本文主要是介绍【Databend】分组集:教你如何快速分组汇总,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 分组集定义和数据准备
- group by grouping sets
- group by rollup
- group by cube
- 总结
分组集定义和数据准备
分组集是多个分组的并集,用于在一个查询中,按照不同的分组列对集合进行聚合运算,等价于对单个分组使用"union all",计算多个结果集的并集。
Databend 常见的分组集有三种 grouping sets 、rollup 、cube 。
数据准备:
drop table if exists sales_data;
create table if not exists sales_data (region varchar(255),product varchar(255),sales_amount int
);
insert into sales_data (region, product, sales_amount) values('North', 'WidgetA', 200),('North', 'WidgetB', 300),('South', 'WidgetA', 400),('South', 'WidgetB', 100),('West', 'WidgetA', 300),('West', 'WidgetB', 200);
group by grouping sets
group by grouping sets 是 group by 子句的强大扩展,允许在单个语句中计算多个 group by子句,组集是一组维度列。效果等同于同一结果集中两个或多个 group by 操作的 union all:
- group by grouping sets((a))等同于单分组集操作 group by a。
- group by grouping sets((a),(a,b))等同于 group by a union all group by a,b。
基础语法:
select ...
from ...
[ ... ]
group by grouping sets ( groupset [ , groupset [ , ... ] ] )
[ ... ]
-- groupset ::= { <column_alias> | <position> | <expr> }
其中,column_alias 表示列的别名,position 表示 select 中列的位置,expr 表示当前范围内表上的任何表达式。
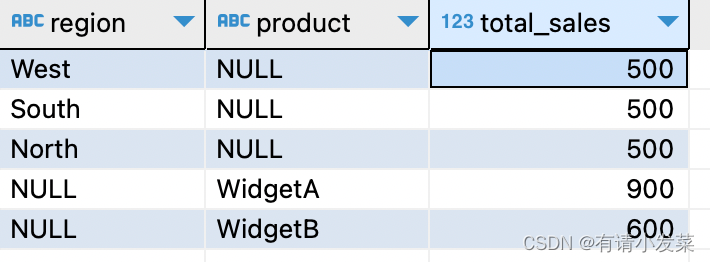
根据准备的数据,需求是统计区域销量和产品销量。
-- 方法一:使用 group by grouping sets 语法
select region, product, sum(sales_amount) as total_sales
from sales_data
group by grouping sets(region, product)
order by region, product;
-- 方法二:使用 union all
select region,null as product, sum(sales_amount) as total_sales
from sales_data
group by region
union all
select null as region, product, sum(sales_amount) as total_sales
from sales_data
group by product;
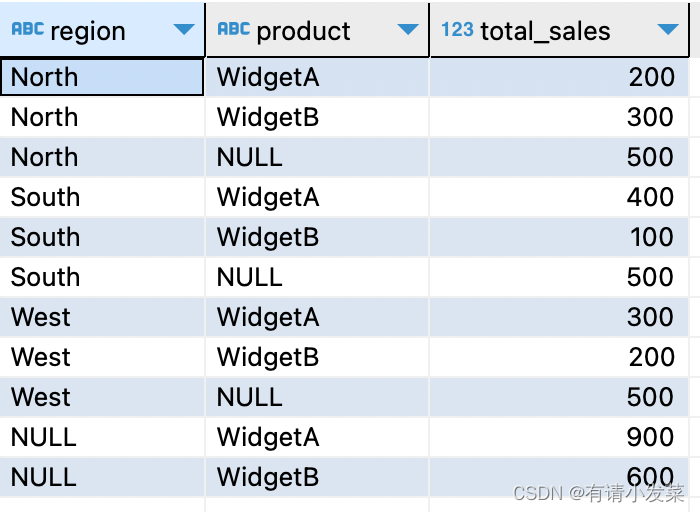
根据准备的数据,需求是在原数据的基础上,统计区域销量和产品销量。
select region, product, sum(sales_amount) as total_sales
from sales_data
group by grouping sets(region, product,(region, product))
order by region, product;
group by rollup
group by rollup 子句会在分组的基础上产生小计行以及总计行,语法如下:
select ...
from ...
