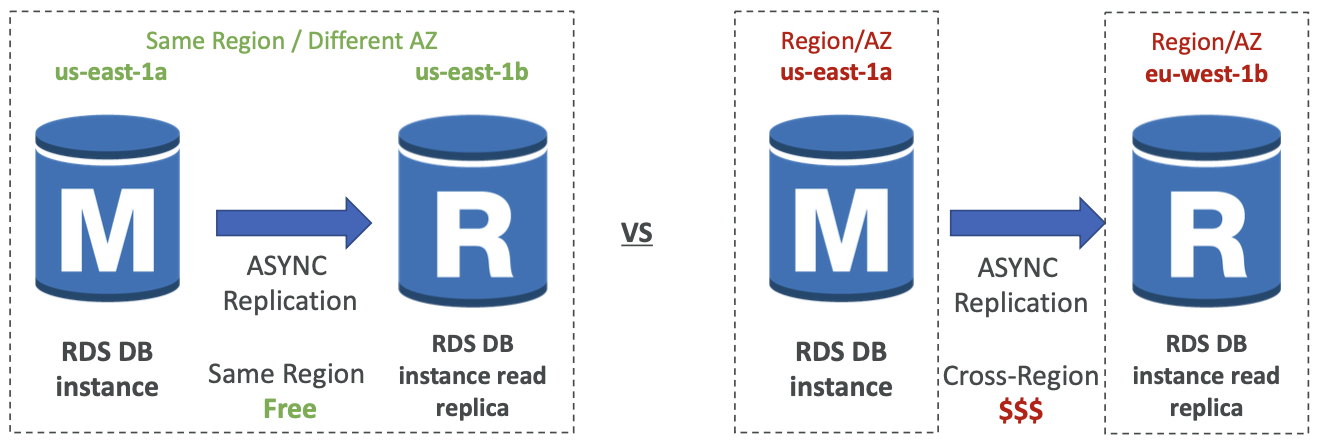
Network Cost
- 在 AWS 中,当数据 跨 AZ 传输 时会产生网络成本
- 对于同一 Regoin 内的 RDS 只读副本,无需支付该费用
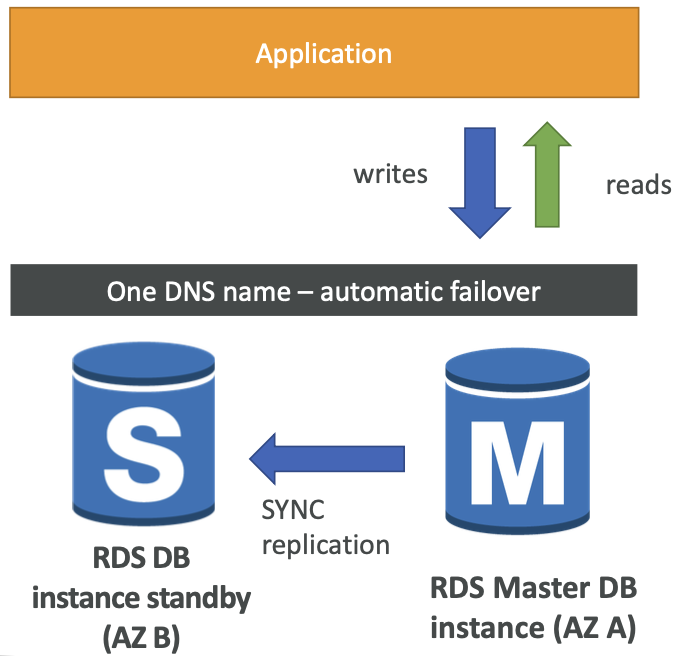
RDS 多可用区(灾难恢复)
- SYNC replication
- 一个 DNS 名称 – 自动将应用故障转移到待机状态
- 提高可用性
- 在 AZ 丢失、网络丢失、实例或存储出现故障时进行故障转移
- 无需手动干预应用程序
- 不用于缩放
- 注意:只读副本需要被设置为用于灾难恢复 (DR) 的多可用区
RDS — 从单可用区到多可用区
- 零停机操作(无需停止数据库)
- 只需点击数据库的“修改”
- 以下情况在内部发生:
- 拍摄快照
- 从新 AZ 中的快照恢复新数据库
- 在两个数据库之间建立同步

RDS Custom
- 通过操作系统和数据库定制管理 Oracle 和 Microsoft SQL Server 数据库
- RDS:自动设置、操作和扩展 AWS 中的数据库
- Custom:访问底层数据库和操作系统,这样就可以:
- 配置设置
- 安装补丁
- 启用原生功能
- 使用 SSH 或 SSM 会话管理器访问底层 EC2 实例
- 停用自动模式以应用程序自定义配置,在这之前最好生成一份数据库快照
