本文主要是介绍如何通过ISPC使用Xe(核显)进行计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我一直以为 ISPC 的 Xe 是只包含独立显卡的,比如 A770 这些,没想到看了眼文档是可以使用核显的,但只能在 Linux 和 Windows 上,macOS 不行,就想试试看。
写本文是因为 ISPC 已经出现了三四个版本的大改,但是官方文档Intel® ISPC for Xe并未提及这些。不过这篇官方文档依旧可以带来很多帮助。
准备工作
本文使用 Windows 系统进行操作,Linux 操作类似。(实际使用建议使用 Linux,Windows 上毛病比较多)
此外需要注意不能使用 WSL。个人猜测是因为 WSL 无法识别核显型号,因为 lspci的结果中,显卡显示是3D controller,而不是正经 Linux 发行版中的,比如VGA compatible controller(厂商数据也不对)。CUDA 是通过一个库实现的,也就是中继的,但是 Intel 好像没有弄这样的库。
此外,ISPC 最新的 Windows 版本针对我的核显的代码不能用:编译没问题,但是运行不成功,显示版本问题。原因是我使用的 UHD 630 是 Gen 9 的,而目前 Windows 版本只支持 11-13 代或者 Arc 独显。
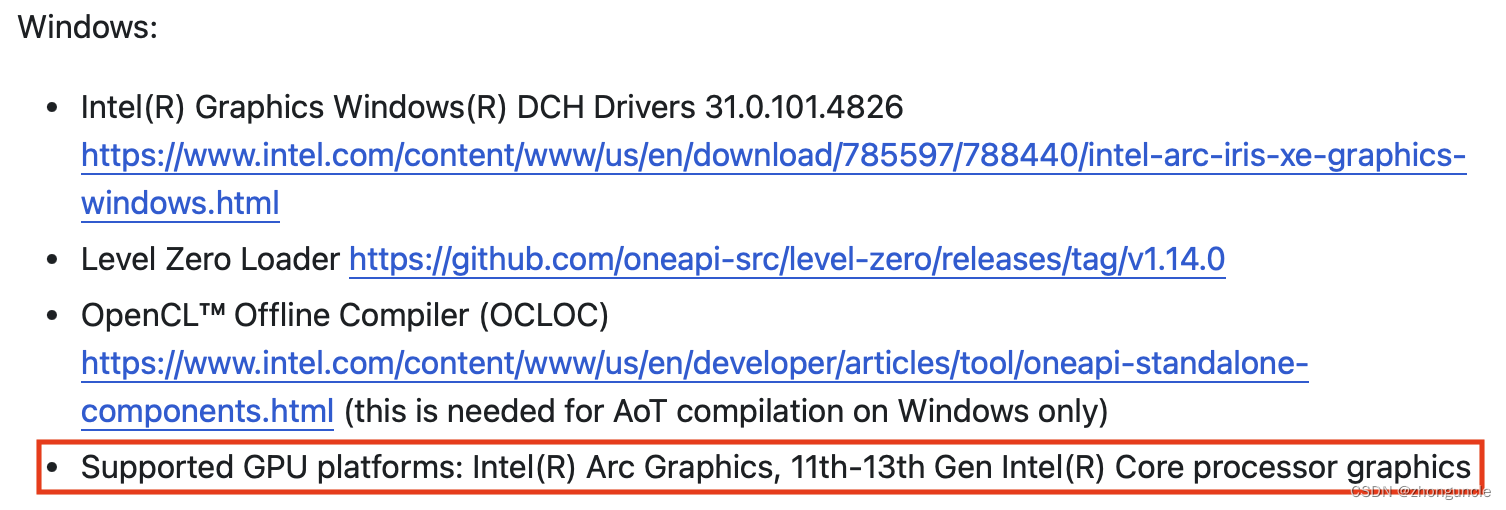
所以如果你和我遇到一样的问题,那么请安装 v1.18.1 或者 v1.18.0 的 ISPC,这样就可以成功运行了。
成功准备好 ISPC 之后,安装 Level Zero Loader。方法很简单,下载level-zero-sdk,之后配置环境变量LEVEL_ZERO_PATH即可。
运行原理
ISPC Runtime 是 Level Zero 的高级化产物(类似汇编语言和高级语言的关系),可以通过 Level Zero 控制 CPU 和 GPU。所以程序是将 ISPC 编译后得到的 ISPCRT objects 交给 ISPC Runtime,由 ISPC Runtime 决定是 CPU 还是 GPU 运行,并进行操作(但这个内容是在 ISPCRT Object 中设置的)。ISPCRT Object 是 SPIR-V 格式的,存放文件后缀为.spv。
如果你熟悉 Java 的话就很好理解,ISPC 就是 javac,ISPC Runtime 就是 Java。
需要注意一点,如果你只需要代码运行在 CPU 上,那么不需要 ispcrt,只需要ispc编译器即可。
示例代码
示例代码是 ISPC 示例中的 Simple。Simple 项目有两个文件:simple.cpp和simple.ispc。
simple.cpp的内容如下:
#include <algorithm>
#include <cmath>
#include <iomanip>
#include <iostream>// ispcrt
#include "ispcrt.hpp"std::ostream &operator<<(std::ostream &os, const ISPCRTDeviceType dt) {switch (dt) {case ISPCRT_DEVICE_TYPE_AUTO:os << "Auto";break;case ISPCRT_DEVICE_TYPE_GPU:os << "GPU";break;case ISPCRT_DEVICE_TYPE_CPU:os << "CPU";break;default:break;}return os;
}struct Parameters {float *vin;float *vout;int count;
};void simple_CPU_validation(std::vector<float> vin, std::vector<float> &vgold, const unsigned int SIZE) {for (unsigned int i = 0; i < SIZE; i++) {float v = vin[i];if (v < 3.)v = v * v;elsev = std::sqrt(v);vgold[i] = v;}
