本文主要是介绍Linux进程【2】进程地址空间(+页表详解哦),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
fork
- 引言(程序地址空间)
- 进程地址空间
- 进程地址空间
- mm_struct
- 虚拟地址到物理地址的转化
- 总结
引言(程序地址空间)
在之前的学习过程中,我们认识了内存与地址,并且了解了在程序地址空间中的基本分区,包括内核空间(用户代码不能访问)、栈、内存映射段(文件映射,动态库,匿名映射)、堆、数据段(静态区)、代码段(常量区):
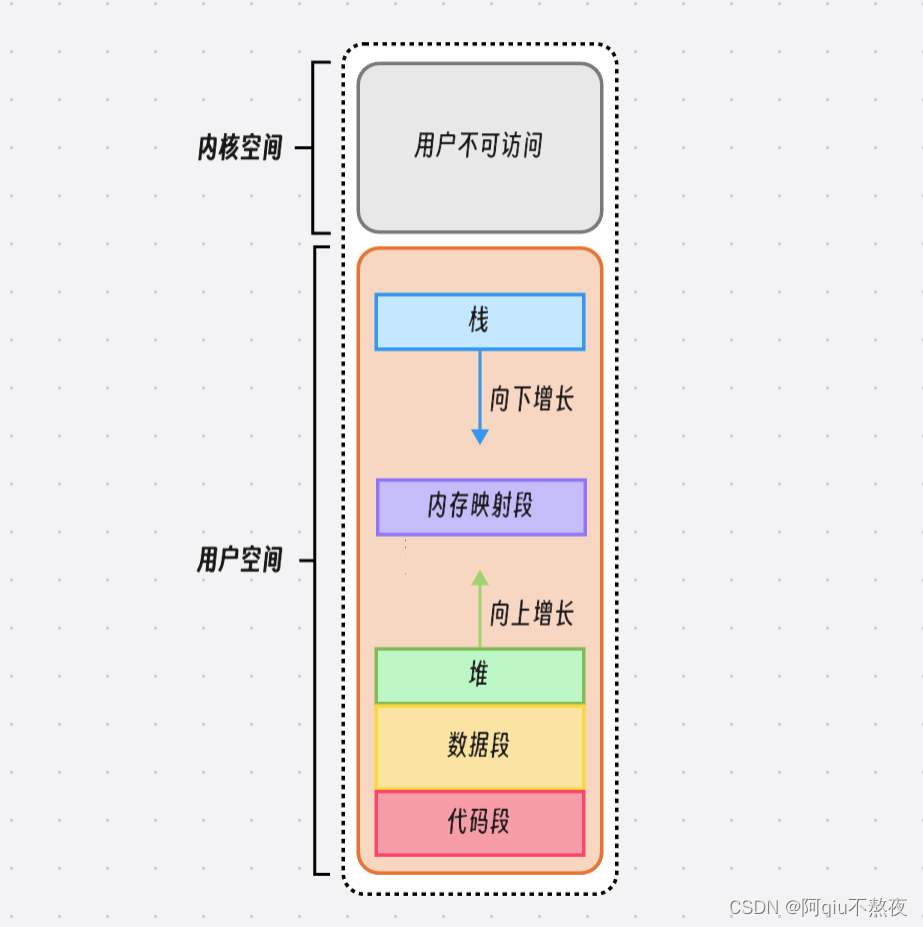
在用户空间中,我们可以通过指针来访问其中的数据:
#include <stdio.h>
#include <stdlib.h>int main()
{int a = 10; //栈int* pb = (int*)malloc(sizeof(int)); //堆static int c = 20; //数据段printf("栈:%p\n堆:%p\n数据段:%p\n", &a, pb, &c);return 0;
}

可以看出,栈区的数据地址远高于堆区的地址,堆区的地址高于数据段的地址,大致的说明了上面图示的结构。
进程地址空间