- RDS vs RDS custom
- RDS:整个数据库和由AWS管理的操作系统
- RDS Custom:对底层操作系统和数据库的完全管理员访问权限
2. Amazon Aurora
- Aurora 是 AWS 的专有技术(非开源)
- Postgres 和 MySQL 都作为 Aurora DB 得到支持(这意味着您的驱动程序将像 Aurora 是 Postgres 或 MySQL 数据库一样工作)
- Aurora 是“AWS 云优化”并声称 RDS 上的 MySQL 性能提高了 5 倍,RDS 上 Postgres 的性能提高了 3 倍以上
- Aurora 存储以 10GB 的增量自动增长,最高可达 128TB。
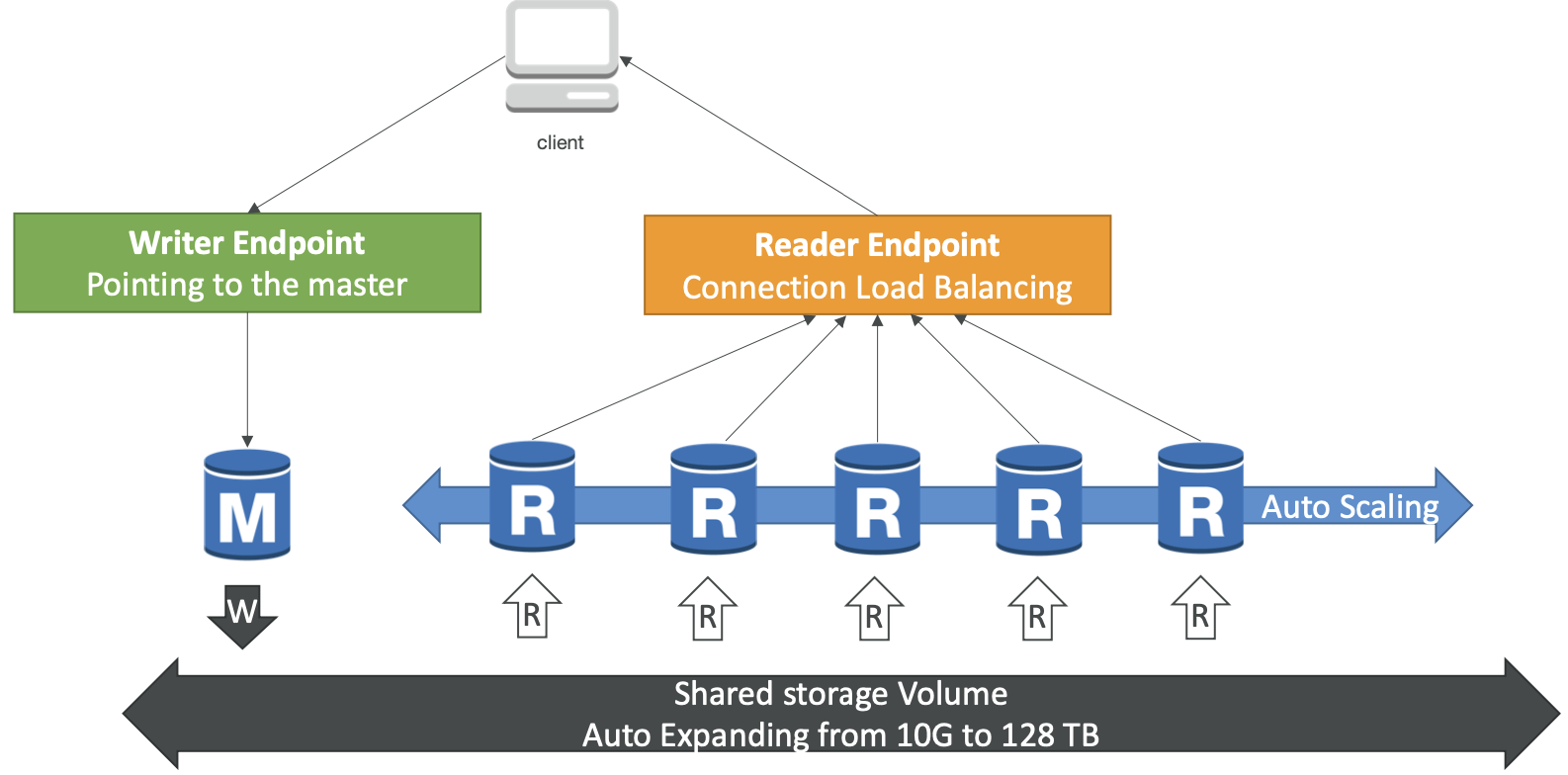
- Aurora 可以有 15 个副本,而 MySQL 有 5 个,并且复制过程更快(低于 10 毫秒的副本滞后)
- Aurora 中的故障转移是即时的。 它是 HA(高可用性)原生的。
- Aurora 的成本高于 RDS(高出 20%)— 但效率更高
Aurora 高可用性和只读扩展
- 跨 3 个可用区的 6 个数据副本:
- 写入所需的 6 个副本中有 4 个副本
- 6 份中的 3 份需要读取
- 通过点对点复制进行自我修复
- 存储跨 100 多个卷条带化
- 一个 Aurora 实例进行写入(主节点)
- 在不到 30 秒内完成主服务器的自动故障转移