[ ... ]
group by rollup ( grouprollup [ , grouprollup [ , ... ] ] )
[ ... ]
-- grouprollup ::= { <column_alias> | <position> | <expr> }
其中,column_alias 表示列的别名,position 表示 select 中列的位置,expr 表示当前范围内表上的任何表达式。
根据准备的数据,需求是在原数据的基础上,统计区域下产品销量小计和总计数据。
-- 方法一:使用 group by rollup 语法
select region, product, sum(sales_amount) as total_sales
from sales_data
group by rollup(region, product)
order by region, product;
-- 方法二:union all
select region, product, sum(sales_amount) as total_sales
from sales_data
group by region,product
union all
select region,null as product, sum(sales_amount) as total_sales
from sales_data
group by region
union all
select null as region, null as product, sum(sales_amount) as total_sales
from sales_data
order by region, product;
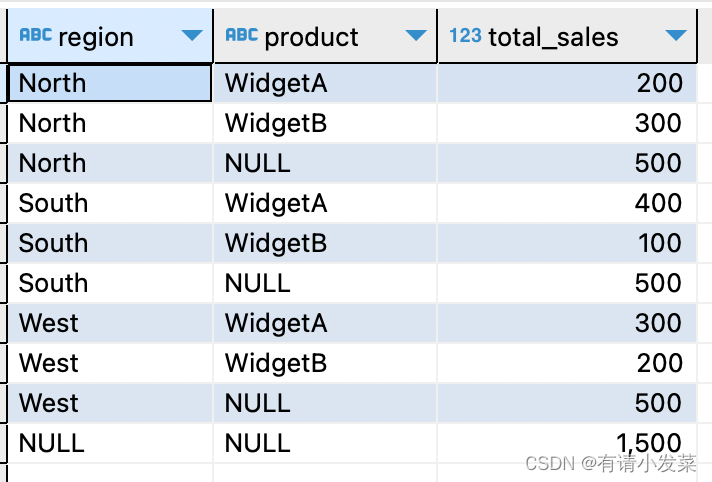
这种汇总方式在分析看板里经常看到,比如 Power BI 和 Tableau 中做表格时,可以选择小计和总计。可以看到使用 group by rollup 子句能快速实现汇总,代码也简洁。
group by cube
group by cube 子句类似 group by rollup 子句,除了生成 group by rollup 子句的所有行外,还会多一些维度,对所有列交叉分组汇总。
select ...
from ...
[ ... ]
group by cube ( groupcube [ , groupcube [ , ... ] ] )
[ ... ]
-- groupcube ::= { <column_alias> | <position> | <expr> }
其中,column_alias 表示列的别名,position 表示 select 中列的位置,expr 表示当前范围内表上的任何表达式。
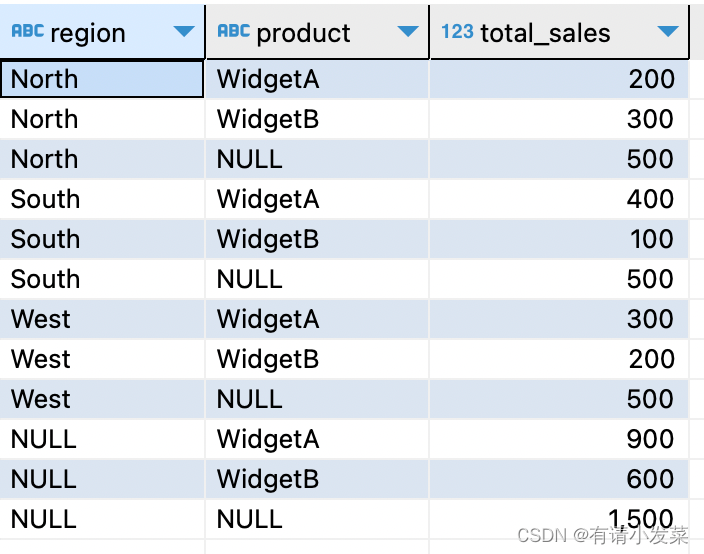
根据准备的数据,需求是在原数据基础上分析所有可能情况的销售汇总。
-- 方法一:使用 group by cube 语法
select region, product, sum(sales_amount) as total_sales
from sales_data
group by cube(region, product)
order by region, product;
-- 方法二:使用 group by grouping sets 子句和 union all 结合
select region, product, sum(sales_amount) as total_sales
from sales_data
group by grouping sets(region, product,(region, product))
union all
select null as region, null as product, sum(sales_amount) as total_sales
from sales_data
order by region, product;
总结
Databend 中 grouping sets、rollup、cube 都是对 group by 的扩展,相对于 union all 来看,代码较简洁,效率也高,可以试着在实际工作中多用用,如果不支持或者理不清,使用 union all 实现的效果也是一样的。
参考资料:
- Databend Group Bys:https://docs.databend.com/guides/query/groupby/
这篇关于【Databend】分组集:教你如何快速分组汇总的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







