本文主要是介绍【Java】使用jstack、jstat、jmap线上问题排查一例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现象
前阵子线上发布了一些功能,主要是针对客户群做的社群网络,大数据这边针对用户的通讯录、通话记录、设备等信息,计算其对应的社群网络,然后根据社群对应的指标来判断用户的风险情况。当然新老用户的逻辑有所区分,这里就不再深入阐述了。功能上线后,出现了一个比较诡异的事情:系统CPU和内存都飙升,几乎都快把主机撑爆了。
定位最消耗资源的线程
因为发布是在凌晨,使用app的用户还是比较少的,经过沟通,我们建议运维暂时先不下线新功能。给我们几分钟时间定位问题。这时候我们首先想到要查看是哪个线程最消耗资源。(以下示例为事后线下复现,非当时线上真实资源消耗情况)
查看java进程
ps -ef | grep kafka-1.0 | grep -v grep
查看进程中最消耗资源的线程
在我们查看到进程号以后,可以通过top命令查看对应进程中的线程,以及cpu使用情况
top -Hp 100728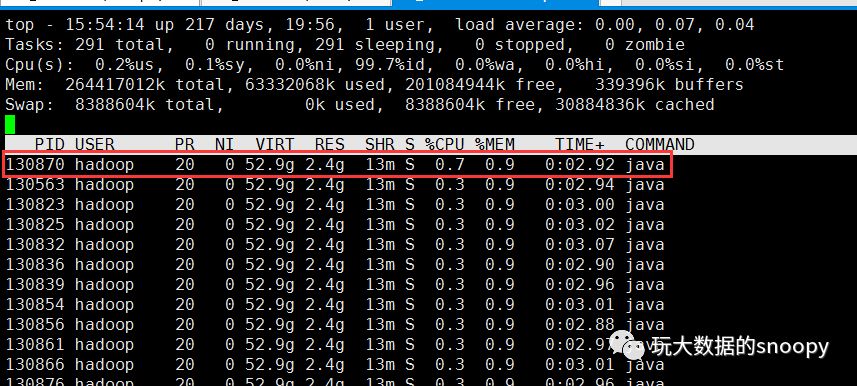
转换为十六进制
printf "%x\n" 130870
可见线程号为:1ff36
接下来我们就需要用到jstack来查看
jstack 100728 > 100728.jstack这样我们就把线上应用的堆栈信息给dump下来了,接下来我们可以看看jstack导出的文件主要有哪些内容,以及线程号为:1ff36的线程当时正在进行什么操作。截止目前我们使用的上面的示例实际并不是当时线上的截图,而是后续为了说明当时的场景做的。当时jstack导出的文件我们保留下来了,对应的最占用CPU资源的前几个线程为GC线程。我们有理由认为是内存被撑爆导致的频繁GC,进而导致CPU居高不下。 查看GC情况