- Master + 最多 15 个 Aurora Read Replicas 服务读取
- 支持跨区域复制
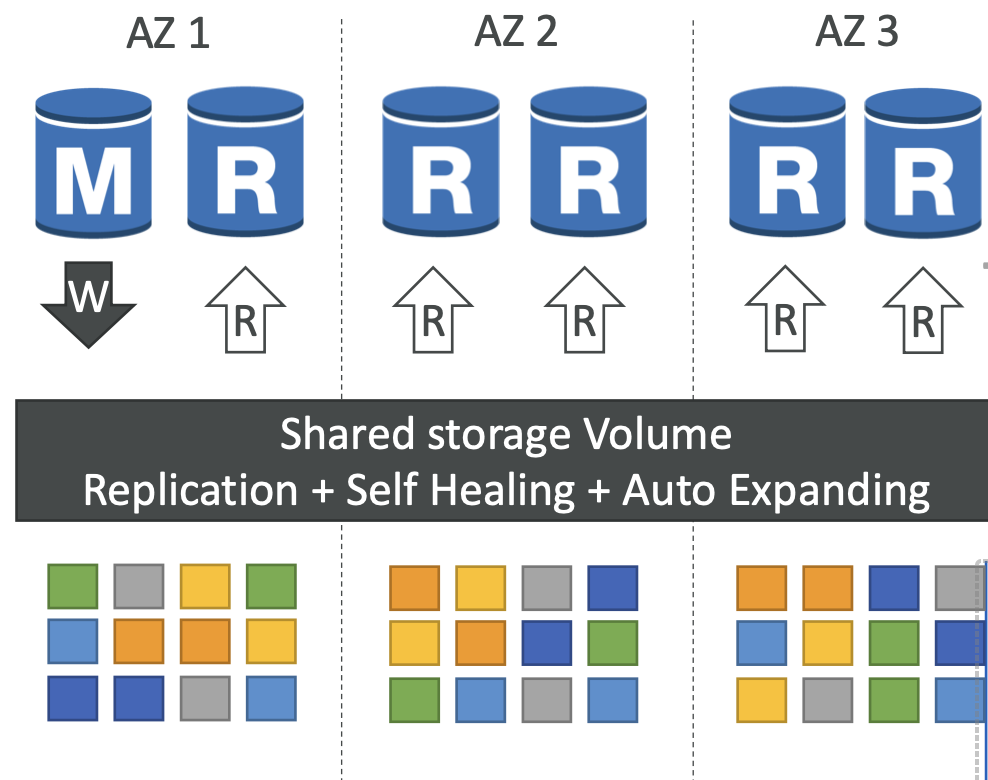
Aurora 数据库集群
Aurora 的特点
- 自动故障转移
- 备份和恢复
- 隔离和安全
- 行业合规
- 一键缩放
- 零停机自动补丁
- 高级监控
- 例行维修
- 回溯:在任何时间点恢复数据而不使用备份
Aurora Replicas - Auto Scaling
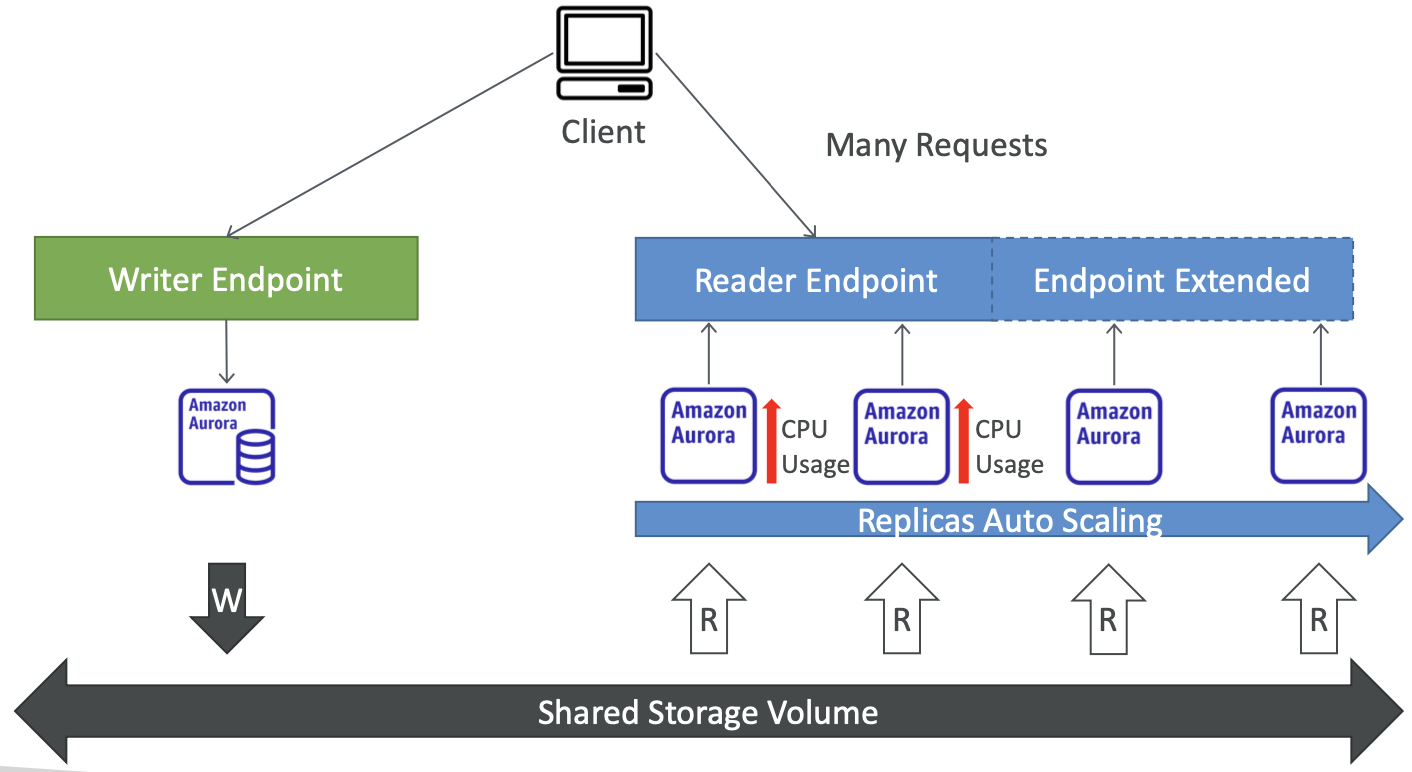
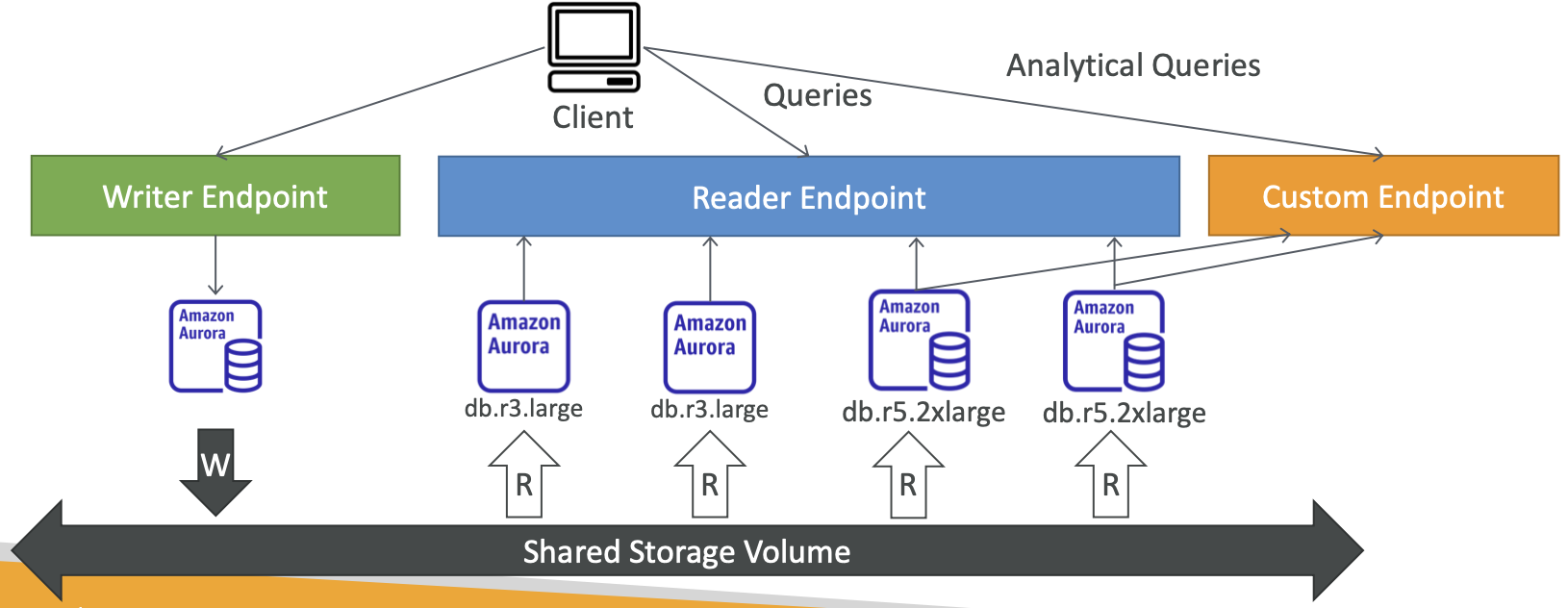
Aurora – 自定义端点
- 将 Aurora 实例的子集定义为自定义端点
- 示例:对特定副本运行分析查询
- Reader Endpoint 通常在定义 Custom Endpoints 后不使用
Aurora Serverless
- 基于实际使用情况的自动数据库实例化和自动缩放
- 适用于不频繁、间歇性或不可预测的工作负载
- 无需容量规划
- 按秒付费,更划算

Aurora Multi-Master
- 如果您希望写入节点 (HA) 立即进行故障转移
- 每个节点都进行 R/W
- 对比将 RR 提升为新的主节点
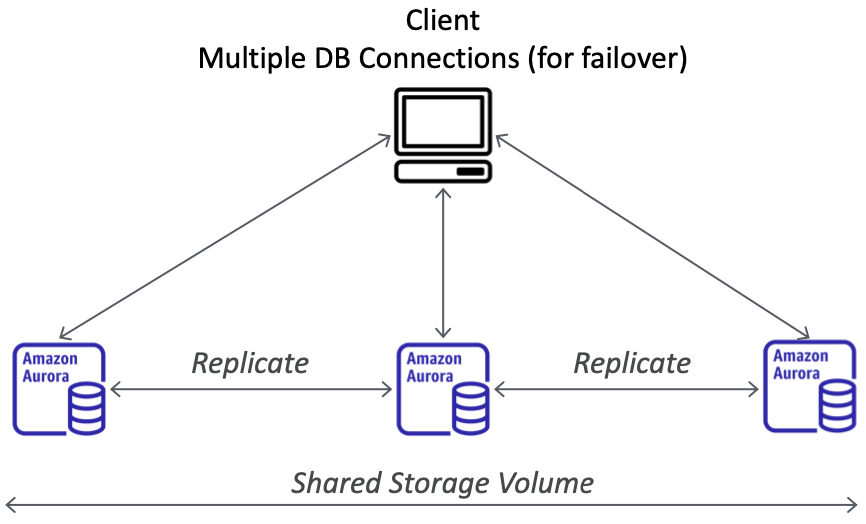
