本文主要是介绍【PaperReading】3. PTP,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| Category | Content |
|---|---|
| 论文题目 | Position-guided Text Prompt for Vision-Language Pre-training Code: ptp |
| 作者 | Alex Jinpeng Wang (Sea AI Lab), Pan Zhou (Sea AI Lab), Mike Zheng Shou (Show Lab, National University of Singapore), Shuicheng Yan (Sea AI Lab) 另一篇论文:All-in-one 作者主页:https://github.com/FingerRec 参与其他:EditAnything 、Image2Paragraph |
| 发表年份 | 2023 |
| 摘要 | 提出了一种名为Position-guided Text Prompt (PTP)的新方法,以增强视觉语言预训练(VLP)模型在视觉定位方面的能力。PTP通过将图像分割成N×N块并通过VLP中广泛使用的对象检测器识别每个块中的对象,然后将视觉定位任务转化为填空问题。这种机制提高了VLP模型的视觉定位能力,从而更好地处理各种下游任务。通过将PTP引入多个先进的VLP框架中,我们观察到在代表性的跨模态学习模型架构和多个基准测试中都取得了显著的改进。 |
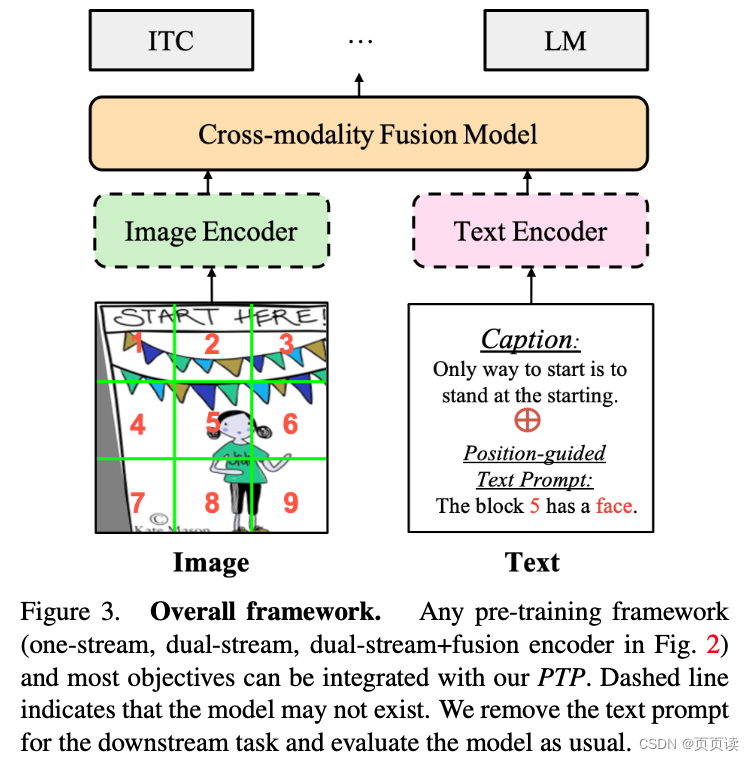
| 主要内容 | 为了增强VLP模型在跨模态学习中的视觉定位能力,我们提出了PTP。PTP与传统的视觉语言对齐方法不同,它将对象特征和边界框作为输入来学习对象与相关文本之间的对齐。PTP包括两个步骤: 1) 块标记生成,将输入图像划分为多个块,并识别每个块中的对象; 2) 文本提示生成,根据第一步中的对象位置信息将视觉定位任务转化为填空问题。 将PTP集成到主流VLP框架中,包括PTP-ViLT、PTP-CLIP和PTP-BLIP。 |
| 实验 | 对PTP进行了多项下游任务的实证评估,并进行了全面研究。在图像-文本检索、图像字幕、视觉问答和视觉推理等任务中,PTP均取得了显著的改善。例如,PTP在MSCOCO数据集的图像-文本检索任务中,相对于ViLT基线,平均回忆率提高了5.3%,并且在类似的框架和数据量下取得了与ALBEF接近的结果。此外,我们还探讨了PTP作为一个新的预文本任务的效果,并发现它在所有任务中都优于基线模型。 |
| 结论 | 通过在多种VLP模型架构下的实验结果表明,PTP有效地提高了模型在各种视觉语言任务中的表现。特别是在图像字幕和视觉问答任务中,PTP的表现优于大多数先进的方法。这些结果证明了PTP在提高视觉语言模型的视觉定位能力方面的有效性和普适性。 |
| 阅读心得 |
这篇论文主要是提出了一种提高预训练性能的prompt方法,这种方法是: 先将图片分块,上图所示,对每一块给出一个结论格式为:The block N has a C. 就是借助于检测模型和现有的caption模型对各个block进行简单的caption并生成这种固定格式的 prompt,帮助模型生成完备准确的描述,这种方法尤其对提高方位相关的描述有用。 注意⚠️这种方法只是用来做预训练,在下游任务或者推理阶段会去掉物体检测模型。 |
这篇关于【PaperReading】3. PTP的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!