本文主要是介绍小小研究一下工作流WorkFlow,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
修房子
在小牧老家农村,小时候总是看到村里有人在修房子。每次看到有人修房子的时候,他就会爬到房子面前的沙粒堆上去,翻找随着沙子一起被挖出来的贝壳。虽然也不知道拿来干嘛,不过总觉得收集贝壳很好玩。
小牧也喜欢看他们修房子。修房子的时候,专业的修房师傅会指导工人如何一步步修房子。第一步,首先要打地基,把地基打的牢牢的。第二步是浇筑地梁。在地基上面浇筑房子的核心骨架。第三步是盖造房子的主体结构,基本是修出了房子的框架外形了。第四步是封顶,考虑水电走向、防水等[1]。
那么,可以看到修房子是有一个标准流程的,工人们会按照流程一步步去修房子,这样才能保证房子能够修的结实可靠。
工作流
上面的例子只是简单地说明了流程。生活中处处存在各种流程,有简单的,有复杂的。比如办事流程,不仅仅需要严格遵守办事流程顺序,还需要保证办事员具有办事权限,特殊情况还需要保密、不可回退流程等。因此过程管理其实是非常重要且广泛存在的。
同样在软件领域,我们依然有很多流程。同样可举个栗子。小牧是搞云计算的,假如用户现在要准备创建一台虚拟机了,那么也存在一系列的流程,比如首先要进行权限验证,金额验证、参数验证,判断是否运行创建虚拟机;允许创建后需要进行存储资源申请、网络资源,还需要考虑物理集群等一系列问题,最后才是真正地创建虚拟机,返回给用户使用。在这个VM创建流程中,任何一步都不能出错,即使出错,每个步骤也有相应的处理方法,比如回滚或者退出报错。
在软件业务中,存在非常多复杂的流程,也叫工作流 。那么如果对于流程,每个都需要程序员去做流程控制、监控等工作,那就会造成冗余的工作。因此大佬们也做出了很多知名的流程控制框架,如JBPM和Activiti等工具。在这里呢,我们也设计一个简单我们自己的流程管理引擎,做一个小玩具。基本的设计思路参考ZStack的FlowChain结构[2],但是便于理解有一些改动。
基本介绍
图1 为小牧画的一个示意图。Task,也就是一个任务。一个流程里面多个任务,比如“修房子”对应打地基、修框架等等多个任务。而操作员,也就是具体执行流程的部分,操作员只有执行了当前手里的任务后,才会接收下一个Task。当然执行可以多线程多操作员一起执行,但是这里我们简化问题,设计为只有一个操作员,单条流水线线性执行Task。
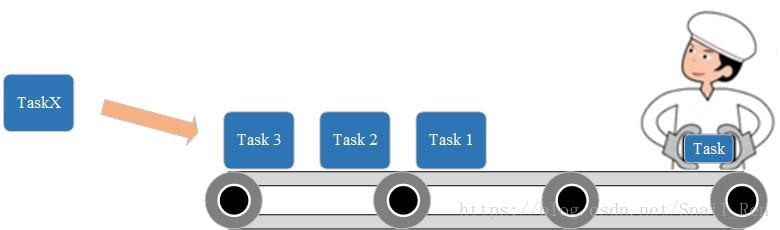
图1 工作流示意图
从图中可以看出,这个流程中有两个重要的组成部分。
- 任务Task,包含任务的运行信息,具体该task的运行方法
- 传输带,用于存放需要执行的task序列
- 操作员,运行task,根据task中的信息进行处理
因此如果我们要设计实现工作流引擎的话,首先是需要对这三个基本的组件进行设计。接下来分别介绍。
任务Task
Task为具体的一个工作步骤。要描述这个步骤,我们有几个需要考虑的点。
最基本的是需要知道这个任务要执行什么。因此我们可以定义一个run()方法。
当任务运行失败怎么办?因此我们要定义一下运行失败的处理方式,是否回滚rollback,以及rollback的具体操作。
因此我们更希望控制Task的具体操作,因此设计一个Task接口。
public interface Task{void run(Map data); //任务的运行操作void rollback(Map data); //任务的回滚操作
}
run函数为任务运行的具体执行流程。rollback为任务回退的时候的运行流程。有了这两个操作接口,那么操作员在拿到任务之后,就能去操作了。
操作员
操作员具体执行任务,根据任务设计好的run和rollback方法来执行。除了直接执行任务的功能外,操作员还需要从流水线上取出任务。因此操作员的描述如下:
public interface TaskOperator这篇关于小小研究一下工作流WorkFlow的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