Global Aurora
- Aurora 跨区域只读副本:
- 对灾难恢复有用
- 安装简单
- Aurora 全球数据库(推荐):
- 1 个主要区域(读/写)
- 最多 5 个次要(只读)区域,复制延迟小于 1 秒
- 每个次要区域最多 16 个只读副本
- 有助于减少延迟
- 提升另一个区域(用于灾难恢复)的 RTO 小于 1 分钟
- 典型的跨区域复制不到 1 秒
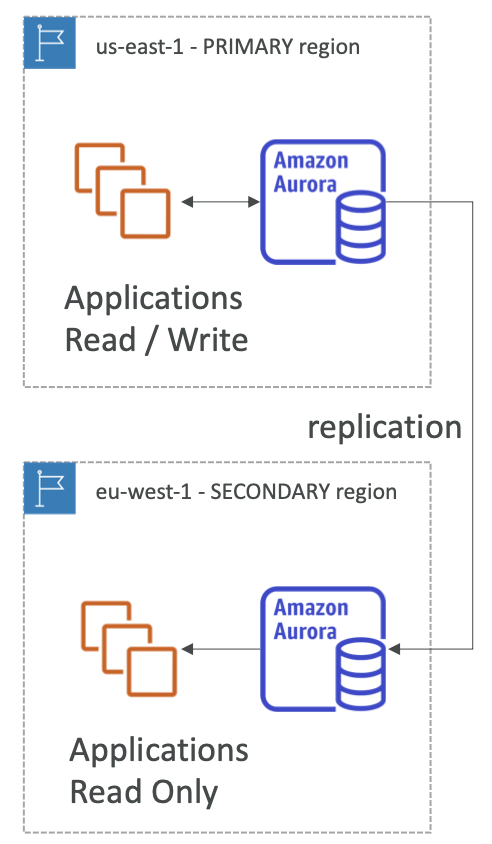
Aurora 机器学习
- 使您能够通过 SQL 将基于 ML 的预测添加到您的应用程序
- Aurora 和 AWS ML 服务之间简单、优化和安全的集成
- 支持的服务
- Amazon SageMaker(与任何 ML 模型一起使用)
- Amazon Comprehend(用于情绪分析)
- 您无需具备机器学习经验
- 用例:欺诈检测、广告定位、情绪分析、产品推荐
3. Backups
RDS 备份
- 自动备份:
- 数据库的每日完整备份(在备份窗口期间)
- RDS 每 5 分钟备份一次事务日志
- => 能够恢复到任何时间点(从最旧的备份到 5 分钟前)
- 1 到 35 天的保留,设置为 0 以禁用自动备份
- 手动数据库快照
- 由用户手动触发
- 备份保留时间不限
- 技巧:在停止的RDS 数据库中,您仍然需要为存储付费。 如果您打算长时间停止它,您应该改为快照和恢复
Aurora 备份