我们知道,进程可以简单的理解为正在执行的程序。
那么如果说每一个程序都有一套上面的地址空间,当多个进程并发执行的时候,一个地址空间中不就会存储多份不同的数据,出现冲突:
比如我们在fork创建子进程时,会有两个返回值存在同一变量中来区分父子进程(关于fork在后面会详细介绍)。
当我们在父子进程中同时打印返回值ret的地址时,发现他们的地址是相同的:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>int main()
{pid_t ret = 0;ret = fork();if(ret == 0) //子进程{printf("子进程:%p,:%d\n", &ret, ret);}else if(ret > 0) //父进程{printf("父进程:%p,:%d\n", &ret, ret);}return 0;
}

显然,“同一块空间” 中存储了两份不同的数据,这显然是不可能的,两份数据一定是存储在两个不同的物理内存中的。
这其实说明,这里我们打印出的地址,不是真正的物理内存地址,而是虚拟的内存地址。每一个进程在执行时,面对的都是这样的虚拟的地址空间,这就被称为进程地址空间。
进程地址空间
有了上面的认识,所谓的程序地址空间的概念是不准确的,准确的说法应该是进程地址空间。这份空间是虚拟地址,对每一个进程都有一份虚拟地址空间。这份虚拟内存对于每一个进程而言都是相同的,都包含内核空间与用户空间以及更里面的分区。
而上面的例子中的变量名相同,地址相同,但是物理地址不同。说明在两个进程中的 “相同地址” 其实是被页表映射到了不同的物理内存中:
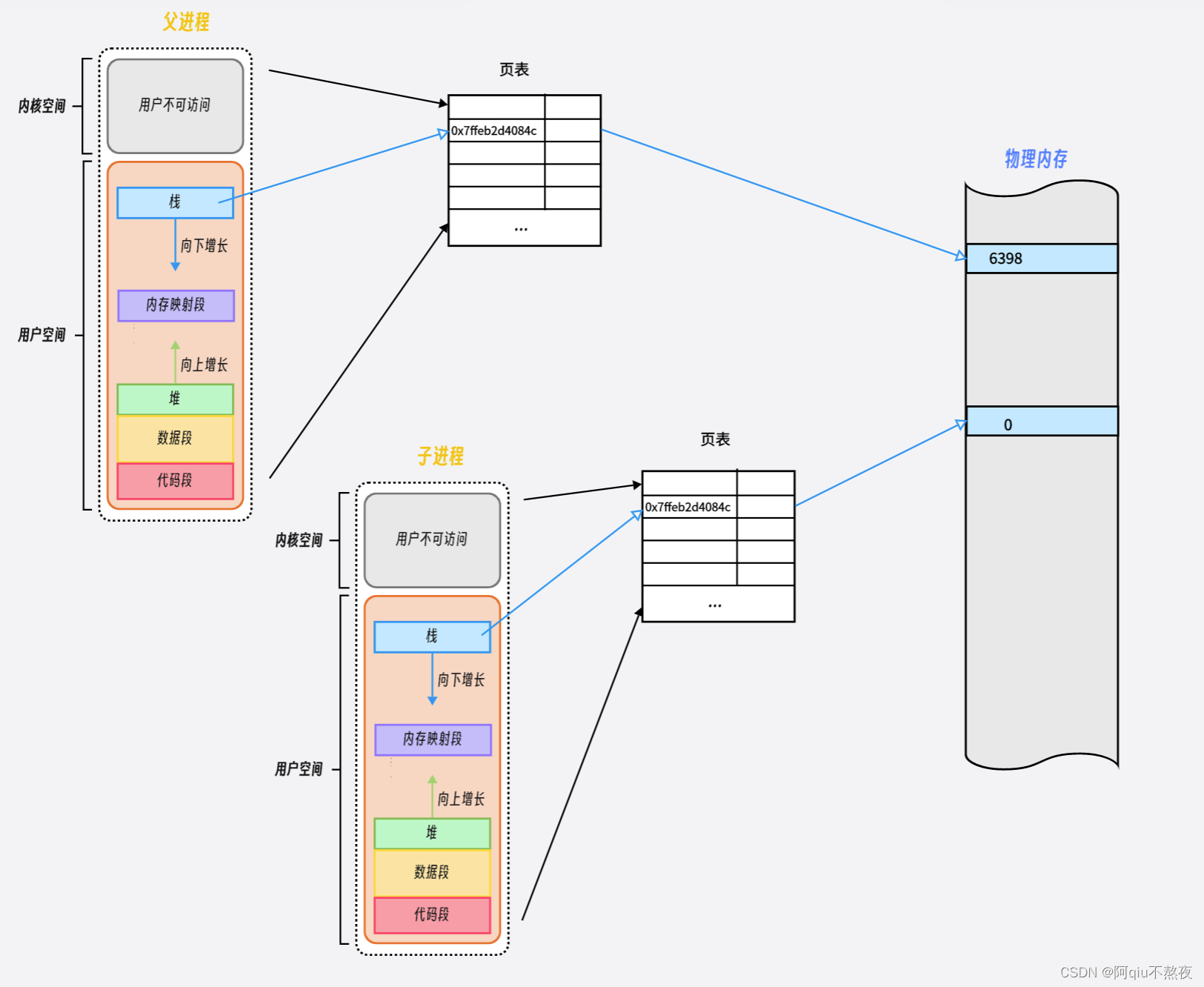
当子进程中需要修改父进程中的一些变量的值时,首先会发生写时拷贝,建立一个新的映射,然后将子进程修改后的数据存储到一块新的物理内存空间中,这些步骤都是由操作系统完成的。
在之后的过程中,父进程或子进程的代码执行可以不受任何的影响,在访问数据时依旧是通过那个虚拟地址来访问的。也就是说,进程的代码与虚拟地址对于这个虚拟地址到底映射到哪块爱物理内存根本就不需要关心。
并且由于多个进程在并发工作时,在物理内存中的内存开辟就不可能是连续开辟的。如果我们的进程直接面对物理内存执行,那么数据结构的存在就没有了意义,数据的访问就会完全乱套。所以让每一个进程都面对一模一样的虚拟内存结构就是非常有必要的了。
mm_struct
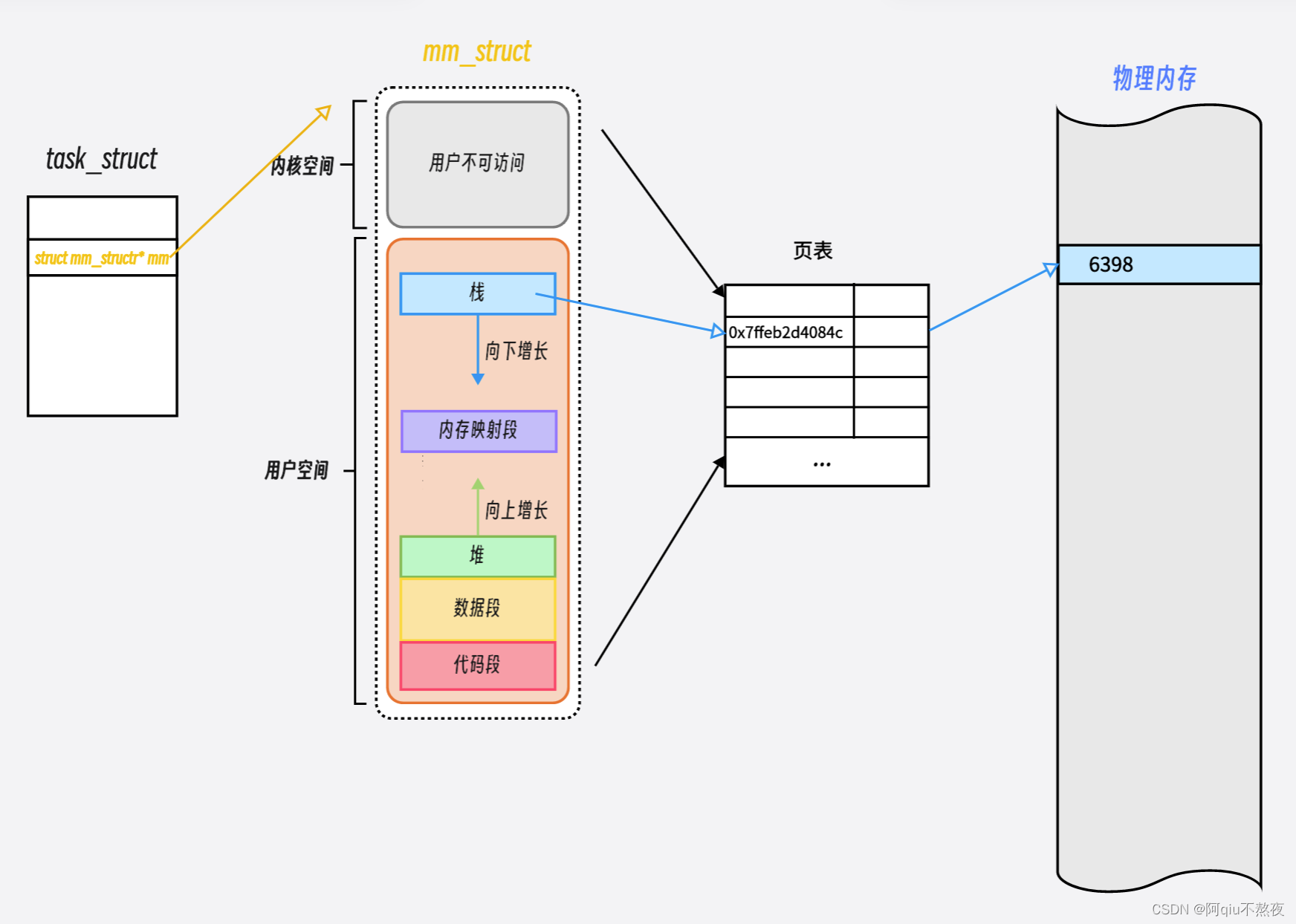
所以进程地址空间的本质是一个进程的可视范围。这个范围之中有着各种区域划分,这些区域是需要被操作系统管理的,所以类似于进程task_struct,需要有一个数据结构来描述进程地址空间,这个数据结构就是mm_strucrt。