/usr/local/jdk1.8.0_11/bin/jstat -gcutil 100728 1000 100我们发现FGC特别频繁,几秒钟就会进行一次,因为full gc会导致stop the world所以这必然是有问题的,而S0,S1几乎为0,eden区和old区都占满了,即使进行了FGC依然无法回收,由此我们怀疑是在程序运行中产生了大对象无法回收导致频繁FGC:

使用IBM的dump文件分析工具
我们先看下jstack下来的文件内容:
推荐大家一个工具:IBM Thread and Monitor Dump Analyzer for Java(点击下载),真的是线程dump文件的分析利器,看起来非常直观。
使用该工具打开dump文件
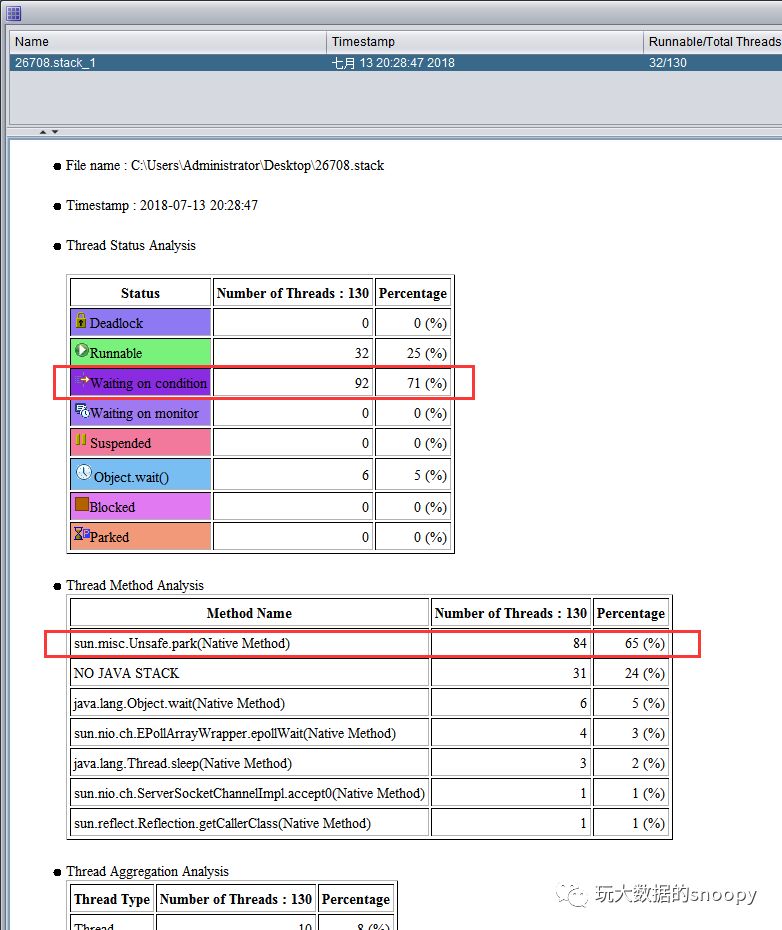
我们发现其中有大量的Waiting on condition等待,它们都是调用的sun.misc.Unsafe.park(Native Method)方法,再看看Thread Details都是hbase连接在获取数据
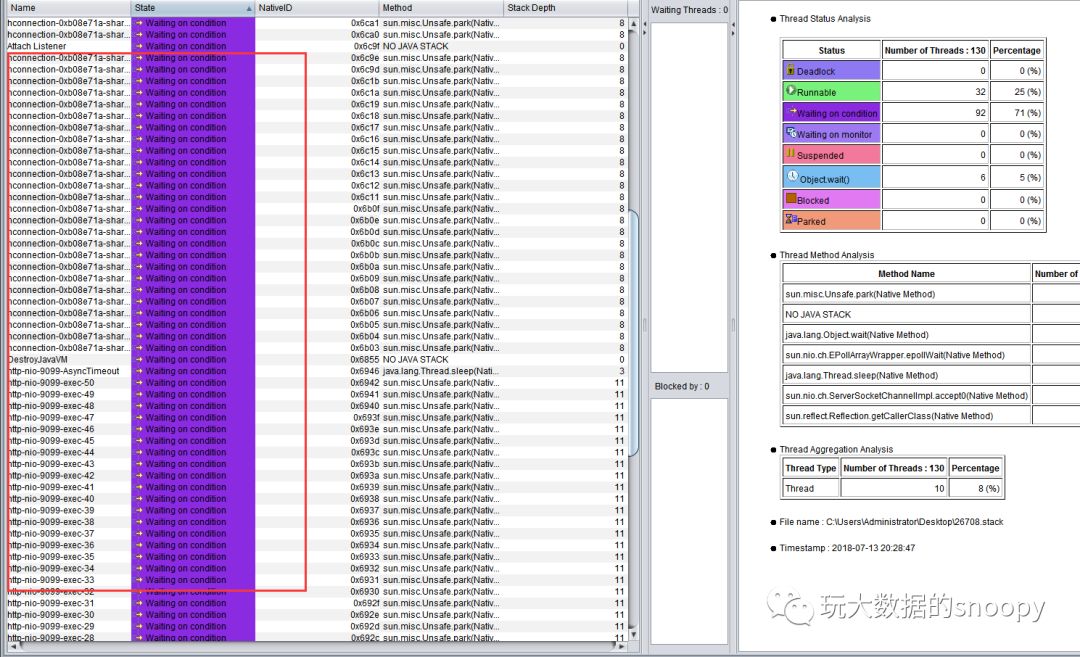
这里很可能是因为获取了大量的数据导致的内存占用居高不下。但是目前也只能提供一个方向性的参考,并没有定位到具体的开发代码,我们看了这么多wait和调用的方法大多也都是定位到了开发框架的源码。我们可以通过搜索对应项目中的包,看看截止当时应用程序都执行了那些代码,如我们项目中所有的代码都是com.maiya开头的,很幸运目前用户流量还不大,并且调用的程序代码并不复杂,我们发现了一个可疑的地方:
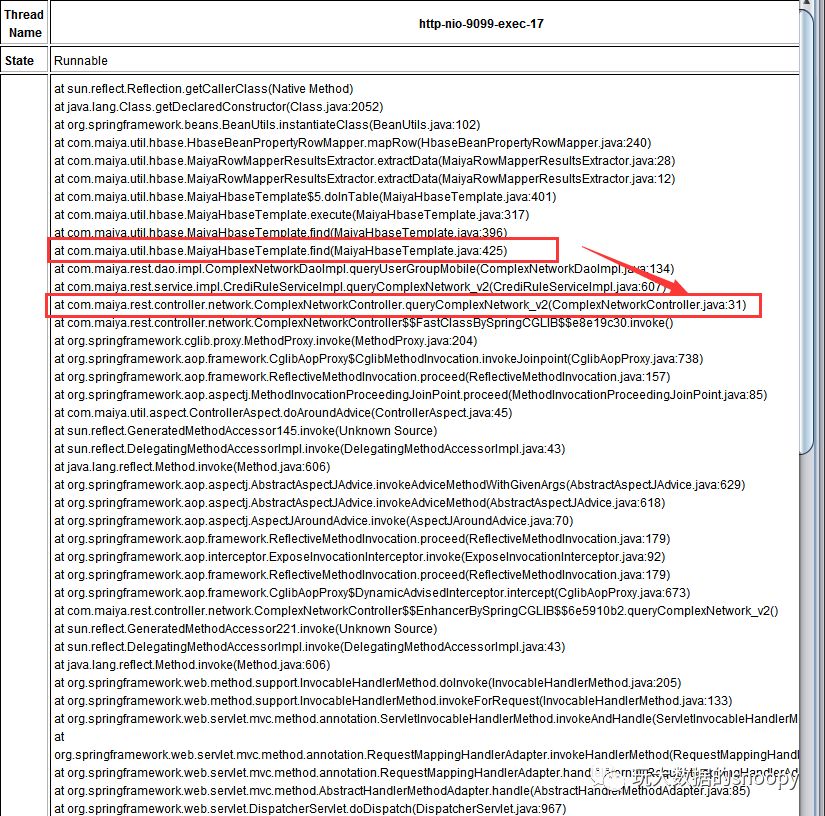
如上图所示,正是本次上线的代码,正在调用hbase的查询接口,那么是否就是hbase表的问题呢,难道如我们上面所猜想的,因为数据量过大导致的出现了大对象?我们count了下对应的表,发现表数据达到了惊人的2亿数据。而且一个用户下有多条重复数据,HBase中为什么会有重复数据呢?原来是因为key设计的问题,导致本该覆盖的记录,并没有覆盖,而是新增了。在数据重复统计多次以后,数据量猛增。最终导致了上面的问题。
至此已经定位出来原因了,程序并不需要进行修改,只要对HBase表进行重构,数据入库逻辑修改即可。数据修正后,程序重启后也正常了。 实际上我们也可以通过jmap查看程序中的class对象占用内存情况。不过dump出来的文件一般都比较大,大家要慎重。
使用java自带的jvisualvm,可以分析heap.hprof文件中的内容:
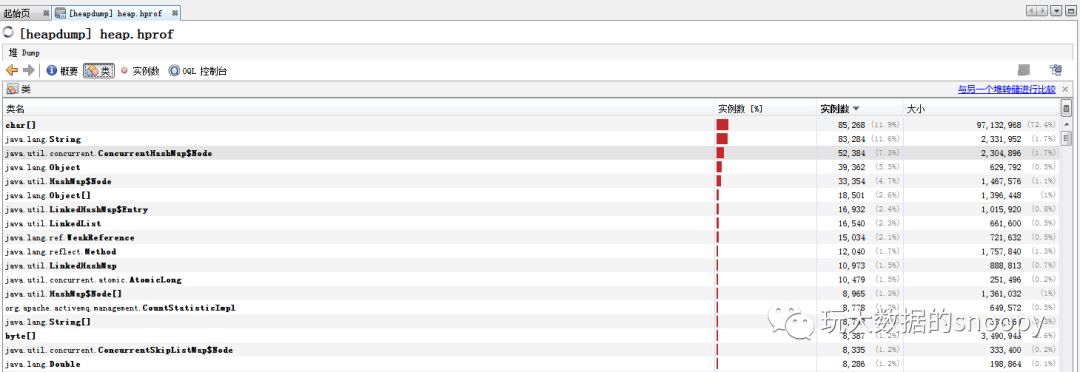
使用jstack只能复现当时线程的方法栈,是一个静态的场景,所以一般要多导出几次,分析对比,如果某个应用程序线程在多次的jstack文件中一直存在,那么可能就需要我们多加关注了。
这篇关于【Java】使用jstack、jstat、jmap线上问题排查一例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