- 自动备份
- 1 到 35 天(无法禁用)
- 该时间范围内的时间点恢复
- 手动数据库快照
- 由用户手动触发
- 备份保留时间不限
RDS 和 Aurora 还原选项
- 还原 RDS/Aurora 备份或快照创建新数据库
- 从 S3 恢复 MySQL RDS 数据库
- 创建本地数据库的备份
- 将其存储在 Amazon S3(对象存储)上
- 将备份文件还原到运行 MySQL 的新 RDS 实例上
- 从 S3 恢复 MySQL Aurora 集群
- 使用 Percona XtraBackup 创建本地数据库的备份
- 将备份文件存储在 Amazon S3 上
- 将备份文件还原到运行 MySQL 的新 Aurora 集群上
Aurora 数据库克隆
- 从现有数据库集群创建新的 Aurora 数据库集群
- 比快照和恢复更快
- 新数据库集群使用与原始集群相同的集群卷和数据,但会在进行数据更新时发生变化
- 非常快速且具有成本效益
- 有助于在不影响生产数据库的情况下从“生产”数据库创建“暂存”数据库
4. RDS & Aurora Security
- 静态加密:
- 使用 AWS KMS 的数据库主副本加密 – 必须定义为启动时间
- 如果主节点未加密,则只读副本无法加密
- 要加密未加密的数据库,请查看数据库快照并恢复为加密状态
- 动态加密:默认情况下 TLS 就绪,使用 AWSTLS 根证书客户端