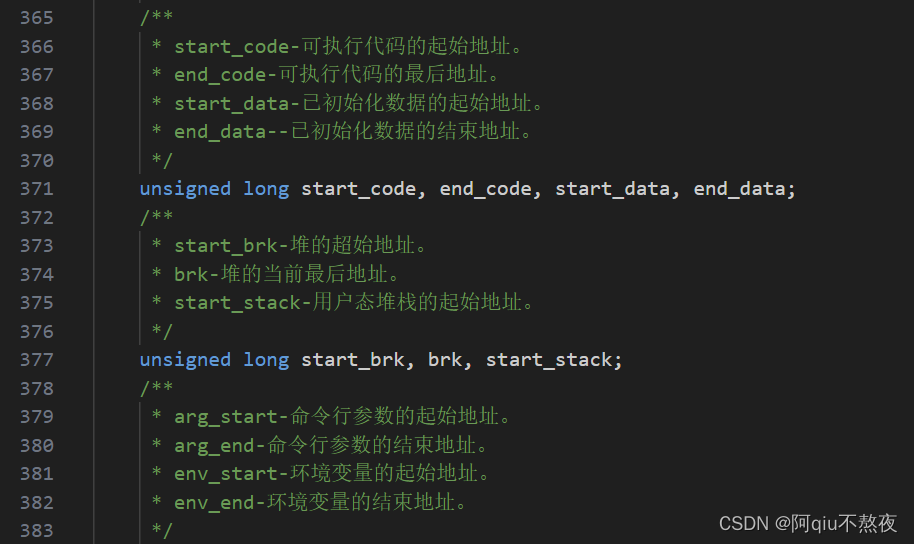
其中空间中区域的划分就是一系列的start与end变量,用来描述一块一块的区域。(我们可以在Linux的源码中找到相关定义):
而从进程task_struct数据结构中,有struct mm_struct*的结构体指针。可以通过这个结构体指针访问到该进程的mm_struct:

虚拟地址到物理地址的转化
通过前面的认识,我们了解了页表是一个虚拟内存到物理内存的映射。
但是,如果页表只是一个单纯的映射表,其中包括一个虚拟地址与它对应的物理地址的话。那么页表将会非常大,我们可以简单计算一下:
以32位为例,进程地址空间共有从0x00000000到0xFFFFFFFF的2^32个地址,也就是说页表中需要2^32项才能描述整个进程地址空间。每一项的大小都是8字节,一共就是8 * 2^32字节的空间,即32G的空间。页表的内容也一定是存储在内存中的,那么整个内存都存不下一个页表的内容,更何况有多个进程多个页表了。
所以页表的结构一定不是这样简单的映射表。
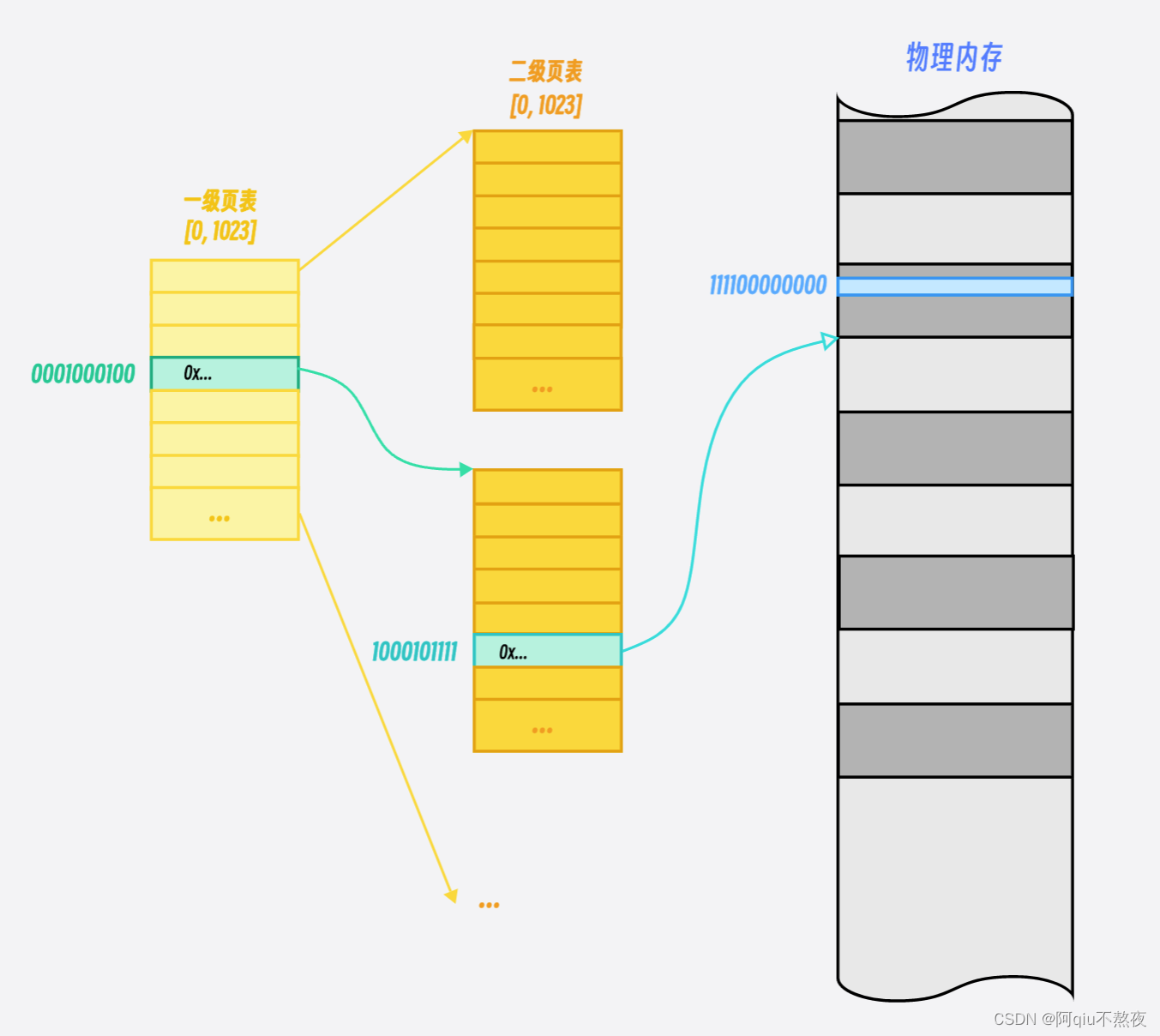
其实页表的结构是分两级的:
第一级页表有2^10项,其中存储的是第二级页表的地址;
第二级页表也有2^10项,其中存储的是物理内存中页框的首地址;
物理内存被分为一个个页框,页框的大小位4KB(2^12字节):

cpu在拿到32位的虚拟地址后,会将这个32位的虚拟地址分为3份,即前10位,中间10位与末尾的12位:

前10位转化成一个10进制数,范围为 [0, 1023]:表示在一级页表中位置的下标,由这个下标中的地址可以访问到一个二级页表;
中间10位也转化成一个10进制数,范围为 [0, 1023]:表示在二级页表中位置的下标,由这个下标中的地址可以访问到一个物理内存中的页框;
末尾的12位转化成一个10进制数,范围为 [0, 2^12-1]:表示这个空间在页框中的偏移量,正好一个页框的大小就是2^12个字节,由这个偏移量就可以在页框中访问到对应的物理地址:
总结
到此,关于进程地址空间的基本知识就介绍完了
相信大家会对进程的内存体系有更好的理解
如果大家认为我对某一部分没有介绍清楚或者某一部分出了问题,欢迎大家在评论区提出
如果本文对你有帮助,希望一键三连哦
希望与大家共同进步哦
这篇关于Linux进程【2】进程地址空间(+页表详解哦)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