}#define EPSILON 0.01f
bool validate_result(std::vector<float> vout, std::vector<float> vgold, const unsigned int SIZE) {bool bValid = true;for (unsigned int i = 0; i < SIZE; i++) {float delta = (float)fabs(vgold[i] - vout[i]);if (delta > EPSILON) {std::cout << "Validation failed on i=" << i << ": vout[i] = " << vout[i] << ", but " << vgold[i]<< " was expected\n";bValid = false;}}return bValid;
}static int run(const ISPCRTDeviceType device_type, const unsigned int SIZE) {std::vector<float> vin(SIZE);std::vector<float> vout(SIZE);std::vector<float> vgold(SIZE);ispcrt::Device device(device_type);// Setup input arrayispcrt::Array<float> vin_dev(device, vin);// Setup output arrayispcrt::Array<float> vout_dev(device, vout);// Setup parameters structureParameters p;p.vin = vin_dev.devicePtr();p.vout = vout_dev.devicePtr();p.count = SIZE;auto p_dev = ispcrt::Array<Parameters>(device, p);// Create module and kernel to executeispcrt::Module module(device, "xe_simple");ispcrt::Kernel kernel(device, module, "simple_ispc");// Create task queue and execute kernelispcrt::TaskQueue queue(device);std::generate(vin.begin(), vin.end(), [i = 0]() mutable { return i++; });// Calculate gold resultsimple_CPU_validation(vin, vgold, SIZE);// ispcrt::Array objects which used as inputs for ISPC kernel should be// explicitly copied to device from hostqueue.copyToDevice(p_dev);queue.copyToDevice(vin_dev);// Launch the kernel on the device using 1 threadauto res = queue.launch(kernel, p_dev, 1);// ispcrt::Array objects which used as outputs of ISPC kernel should be// explicitly copied to host from devicequeue.copyToHost(vout_dev);// Execute queue and syncqueue.sync();double time = -1.0;if (res.valid()) {time = res.time() * 