- IAM 身份验证:连接到您的数据库的 IAM 角色(而不是用户名/密码)
- 安全组:控制对您的 RDS / Aurora 数据库的网络访问
- 除 RDS Custom 外,没有可用的 SSH
- 可以启用审计日志并将其发送到 CloudWatch Logs 以便保留更长时间
5. Amazon RDS Proxy
- RDS 的完全管理的数据库代理
- 允许应用程序汇总并共享与数据库建立的 DB 连接
- 通过减少数据库资源的压力(例如CPU,RAM)来提高数据库效率,并最大程度地减少开放连接(以及超时)
- 无服务器,自动化,高度可用(多功率)
- 将 RDS 和 Aurora 故障转移时间减少了66%
- 支持RDS(MySQL,PostgreSQL,Mariadb)和Aurora(MySQL,PostgreSQL)
- 大多数应用程序无需更改代码
- 对 DB 执行 IAM 身份验证,并在 AWS Secrets Manager 中安全存储凭据
- RDS 代理永远无法公开访问(必须从VPC访问)

6. Amazon Elasticache
概述
- RDS 的方式是获得托管的关系数据库…
- Elasticache 是要管理 Redis 或 Memcach
- 缓存是内存数据库,具有非常高的性能,低延迟
- 有助于减少数据库的负载,以读取密集工作负载
- 有助于使您的申请无状态
- AWS 负责 OS 维护 /修补,优化,设置,配置,监视,故障恢复和备份
- 使用 Elasticache 涉及重型应用程序代码更改
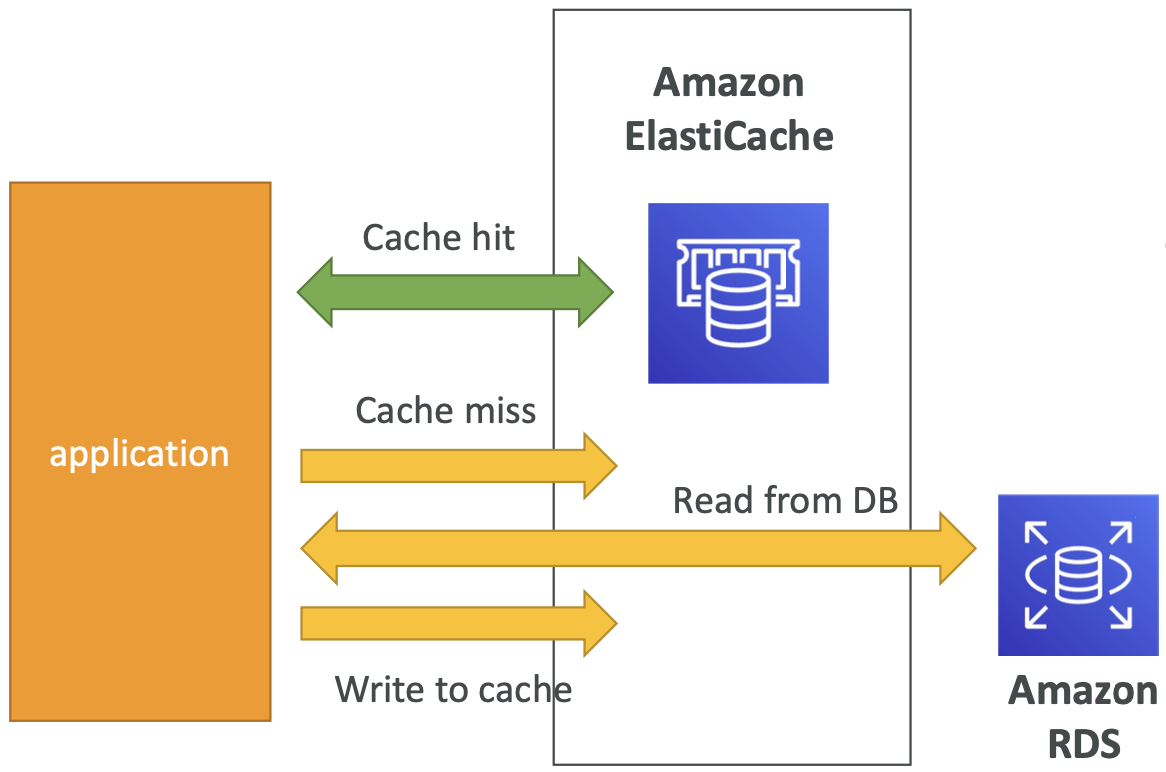
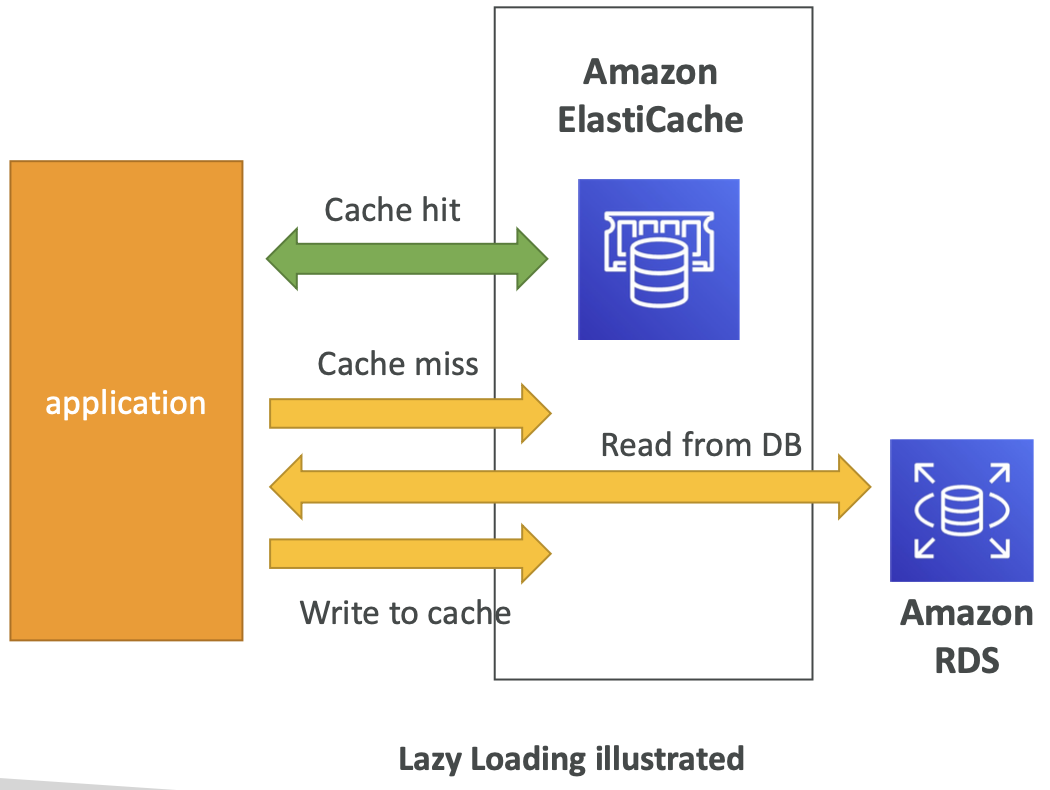
ElastiCache 解决方案架构 - DB缓存
- 应用程序查询 Elasticache(如果不可用的话)从 RDS 获取并存储在 Elasticache 中。
- 有助于减轻 RDS 的负载
- 缓存必须具有无效策略,以确保其中仅使用最新数据。
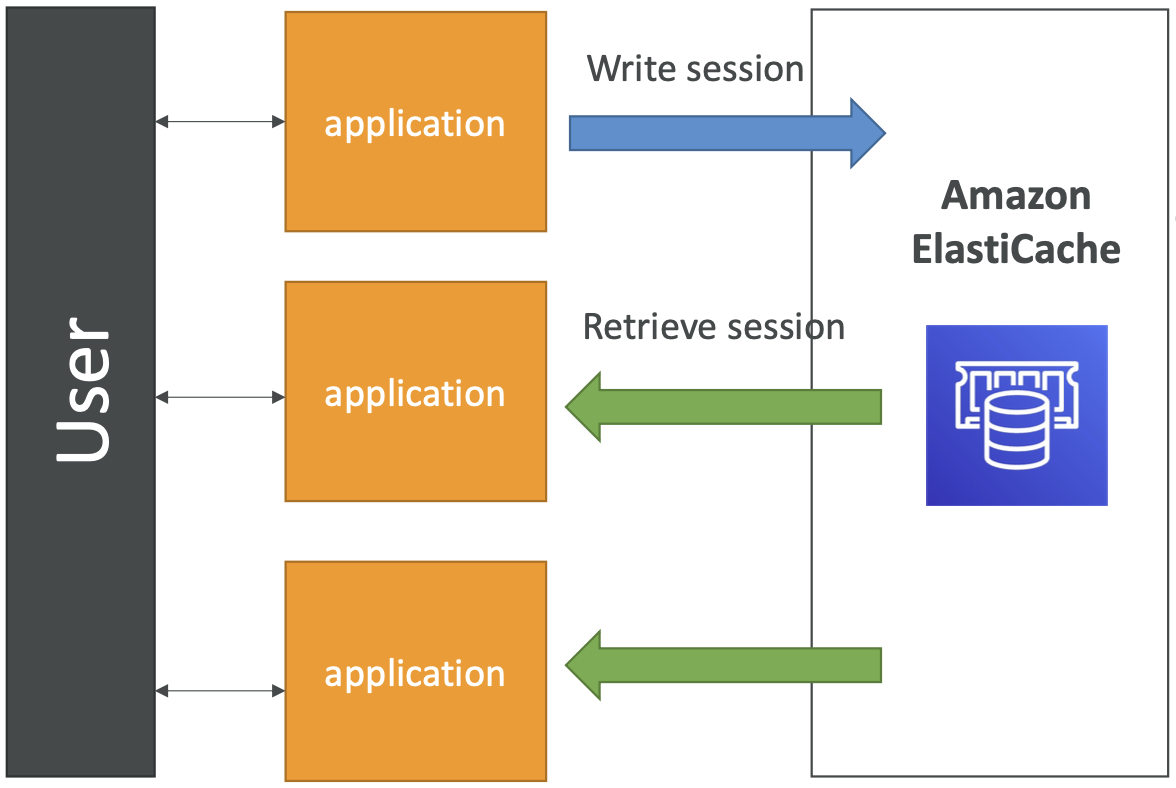
ElastiCache 解决方案架构 - 用户会话存储
- 用户登录到任何应用程序
- 应用程序将会话数据写入 Elasticache
- 用户击中了我们应用程序的另一个实例
- 实例检索数据,用户已经登录
ElastiCache - Redis vs Memcach
| Redis | MemCached |
| - 自动禁用的多 AZ - 阅读副本以扩展读取并具有高可用性 - 使用 AOF 持久性的数据耐用性 - 备份和还原功能 | - 用于分区数据的多节点(碎片) - 没有高可用性(复制) - 非持久 - 没有备份和还原 - 多线程体系结构 |
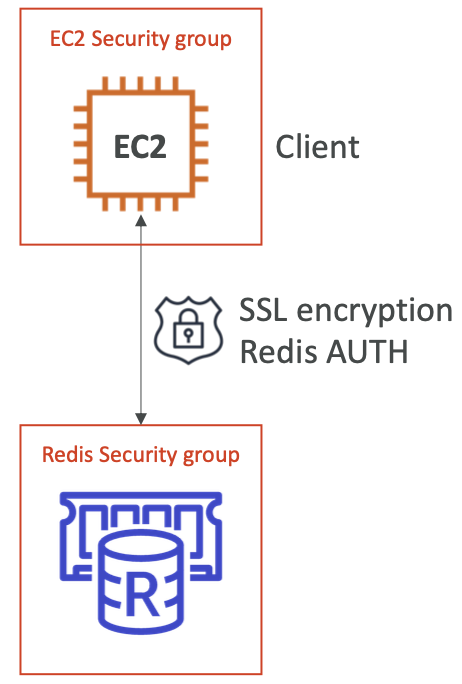
Elasticache - 缓存安全性