1e-6;}std::cout << time << std::endl;std::cout << "Executed on: " << device_type << '\n' << std::setprecision(6) << std::fixed;// Check and print resultbool bValid = validate_result(vout, vgold, SIZE);if (bValid) {for (int i = 0; i < SIZE; i++) {std::cout << i << ": simple(" << vin[i] << ") = " << vout[i] << '\n';}return 0;}return -1;
}void usage(const char *p) {std::cout << "Usage:\n";std::cout << p << " --cpu | --gpu | -h\n";
}int main(int argc, char *argv[]) {std::ios_base::fmtflags f(std::cout.flags());constexpr unsigned int SIZE = 16;// Run on CPU by defaultISPCRTDeviceType device_type = ISPCRT_DEVICE_TYPE_AUTO;if (argc > 2 || (argc == 2 && std::string(argv[1]) == "-h")) {usage(argv[0]);return -1;}if (argc == 2) {std::string dev_param = argv[1];if (dev_param == "--cpu") {device_type = ISPCRT_DEVICE_TYPE_CPU;} else if (dev_param == "--gpu") {device_type = ISPCRT_DEVICE_TYPE_GPU;} else {usage(argv[0]);return -1;}}int success = run(device_type, SIZE);std::cout.flags(f);return success;
}
simple.ispc的内容如下:
struct Parameters {float *vin;float *vout;int count;
};task void simple_ispc(void *uniform _p) {Parameters *uniform p = (Parameters * uniform) _p;foreach (index = 0 ... p->count) {// Load the appropriate input value for this program instance.float v = p->vin[index];// Do an arbitrary little computation, but at least make the// computation dependent on the value being processedif (v < 3.)v = v * v;elsev = sqrt(v);// And write the result to the output array.p->vout[index] = v;}
}#include "ispcrt.isph"
DEFINE_CPU_ENTRY_POINT(simple_ispc)
编译流程
编译需要用到 CMake 和 C/C++ 编译器。在 Windows 上就是使用 CMake 和 Visual Studio,Linux 上使用 CMake 和 Clang 或 GCC 就行。
ISPC 分发中包含了一些很有用的 CMake 函数,可以大大降低我们编译所需的工作量。但是需要注意本文中使用 CMake 函数的只能在 v1.18.1 之前的版本使用,后面版本中,相关函数出现了大的变化,但是官方并未对这些函数进行介绍。由于本人也没有 11-13 代核显或者 Intel 独显,所以无法进行尝试,未来如果进行了研究会在这里贴上链接。
建议别想不开非要自己用命令一条条编译。因为各种库都是要手动设置的,Linux 上还好,Windows 上由于库的位置,几乎全是绝对地址,而且
cl.exe对有些库的引用有问题,需要设置的太多,这就导致编译所需的命令都超级长,手动编译确实不太方便。
在项目根目录下新建一个CMakeLists.txt,输入以下内容:
cmake_minimum_required(VERSION 3.14)project(simple)
find_package(ispcrt REQUIRED)
add_executable(host_simple simple.cpp)
add_ispc_kernel(xe_simple simple.ispc "")
target_link_libraries(host_simple PRIVATE ispcrt::ispcrt)
由于计算需要交给 GPU 执行,所以操作 CPU 执行的代码加上host_前缀,交给 GPU 的任务就加上xe_前缀进行区分(Host 和 Device 的概念在 GPU 中还是非常常见的,如果你感兴趣)。
新版本的 ISPC 对新的核显架构使用了新的 CMake 函数,你可以在 ISPC 分发目录中的
lib/ispcrt/ispc.cmake中看到。
然后就可以开始构建编译了。
按照惯例,新建一个build,在其中构建项目:
mkdir build
cd build
cmake ..
Linux
Linux 的话直接用make即可。
Windows
如果是在 Windows 上,这里会出现一个 Visual Studio 项目,我们点击.sln,然后生成解决方案。但是需要注意一个事情:不知道为什么,我在尝试的时候,有些情况下.sqv等一些文件会生成在build目录下,而不是Debug或者Release这些生成目录下(生成设置没有问题)。.sqv是关键,前文提到过这是程序与 ISPCRT 的桥梁。
解决方案有两种:
- 完成将
.sqv后手动拖拽到生成目录下。这个方案对于简单的项目(比如说这个示例项目); - 直接强制将其生成到
.sln所在目录(也就是build目录下)。
如果使用第二种方法,需要在``的中间加入以下语句来设置生成环境(打开项目的时候 Visual Studio 会告诉你发生了修改):
SET( CMAKE_RUNTIME_OUTPUT_DIRECTORY_DEBUG "${OUTPUT_DIRECTORY}")
SET( CMAKE_RUNTIME_OUTPUT_DIRECTORY_RELEASE "${OUTPUT_DIRECTORY}")
SET( CMAKE_LIBRARY_OUTPUT_DIRECTORY_DEBUG "${OUTPUT_DIRECTORY}")
SET( CMAKE_LIBRARY_OUTPUT_DIRECTORY_RELEASE "${OUTPUT_DIRECTORY}")
SET( CMAKE_ARCHIVE_OUTPUT_DIRECTORY_DEBUG "${OUTPUT_DIRECTORY}")
SET( CMAKE_ARCHIVE_OUTPUT_DIRECTORY_RELEASE "${OUTPUT_DIRECTORY}")
这样我们就可以直接运行了(也不用切换工作目录)。
运行
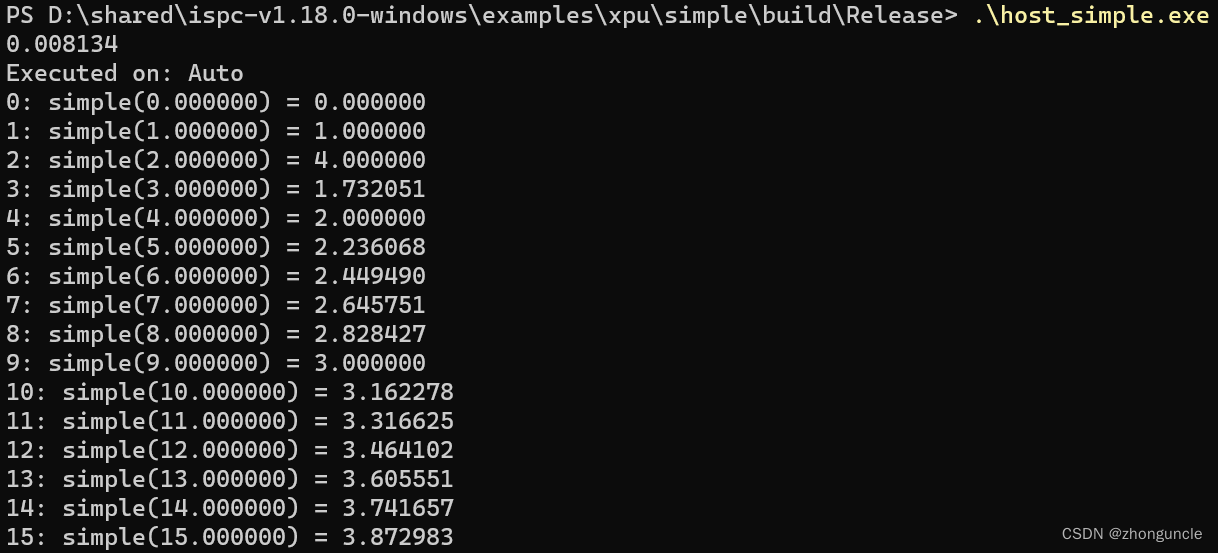
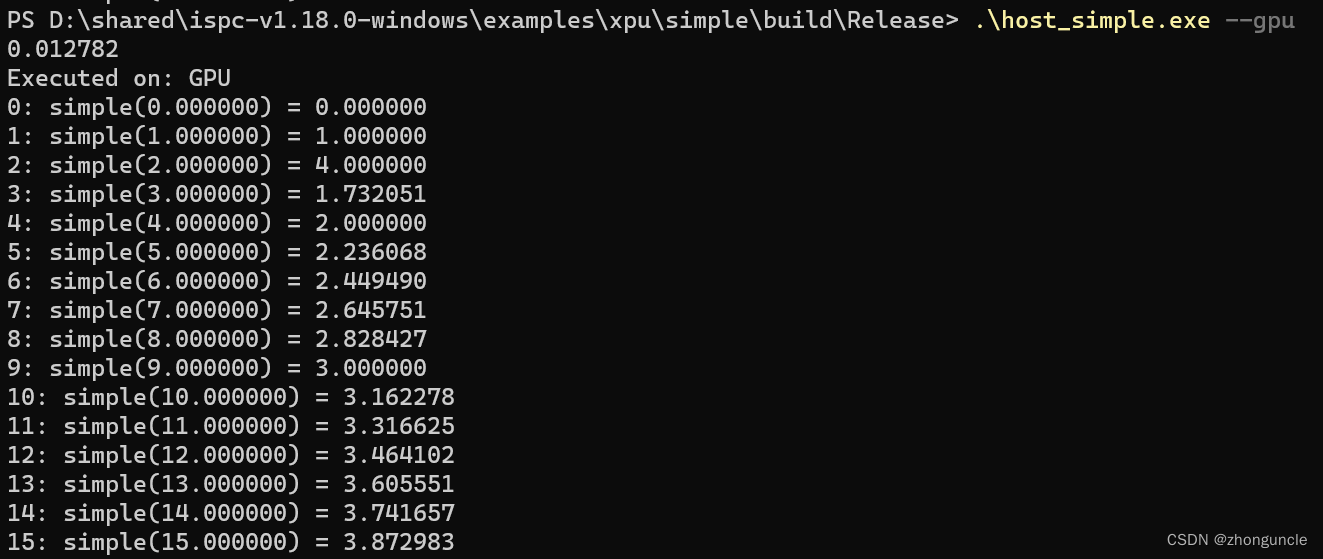
这个程序既可以在 CPU 上 运行,也可以在 GPU 上运行(默认为 CPU)。
默认无选项(CPU):
GPU:
希望能帮到有需要的人~
参考资料
Intel® ISPC for Xe
cmake RUNTIME_OUTPUT_DIRECTORY on Windows - stack overflow
这篇关于如何通过ISPC使用Xe(核显)进行计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