- Elasticache 支持 REDIS 的 IAM 身份验证
- IAM 关于 Elasticache 的政策仅用于 AWS API 级安全性
- redis auth
- 创建 REDIS 群集时,您可以设置“密码/令牌”
- 这是您的缓存的额外安全性(在安全组之上)
- 在飞行加密中支持 SSL
- 备忘录
- 支持基于 SASL 的身份验证(高级)
Patterns for ElastiCache
- 懒惰加载:所有读取数据均已缓存,数据可能变为缓存中的陈旧
- 写入:将缓存中的数据添加或更新数据写入DB(没有陈旧数据)
- 会话存储:将临时会话数据存储在缓存中(使用TTL功能)
- Quote:计算机科学中只有两件事:缓存无效和命名事物
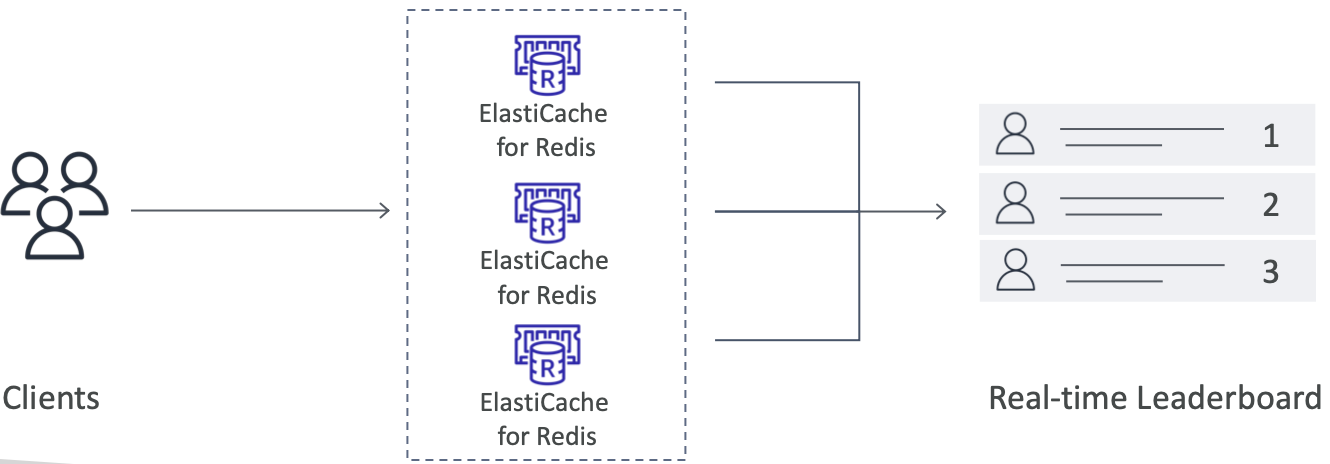
Elasticache - Redis用例
- 游戏排行榜在计算上很复杂
- REDIS 排序设置保证唯一性和元素排序
- 每次添加新元素时,都会实时排名,然后以正确的顺序添加
这篇关于AWS 专题学习 P3 (RDS、Aurora、ElastiCache)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[AWS云]EC2扩容磁盘之linux系统](https://i-blog.csdnimg.cn/direct/fa3a555944b74d2bb500d7a380dd3996.png)
